Dolt roadmap retrospective

A few months ago I got interviewed by a substack on open source development about Dolt. One of the questions I was glad to answer was what motivates me to contribute to Dolt. Well there's the money, obviously. But more than that, it's being part of a culture that ships.

At DoltHub, we ship major new features every month, and a stream of smaller improvements and bugfixes on a continual basis. We ship so often, in fact, that it can be hard to keep track of what we've accomplished and what we're going to do next. This blog post is an attempt to pause and take stock of how far the product has come in the last couple years, and reflect on where we're going next.
Product planning at DoltHub
When we interview candidates, there's always a period when we flip the process around and let them ask us questions instead. One of the most frequent questions we get from experienced candidates is: what sort of project planning process do you use? Because we've been in the industry for decades, we recognize this question for what it is: a desperate plea to not have to use Jira or play planning poker ever again.

I tell them it's pretty simple. We have a big spreadsheet that we use to keep track of planned feature work, and every month or so we update it to reflect progress and priorities. It looks like this:
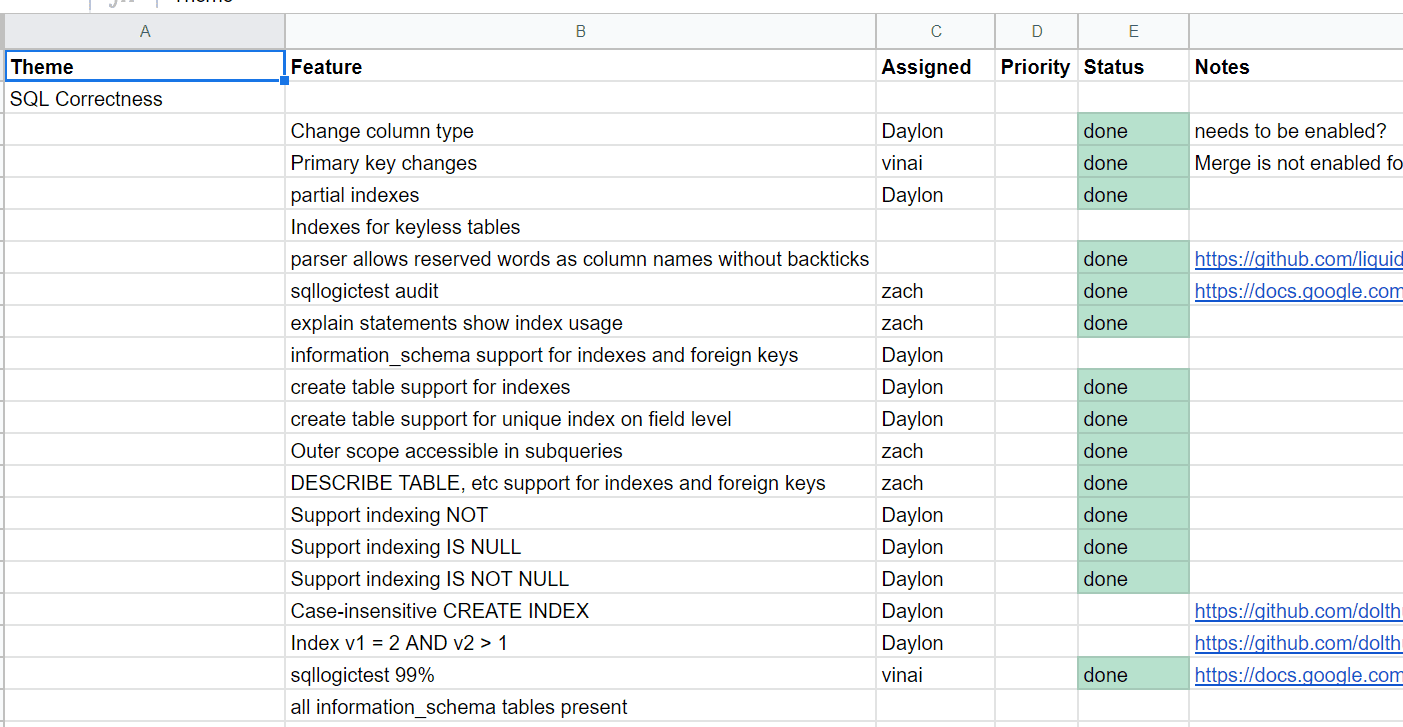
We add new features there when we decide to work on them, and move rows up and down to indicate their relative priorities. For time-sensitive work, we'll sometimes add a deadline to a row. But that's basically it, very little process. The main point of the spreadsheet is to enable us to have discussions about staffing tradeoffs and customer expectations.
- If we deliver stored procedures in October, what else has to slip?
- If Andy works on rewriting the storage layer, who will take over keyless table storage?
We also end up doing a lot of unplanned work, typically requested by a paying customer. They come to us with a query that's too slow or doesn't work correctly, and we give their issue top priority until we have a workaround. Sometimes those issues will get logged on GitHub, but often they never leave our customer chat rooms on Discord. And that's fine. The point of the roadmap isn't to perfectly capture all the work we do (release notes capture that pretty well), it's to help us plan.
Victory lap
At DoltHub, we ship a lot. We announce new features on this blog as they come out, but I want to take a moment to put all these accomplishments in one place, so that you (and we) can appreciate just how many there are. Warning: this is a long list!
| Feature | Release date |
|---|---|
| Change column type | Feb 2021 |
| Primary key changes | Jan 2021 |
| Indexes for keyless tables | Aug 2021 |
| parser allows reserved words as column names without backticks | May 2020 |
| explain statements show index usage | Aug 2020 |
| Outer scope accessible in subqueries | Aug 2020 |
| DESCRIBE TABLE, etc support for indexes and foreign keys | Sep 2020 |
| sqllogictest 99% | Mar 2021 |
| all information_schema tables present | Nov 2020 |
| Schema alteration on keyless tables | Aug 2021 |
| Column defaults | Sept 2020 |
| Triggers | Oct 2020 |
| Dolt CLI functions for SQL | Feb 2021 |
| Auto increment | Nov 2020 |
| Prepared statements | Nov 2020 |
| SIGNAL statement | Mar 2021 |
| Stored procedures | Mar 2021 |
| Keyless tables | Dec 2020 |
| Common table expressions (WITH) | Mar 2021 |
| Tuples for IN expression (multi-column IN) | Aug 2021 |
| Window functions (OVER) | Feb 2021 |
| dolt_commit_ancestors system tables | Mar 2021 |
| dolt_push() and dolt_pull() functions | Sep 2021 |
| Concurrency and transactions | May 2021 |
| INSERT...ON DUPLICATE | Mar 2020 |
| JSON type support | Apr 2020 |
| CHECK constraints | Apr 2021 |
| Foreign Keys | Jul 2020 |
| TRUNCATE table | June 2020 |
| Metaflow support | Apr 2021 |
| CREATE TABLE SELECT | Aug 2020 |
| Hash IN clause evaluation | Jan 2021 |
| N-table joins | Dec 2020 |
| Secondary indexes | May 2020 |
| Use more than one core | Feb 2020 |
| Push where clause down in join execution | Oct 2020 |
| Push projections to Dolt tables (return only a subset of columns) | Mar 2020 |
| Read from indexes, rather than full tables, when possible | Mar 2020 |
| MySQL Workbench support | Aug 2021 |
| Google Sheets support | June 2021 |
| Kedro Support | June 2021 |
| Great Expectations support | June 2021 |
| R Support | Aug 2021 |
| DataGrip support | May 2020 |
| Django support | Aug 2021 |
| Replication | Sept 2021 |
| Backup | Sept 2021 |
| Tags | Sept 2020 |
| Schema merge | May 2020 |
| Shallow pull, clone, fetch | Feb 2020 |
| filter-branch | Nov 2020 |
| Type conversion tests | Apr 2020 |
| dolt system tables | Jan 2020 |
| Detached HEAD SQL mode | Mar 2021 |
| Constraint violations | July 2021 |
| Check constraint violations command | Mar 2021 |
Support for main default branch |
Sep 2021 |
| LOAD_FILE() support | Aug 2021 |
| Generational garbage collection | Aug 2021 |
| Ecto and Elixir support | July 2021 |
| Performance benchmarking | Oct 2020 |
| DoltHub forks | Sept 2020 |
| Query diff | June 2020 |
| Serving multiple databases in a single server | May 2020 |
| AS OF support | Mar 2020 |
| Saved queries | Feb 2020 |
| 2-table indexed joins | Feb 2020 |
| LICENSE and README files | Feb 2020 |
| Views | Feb 2020 |
| SQL queries on DoltHub | Jan 2020 |
| dolt blame | Oct 2019 |
And there's a lot of stuff not even on this list, either because it got done without any fanfare or because it predates when we adopted even this limited planning process. DoltHub is a company that ships, a lot.
Today's roadmap
The product is a lot more mature today than a few years ago, as one would hope. In the earlier days there were so many missing features that prioritization was actually pretty easy: unless somebody was asking for a feature, we would be adding a lot of value no matter where we turned our attention, so strict prioritization didn't matter too much. I joked about this situation in an earlier blog post, but having such a huge surface area to cover was actually really fun and made planning pretty easy.

Today things are a little harder. Besides being an environment that is less target-rich than before, we have a growing number of paying customers and their use cases to support, and a larger pool who would adopt the product if it had some capabilities it doesn't yet. So it's more important now to think about what we're going to support next to make our existing customers happy and lure new ones.
This is always a work in progress, but here's our current top priorities for Dolt:
| Feature | ETA |
|---|---|
| Hosted Dolt | Jan 2022 |
| Join for update | Oct 2021 |
| Backup and replication | Nov 2021 |
| Commit graph performance | Nov 2021 |
| Collation and charset support | Nov 2021 |
| Persistent SQL configuration | Dec 2021 |
| Multiple DBs in one repo | Dec 2021 |
| Tx isolation levels | Dec 2021 |
| 99.9% SQL correctness | Q1 2022 |
Better dolt_diff table experience |
Q1 2022 |
| Hash join strategy | Q1 2022 |
| Storage performance | Q1 2022 |
| SQL GUI support tests | Q1 2022 |
| Lock / unlock tables | Q1 2022 |
| Users / grants | Q2 2022 |
JSON_TABLE() |
Q2 2022 |
| Pipeline query processing | Q2 2022 |
| Table / index statistics | Q2 2022 |
| Universal SQL path for CLI | Q2 2022 |
| Row-level locking (select for update) | Q2 2022 |
| Virtual columns and json indexing | Q2 2022 |
| Embedded dolt | Q3 2022 |
| Signed commits | Q3 2022 |
This list is mostly ordered by planned release date, which gets less certain as we get farther out. Our top priority, hosted Dolt, is a relatively large effort and a major launch, scheduled for year end. Most of the other items on the list are a lot smaller, but there are exceptions: storage performance is code for a near-total rewrite of the storage layer to make it performant for the SQL server, which is a monumental effort (good luck, Andy).
We expect to rearrange this list as time goes on, and for new items to emerge and jump the line. Paying customers (or prospective paying customers) get write access to this roadmap, so if things go well this list will be obsolete in no time flat.
Conclusion
DoltHub ships, a lot. We're proud of the product features we've shipped so far, and eager to put more under our belt. If that sounds like an environment you'd like to be a part of, we're hiring!
Like the article? Interested in Dolt? Think we should be working on other things instead? Come join us on Discord to say hi and let us know what you think.