
Dolt is a MySQL-compatible database that uniquely supports version control operations such as branch, merge, and diff. Aaron Son has blogged about how Dolt stores data in a prolly tree in order to support these operations efficiently. However, efficient version control operations come at the price of write overhead. Most writes will result in multiple chunks of the prolly tree being written, and can result in writing a large portion of the tree. Each chunk ends up on disk, and as a result Dolt may end up using a lot of storage.
In this blog I’ll be talking about some of the changes that we made to garbage collection, and other things we are working on to decrease the amount of garbage stored on disk.
Where Does it come from?#
If there is a chunk on disk that isn’t referenced by the prolly tree it is considered to be garbage. There are two ways in which garbage is generated in Dolt:
- Performing write operations without committing - When a write operation is performed there are certain chunks that are only referenced by the working set. If a second write touches some of those chunks they will be orphaned. Doing many single row write operations on sequential rows generates a tremendous amount of garbage relative to the amount of data actually changed.
- Deleting a branch containing novel chunks - If certain chunks are only referenced by a branch, and that branch is then deleted those chunks become garbage.
dolt gc#

The process utilized by dolt gc is expensive. It takes
every branch, as well as the working set and iterates through each chunk referenced. It copies all referenced chunks to a new file. Once all referenced chunks are
copied Dolt switches over to use the new chunk storage file and deletes any old files. It’s not out of
the ordinary for a dolt gc call to take 10 minutes on a large database. What’s worse, is if you make minor changes and
run dolt gc again it will do it all again and take another 10 minutes.
Generational Garbage Collection#
The latest version of Dolt splits storage into two categories: old generation and new generation. All chunks start off in newgen storage. Below is an example of what chunk storage would look like after cloning a dataset and making two inserts.
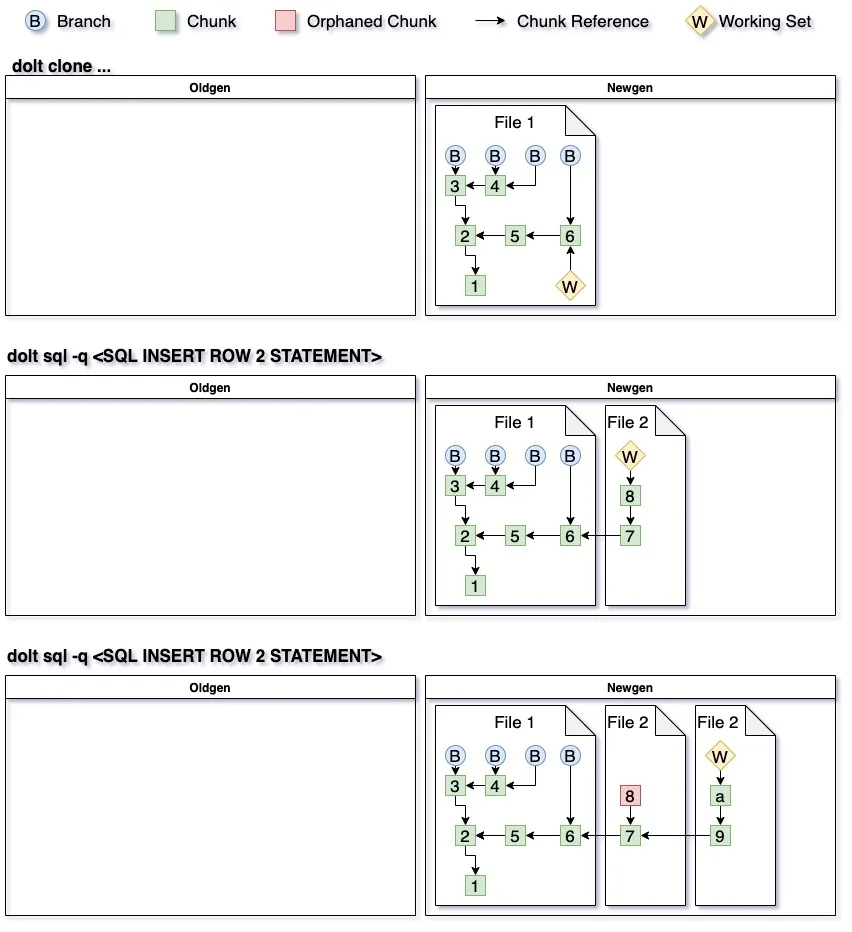
The garbage collection process looks largely similar to the previous iteration. First we iterate through every branch and all the chunks that they reference. If at any point we find a chunk in oldgen then we ignore the chunk and its children. All chunks found during the chunk walk that are not in oldgen are written to a file, and that file is added to oldgen.
Once all chunks referenced by the branches have been processed we walk the chunks referenced by the working set. If a referenced chunk is found in oldgen it and all of its children are ignored. The chunks that are only in newgen are written out to a new file. This file becomes the source of newgen chunks, and all the other files are deleted from newgen. Here you can see what our storage would look like after running garbage collection.
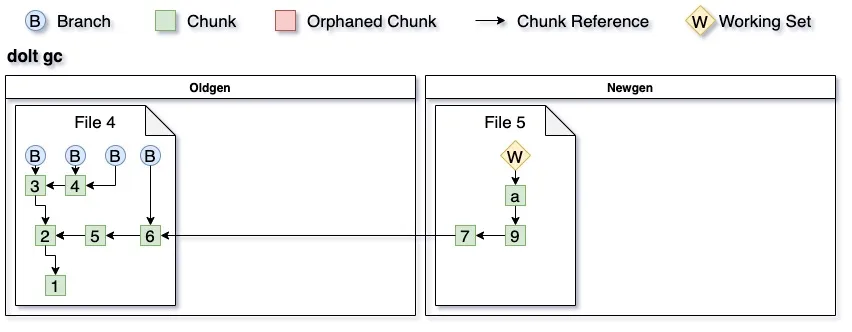
Subsequent edits will result in new chunks in newgen, and subsequent dolt gc calls operate on a smaller set of the data.
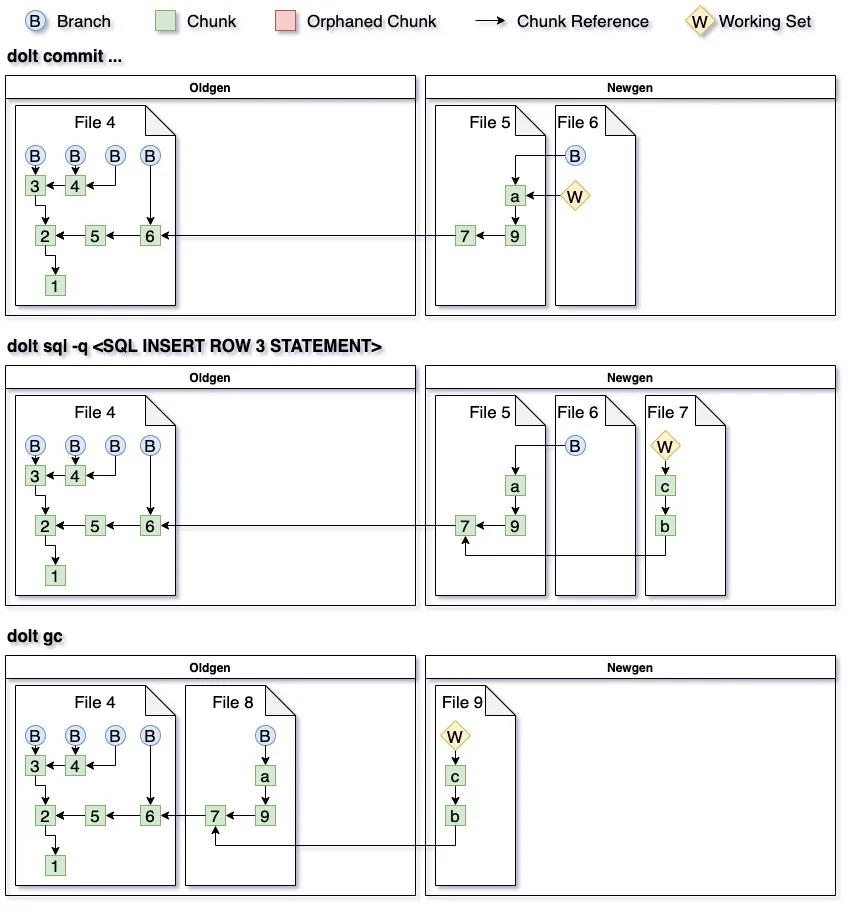
When walking the tree a good amount of chunks will be ignored as they are in oldgen. This means that their children won’t be
looked at, and these nodes and their children will not be copied. Now you can see what happens when we commit, insert another
row, and do a second dolt gc.
Future Improvements#
The current iteration of dolt gc has many advantages, and is the first step towards supporting online garbage collection
for dolt sql-server but its drawback is that there is no way to collect orphaned chunks that exist in the oldgen chunk
storage. Garbage can get into oldgen by deleting branches. This will be rectified shortly by supporting an --oldgen parameter
in dolt gc which will do a full gc.
Another issue we will look to address is the generation of garbage when doing large imports. Currently, our import process
will batch up 256K updates which are applied and flushed to disk. When the data being imported is not sorted it may be that
each batch causes the majority of the tree to be rewritten. For 6M rows this will happen 24 times. Each time we write
chunks that will be orphaned by the next batch. A test import I am looking at right now has 6M rows, and the csv is 2GB on disk.
Executing dolt table import --no-gc ... will result in 12GB garbage being written to disk, and if there are additional indexes
on the table being imported it is even worse. I am currently working on addressing this by making sure the entirety of the
data is in sorted order before importing.
Conclusion#
We know garbage is a problem. We’re working on it. Stay tuned for more advancements.