
Dolt is a tool built for collaboration and data distribution.
It’s “Git for Data,” a SQL database you can branch, merge, diff, clone, fork, push and pull.
Today, we’re announcing support for garbage collection in Dolt.
To manage on-disk storage for Dolt repositories, simply run dolt gc to free unused space.
Dolt’s DAGs#
Dolt combines the core concepts of Git and MySQL. Git versions files, Dolt versions tables. Like Git, Dolt constructs a content-addressable commit graph that supports branching, diffing, and merging. Each node in the commit graph is a logical database containing data structures to store tables and schemas.
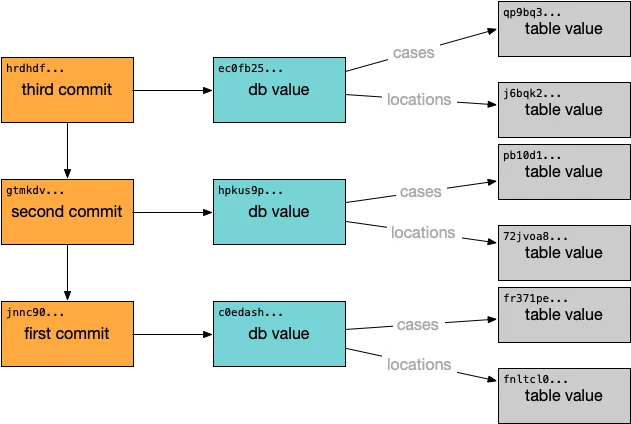
The commit graph is key to supporting version control and sync operations. Two commits or two repositories can efficiently be compared by diffing their contents and then reconciled through a merge or sync. The commit graph also forms a reference graph that connects all “live” storage objects in the repository. Traversing the commit graph is much like traversing an on-heap reference graph in traditional memory management. Starting from a set of roots, all objects reachable within the reference graph are still in-use and all other objects can be discarded. Dolt’s garbage collection starts from the tip of each branch and descends through all of the table storage in the repository. Let’s take a closer look at Dolt’s internals to see what that looks like in practice.
Prolly-trees#
Dolt’s internal architecture is a hybrid between Git-like Merkle Trees and MySQL-like B-trees. Dolt is built on top of a storage layer called Noms. Noms merges concepts of B-trees and Merkle Trees into a Prolly-tree. Like B-trees, Prolly-trees are block-oriented, ordered search trees, which allows for efficient query performance. Like Merkle trees, Prolly trees are content addressable, which provides the basis for version control and structural sharing.

Nodes within a Prolly-tree are called “chunks” and are persisted in a key-value store that is indexed by the hash of each chunk. Mutating a Prolly-tree means recomputing the hashes of the affected chunks and propagating those new references up to parent nodes. In between commits, intermediate forms of Prolly-trees are sometimes persisted, which is the primary source of garbage generated in Dolt. Consider an example where we make a few inserts, followed by a few deletes:
% dolt sql -q "select * from ints;"
+----+
| pk |
+----+
| 1 |
| 2 |
| 5 |
| 12 |
| 18 |
+----+
% dolt sql -q "insert into ints values (6),(21);"
% dolt diff
+-----+----+
| | pk |
+-----+----+
| + | 6 |
| + | 21 |
+-----+----+
% dolt sql -q "delete from ints where pk = 5 or pk = 12"
% dolt diff
+-----+----+
| | pk |
+-----+----+
| - | 5 |
| + | 6 |
| - | 12 |
| + | 21 |
+-----+----+
% dolt add -A && dolt commit -m "made changes"At the storage layer, this is equivalent to writing new Prolly-trees. As new trees are constructed, they will write only the new chunks that are needed and structurally share where possible.
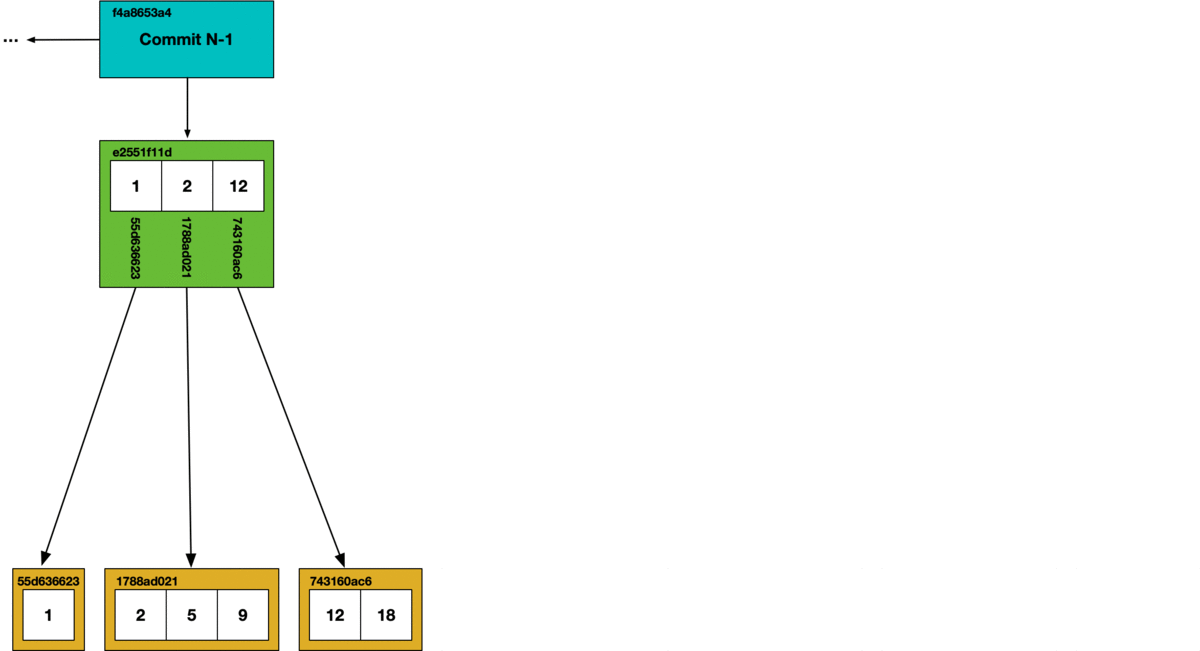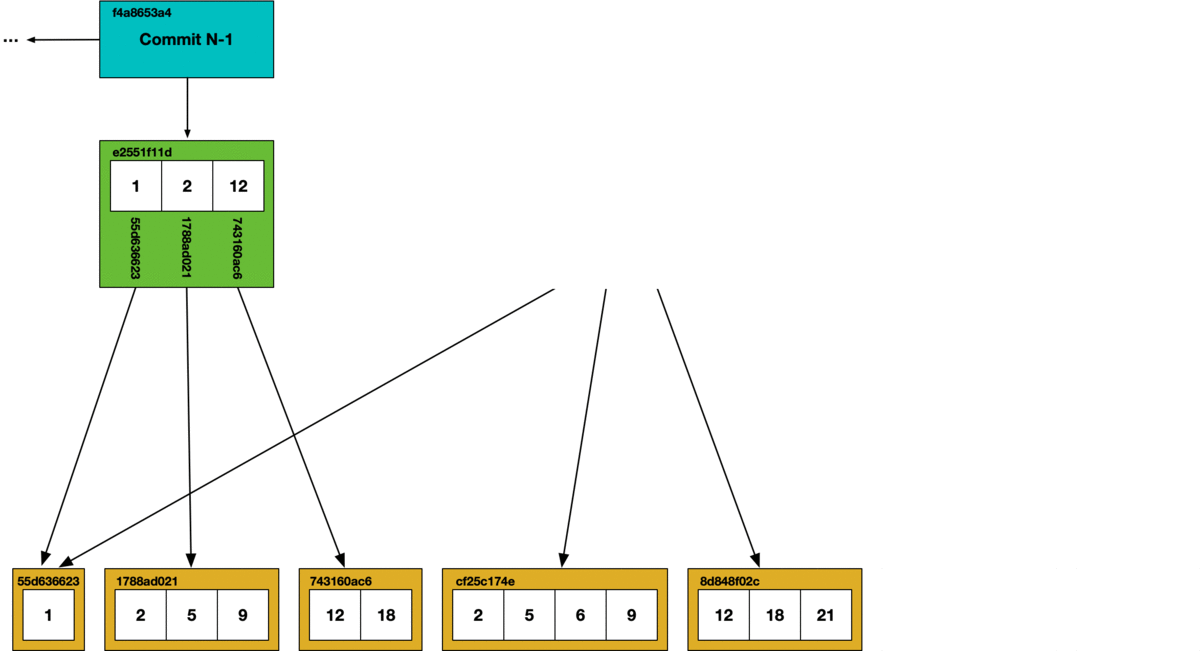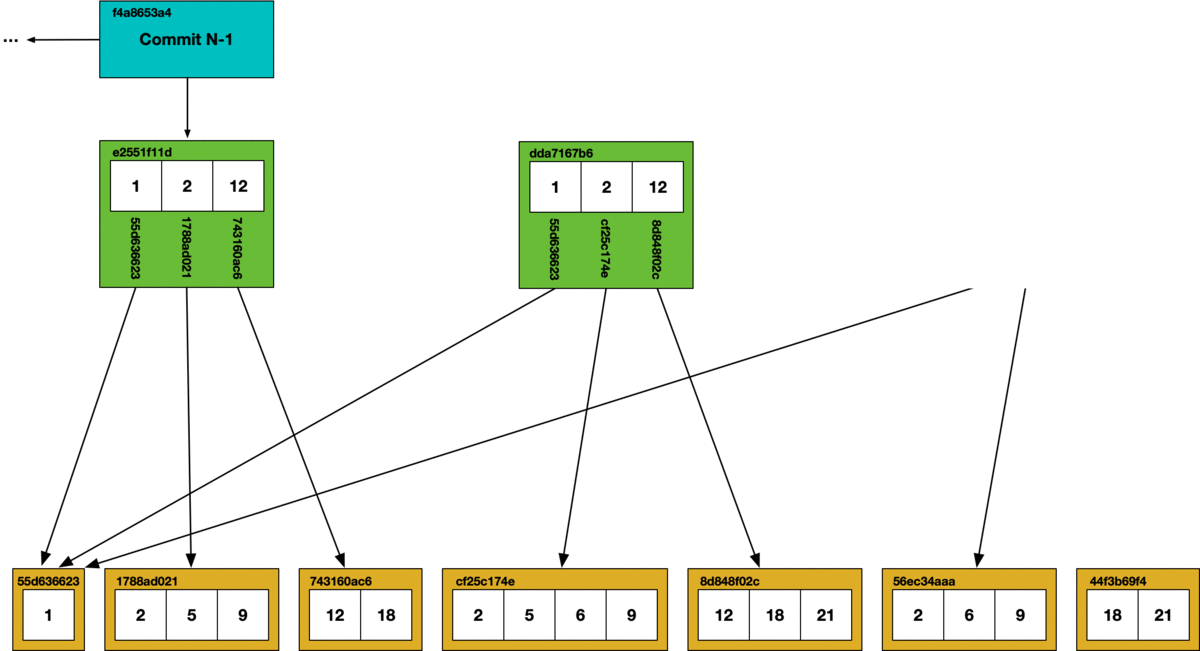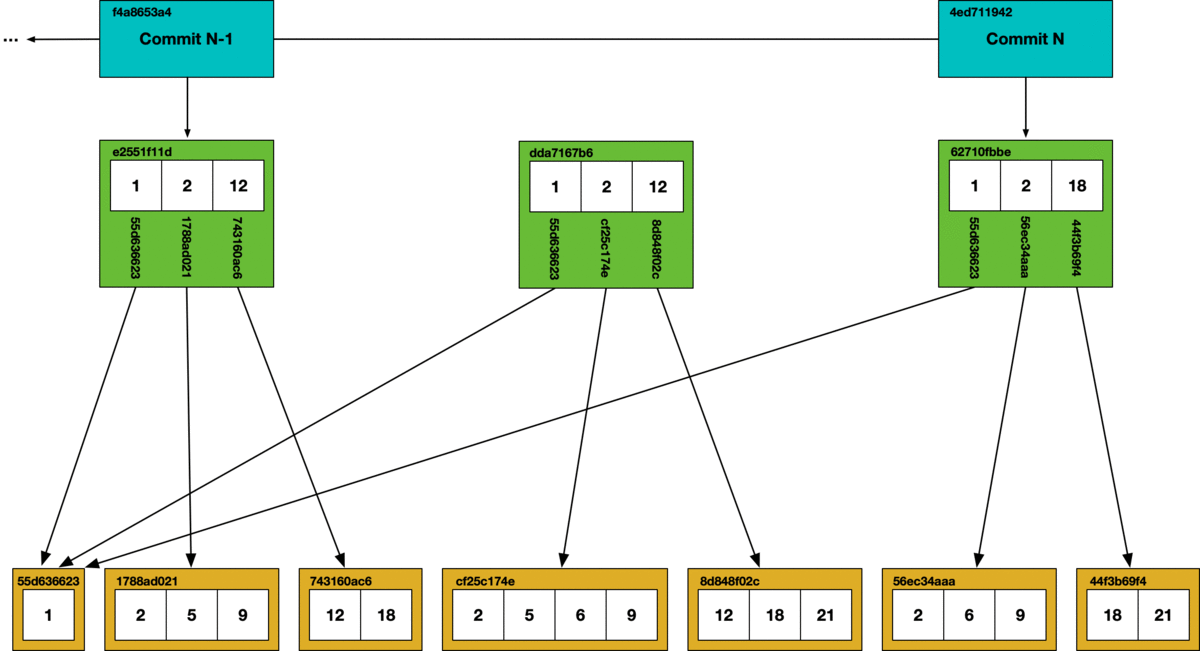
Taking out the trash#
All of Dolt’s internal objects are stored in content addressable chunks. This facilitates a tractable garbage collection operation using a simple mark and sweep algorithm.
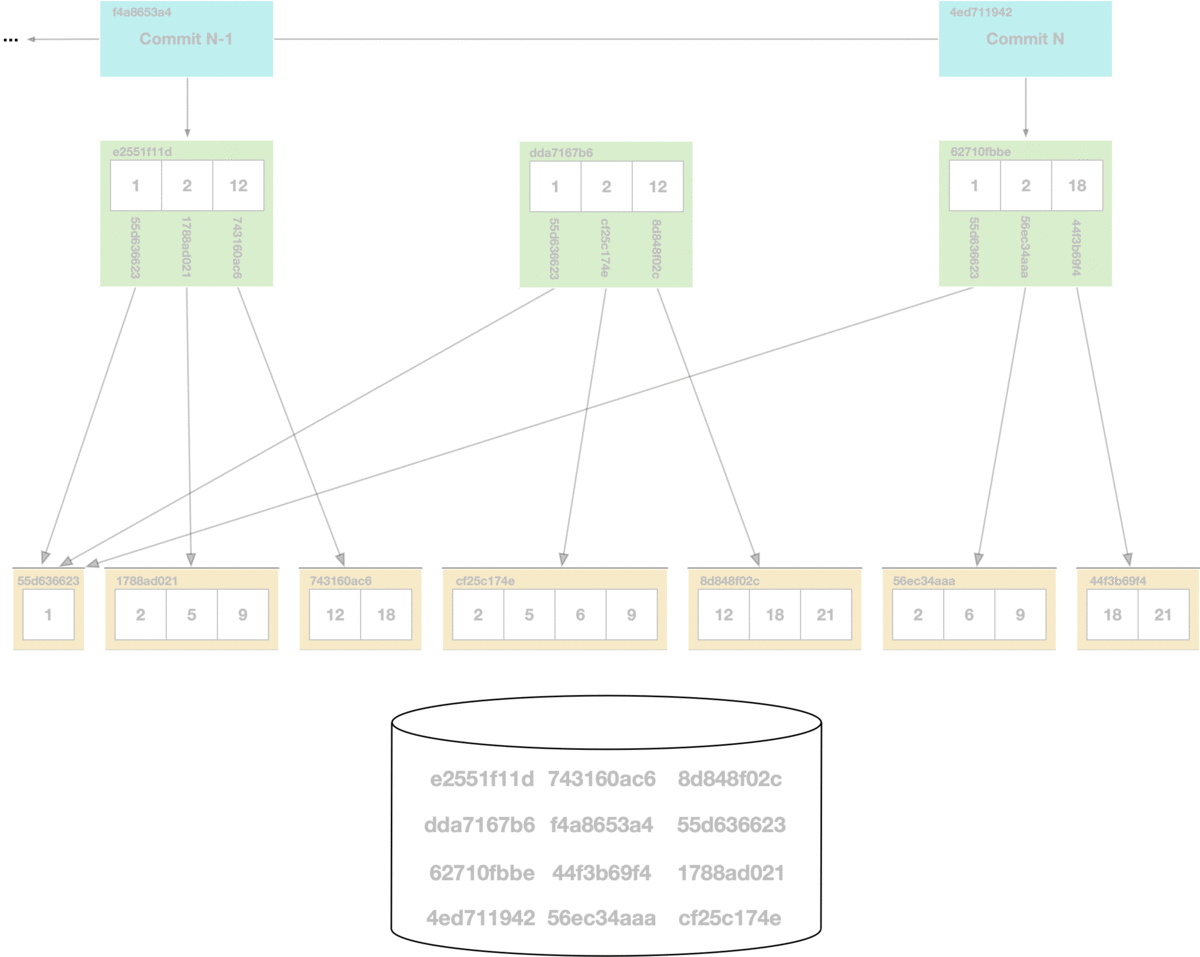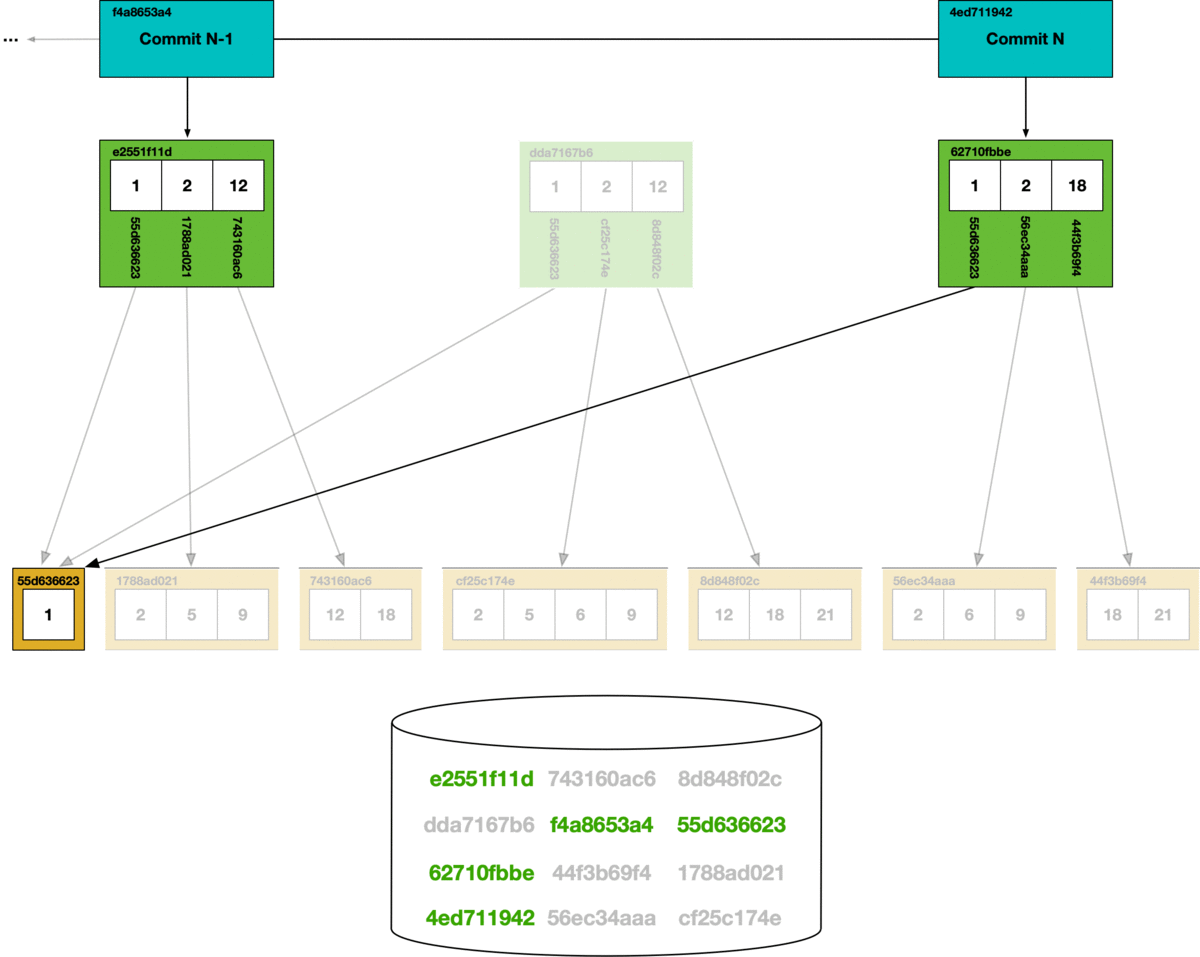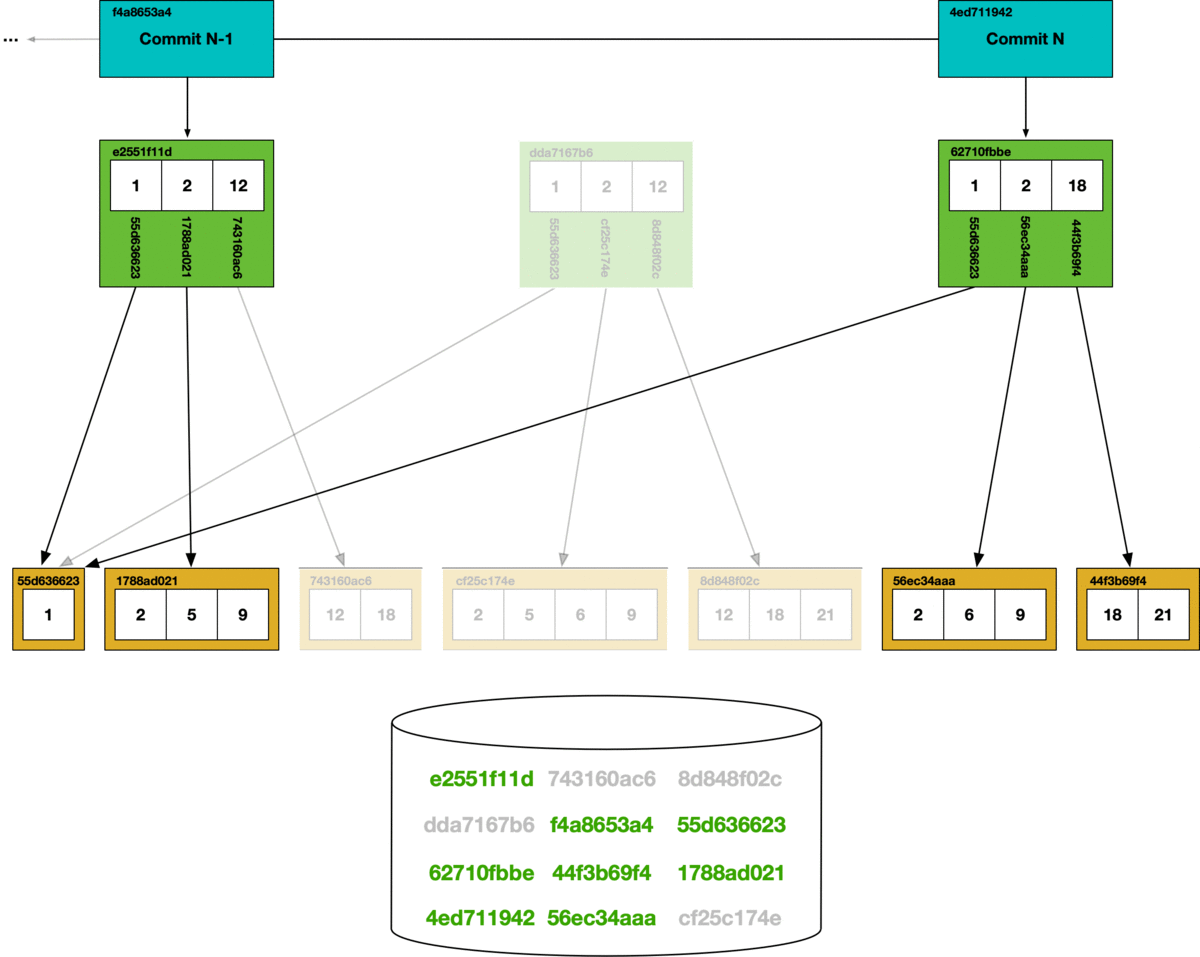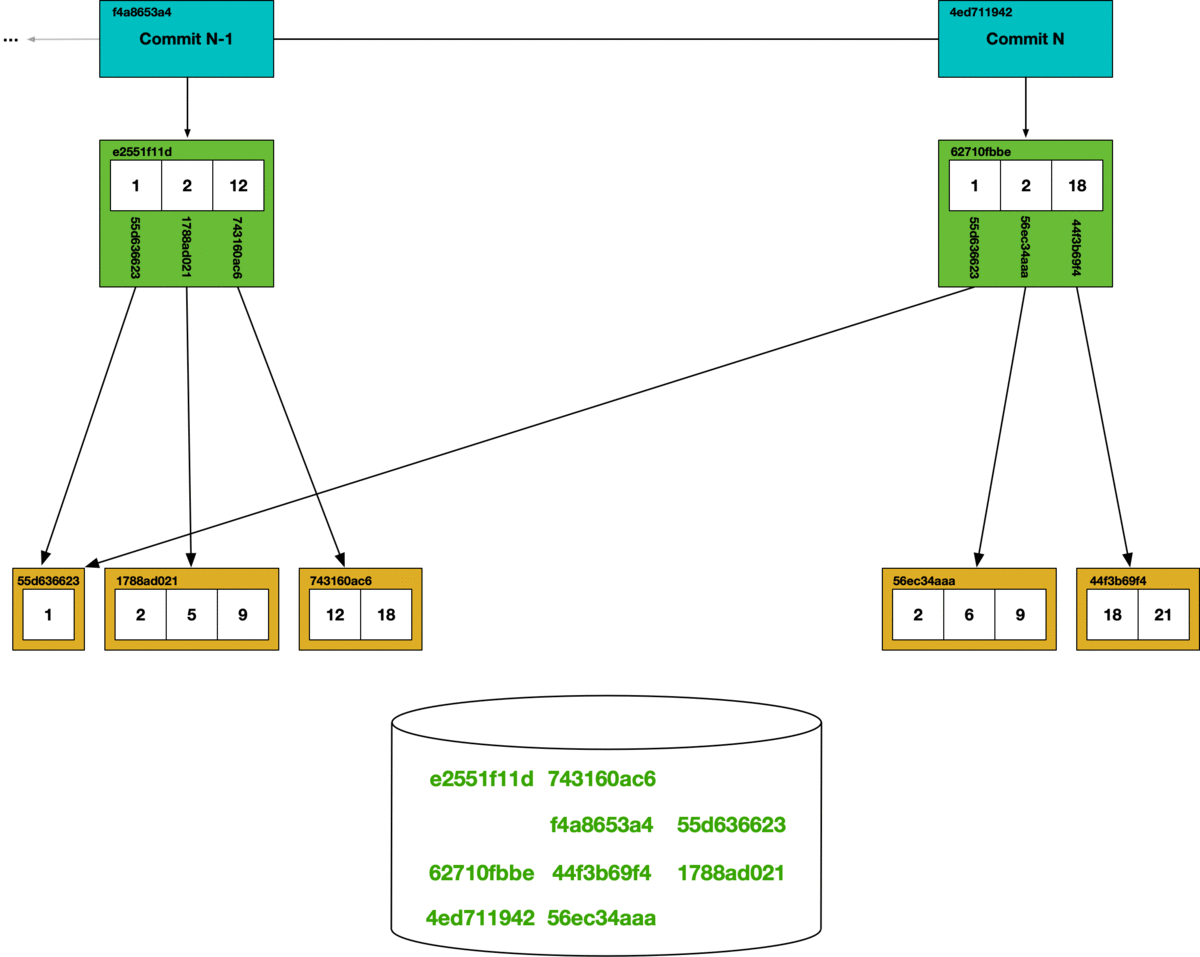
At the bottom of the diagram is the key-value chunk storage. Each chunk that is reached in the commit graph has its hash marked as safe, all other chunks are deleted from the store.
One place GC is especially useful is when importing large data sets. As Dolt reads from a file or other data source, it has to flush lots of intermediate trees to disk in order to manage memory. Recently, the DoltHub team collaborated on building a dataset of city populations, current and historical, as an exercise to test new features for our platform. After importing 50 CSV files, I ran GC to clean things up:
% du -h .dolt/
72M .dolt//noms
0B .dolt//temptf
72M .dolt/
% dolt gc
% du -h .dolt/
3.9M .dolt//noms
0B .dolt//temptf
3.9M .dolt/The resulting repo was about twenty times smaller. Because of Dolt’s storage layer compression, this was actually smaller than the total size of the CSV files!
Conclusion#
Dolt’s storage model provides a fundamentally sound way to build a version controlled database. The commit graph and table storage not only provide an efficient way to query and sync databases, but also provide a means to easily clean up garbage. This first iteration of GC is a somewhat naïve implementation, intended to be used for offline cleanup. It can’t be run concurrently with other operations, but will safely fail if attempted. Future iterations of Dolt GC will borrow from the wealth of research into automatic garbage collection, and will run concurrently with other Dolt operations like sql-server. You can give Dolt a try today by cloning a dataset from DoltHub. We’re adding new features to Dolt all the time – GC is just the latest example. If there’s feedback you have about the product, check out our Discord server, and let us know!