JSON Support in Dolt

Dolt is a tool built for collaboration and data distribution, it's Git for Data. Git versions files, Dolt versions tables. We've built Dolt to support the MySQL query dialect, with the goal of becoming a drop-in replacement for MySQL. Currently, we support 92% of SQL according to sqllogictests. We're constantly driving to add more features to Dolt. Today, we're announcing support for the JSON type in Dolt.
JSON in Relational Databases
Supporting JSON in a relational database may seem somewhat surprising at first.
JSON is not one of the core data types specified by the ANSI SQL standard.
It's also a fundamentally non-relational way to model data: JSON has no defined schema and can contain an arbitrary structure.
In practice, however, the JSON type is quite useful.
JSON typed columns can be used to store optional fields or used for nested data.
MySQL doesn't have native support for ARRAY types, but JSON arrays provide much of the same functionality.
JSON also enables stronger forms of schema denormalization.
One-to-many relationships can be "inlined" by storing the data in JSON field, eliminating the need for joins when performance is critical.
In general, the JSON type provides flexibility within an otherwise rigid relational schema.
Persisting JSON Documents
On disk, MySQL stores JSON data, called "documents", in a MySQL-specific binary format. From the MySQL documentation:
The JSON data type provides these advantages over storing JSON-format strings in a string column: 1. Automatic validation of JSON documents stored in JSON columns. Invalid documents produce an error. 2. Optimized storage format. JSON documents stored in JSON columns are converted to an internal format that permits quick read access to document elements. When the server later must read a JSON value stored in this binary format, the value need not be parsed from a text representation. The binary format is structured to enable the server to look up subobjects or nested values directly by key or array index without reading all values before or after them in the document.
The second point is particularly important: the serialized representation of JSON documents needs to be optimized for lookups. In Dolt, as in MySQL, lookups into JSON documents most often use the JSON path syntax. This lookup syntax allows queries to traverse nested JSON, searching for particular elements:
% dolt sql
dolt> CREATE TABLE js (id int PRIMARY KEY, doc json);
dolt> INSERT INTO js VALUES (1, '[{"a": 1, "b": 2}, {"pi": 3.14, "e": 2.71}]');
dolt> SELECT json_extract(js.doc, '$[1]') FROM js;
+------------------------------+
| json_extract(js.doc, '$[1]') |
+------------------------------+
| {"e":2.71,"pi":3.14} |
+------------------------------+With the MySQL binary JSON format, this lookup is O(1) regardless of the array's size. While implementing JSON types in Dolt, we made it a design goal to achieve similar performance characteristics. However, Dolt has a radically different storage engine than MySQL. It's built on top of Noms and uses Prolly-Trees to store table data. Prolly-trees are content-addressable and have structural-sharing between revisions. They're what powers Dolt's efficient diff and merge algorithms. In addition to efficient lookup performance, Dolt's JSON format needed to work seamlessly with its version control features.
Noms Data Types
Dolt uses Noms as a storage layer to persist table data and leverages its Merkle-Tree for version-control.
Noms itself is much closer to a document store than a SQL database.
Its storage layer API defines a number of data types that can be composed to model arbitrary data.
It defines scalar types like Int, Bool, and String, and collections such as List, Map and Set.
A compound Noms value might look like the following:
Map(
String("list"): List(
String("a"),
String("b")
),
String("map"): Map(
String("x"): Float(2.71),
String("y"): Int(42)
)
)Nom's data types are a natural fit for storing JSON data in Dolt.
The List and Map collections correspond directly to JSON Arrays and JSON Objects.
The Noms value in the example above converts to and from the following JSON value:
{
"list": ["a", "b"],
"map": {
"x": 2.71,
"y": 42
}
}This value can then be serialized into Nom's binary format and written to disk.
Nom's binary format for collections stores "offsets" for each element.
The Noms Map value in our example contains two elements, both of which are nested collections.
When these collections are serialized to a byte array, each collection will store the byte offset of each of its elements.
Offsets facilitate lookup performance by eliminating the need scan the entire byte array.
Adaptive Chunking
Serialized Noms values are called "chunks" and are persisted in a content-addressable ChunkStore. The ChunkStore is responsible for reading and writing chunks from disk, much like a page manager in traditional RDBMS. Chunks in a ChunkStore are fetched and stored using the hash of their contents (hence "content-addressable"). For scalar values and small collections, the entire value is stored in a single chunk. When collections grow large, they are split into smaller chunks and organized into a Prolly-Tree. The decision of when to split a chunk into smaller chunks is made probabilistically by a rolling hash function. The goal of this function is to create chunks with an average size of 4kb. The structure of a Prolly-Tree resembles a B+ Tree. Each leaf chunk contains a portion of the larger chunked collection, and is referenced from an internal node of the tree.
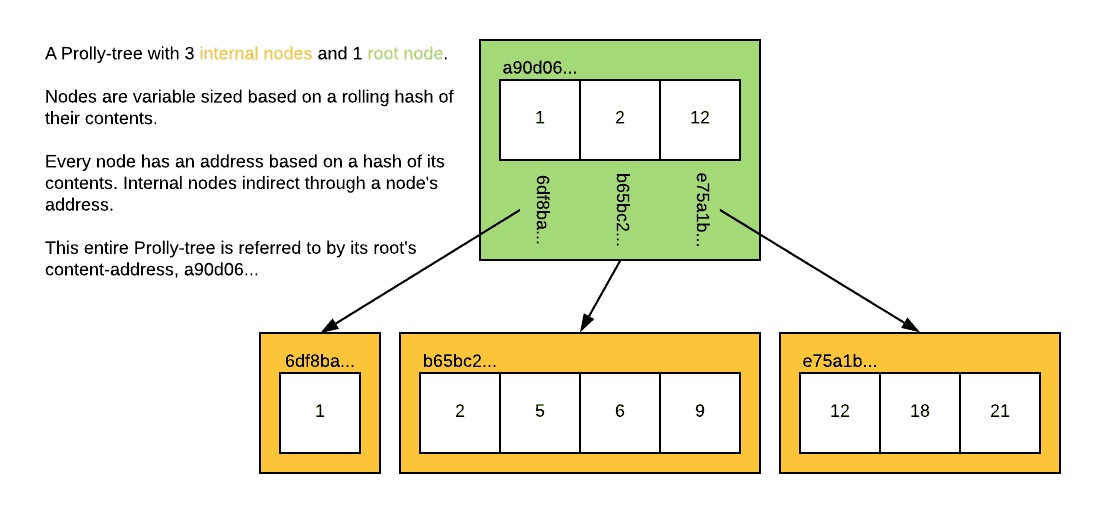
Within an individual chunk, offsets are used to efficiently access. Across the collection's Prolly-Tree, we can use tree traversals to perform efficient point and range lookups. MySQL can efficiently access elements within JSON document, but it still needs to read the entire document from disk into memory. For small documents, this isn't a problem, and in these instances Dolt will also read the entire document into memory. For large documents, Dolt only needs to read a fraction of the data from the ChunkStore to perform a lookup. By using Noms Collection values to store JSON documents, we get the best of both worlds.
Chunking large JSON documents has another major benefit: structural sharing. Structural sharing is a property of immutable data structures where multiple objects share common memory or storage. It's one of the fundamental properties of Merkle Trees that allows for efficient storage in Git.
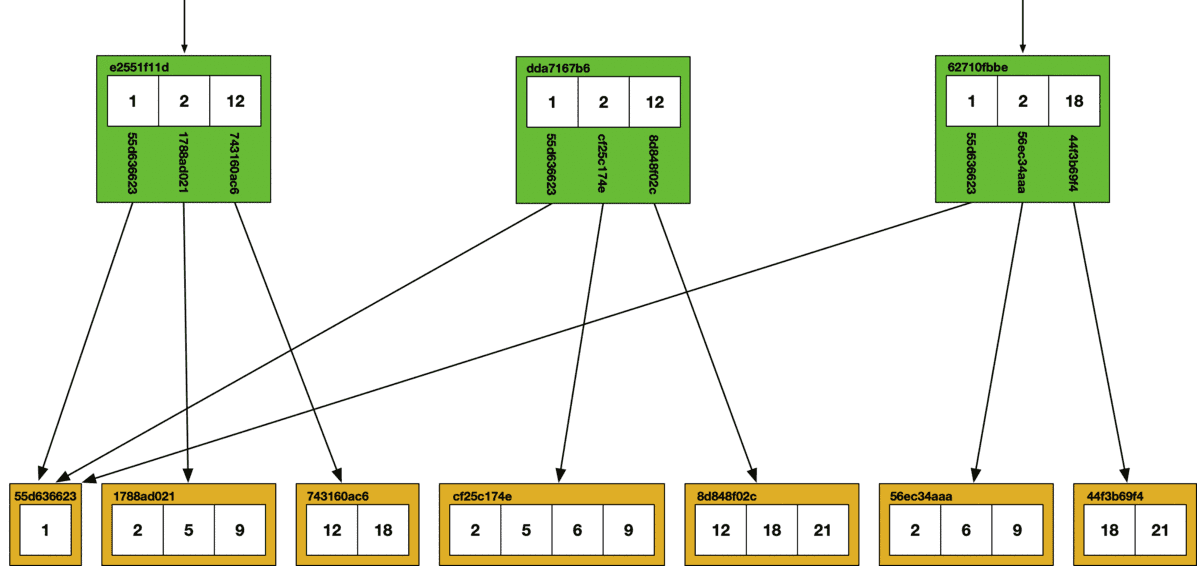
In the context of Dolt, structural sharing allows chunked collections to share common leaf nodes. Each content-addressed chunk is stored only once in the ChunkStore, so overlapping Prolly-Trees share storage. The probabilistic chunking function is designed to maximize structural sharing between JSON documents. This applies JSON documents both within and across revisions.
Conclusion
Support for JSON is the latest step in make Dolt 100% compatible with MySQL. The JSON type is the most complex of the MySQL types, and required careful consideration in its design. Leveraging Dolt's unique storage layer, we have built a performant and space-efficient implementation. If you're interested in learning more about Dolt and its branch-and-merge model, check out our technical blog series or join us on Discord and talk to us directly!