
Dolt is Git for data. Git versions files. Dolt versions SQL tables. Dolt’s SQL engine is go-mysql-server, which is an open source project that we adopted a few months ago. Today we’re excited to announce better support for subqueries in the engine, and we want to talk about how we implemented this feature.
Subquery scope#
Before this work, subqueries were supported in the engine, but in a somewhat limited fashion. Subqueries could not reference columns in the outer scope, which really limited their usefulness.
This is easiest to illustrate with an example. Suppose you have two tables that define the population of various states and cities. I haven’t checked, but these are probably not the actual population totals.
| states | cities | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
For each state, I want to know a single city with a bigger population, if there is one. There’s no way to do this with a join, but it’s easy with a subquery:
SELECT state,
(SELECT city FROM cities WHERE pop > states.pop LIMIT 1) AS bigger_city
FROM states
ORDER BY 1This query yields the following result:
+-------+-------------+
| state | bigger_city |
+-------+-------------+
| NE | Houston |
| SD | NULL |
| WY | NYC |
+-------+-------------+In order for this query to execute, the execution of the subquery must
understand the outer scope of the overall query. That is to say: the
subquery needs to execute N times, once for every state, and get an
appropriate value of states.pop from the outer row each time. Sounds
easy!
Unfortunately, this simple requirement was not simple to implement. It took a total rewrite of the query analyzer to accomplish.
The Analyzer function#
As we detailed in an earlier blog post, the SQL engine uses a three-pass algorithm to convert a text query into an execution plan. These are:
- Parse. Turn the text of the query into an AST.
- Plan. Turn the AST into a query plan of nested
Nodeobjects. Nodes are things like Projection, or Filter. - Analyze. Reorganize the query plan into an execution plan. This includes matching tables and columns named in the query plan to those available in the catalog.
The first two phases are straightforward transformations of the query
into alternate representations. They produce a graph of Node
objects, where each node optionally wraps one or more child nodes to
produce its result. For our example query, this looks something like
this:
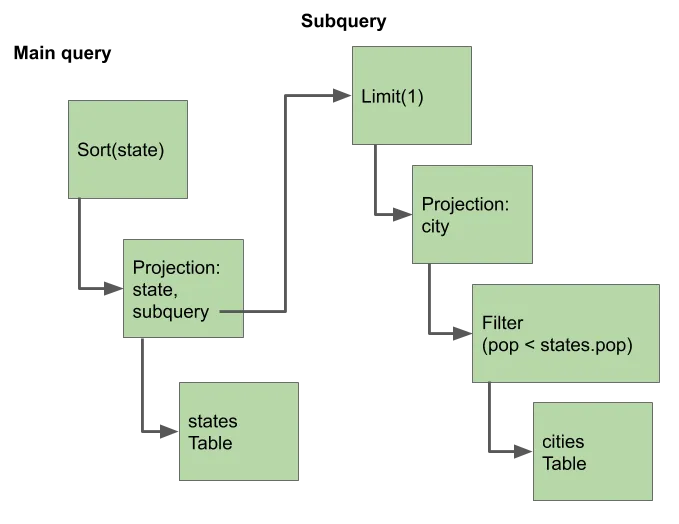
But it’s the last phase, analysis, where things get interesting.
The analyzer is composed of a series of functions, each of which
optionally applies some transformation to the query tree. Each
analyzer rule takes the root Node of the query and returns it
transformed, or else unchanged. Its signature before this work looked
this this:
type RuleFunc func(*sql.Context, *Analyzer, sql.Node) (sql.Node, error)Unsurprisingly, subqueries are analyzed recursively. The analyzer rule that resolved subqueries looked something like this:
func resolveSubqueryExpressions(ctx *sql.Context, a *Analyzer, n sql.Node, scope *Scope) (sql.Node, error) {
return plan.TransformExpressionsUpWithNode(n, func(n sql.Node, e sql.Expression) (sql.Expression, error) {
s, ok := e.(*plan.Subquery)
if !ok {
return e, nil
}
return a.Analyze(ctx, s.Query)
})
}The problem should be obvious: in order for the subquery analysis to resolve columns defined in the outer scope of the query, it needs access to those outer scope nodes. The solution is equally obvious: change the analyzer function signature to take this outer scope.
type RuleFunc func(*sql.Context, *Analyzer, sql.Node, *Scope) (sql.Node, error)Then the analyzer rule to resolve subquery expressions becomes (roughly):
func resolveSubqueryExpressions(ctx *sql.Context, a *Analyzer, n sql.Node, scope *Scope) (sql.Node, error) {
return plan.TransformExpressionsUpWithNode(n, func(n sql.Node, e sql.Expression) (sql.Expression, error) {
s, ok := e.(*plan.Subquery)
if !ok {
return e, nil
}
subScope := scope.newScope(n)
return a.Analyze(ctx, s.Query, subScope)
})
}There are a few wrinkles, but this is the basic idea required to make subqueries work.
Passing outer scope to subquery evaluation#
Now that analyzer functions can get access to outer query scope, we need to make use of it. How?
First, let’s look at the definition of the expression.Eval function,
which is how the subquery expression is evaluated.
func (s *Subquery) Eval(ctx *sql.Context, row sql.Row) (interface{}, error)Like all expressions, a subquery expression is evaluated against a
row. That row is the result of the current Node of the exection tree
— in the simplest case, just a row from a table in the query. Our
goal is to pass that row to the subquery, such that every row being
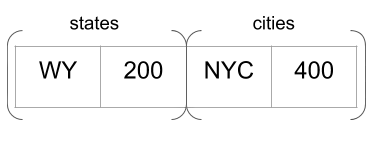
evaluated by the subquery has the the outer scope prepended. For our
example query, this the inner query needs to know the outer query’s
current value for the pop column, so it can use it in the
filter. Here’s what this compound row would look like when evaluating
the first row of states and the second row of cities.
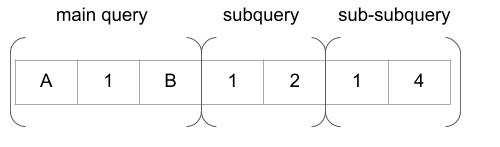
Subqueries can be nested inside one another to an arbitrary depth, so for multiple nested subqueries we just keep prepending row values recursively. The outer query always has its row value first, followed by row values for sub queries, then sub-sub queries, and so on.
Putting it all together#
This is a relatively simple idea, and the steps to implement it are straightforward (but full of details that are easy to get wrong).
- Look in the outer scope for missing names when resolving tables
and columns during analysis. In our example query, this means that
the subquery has to look into the outer scope to resolve the field
states.pop. - Offset the field access indexes to account for outer-scope row values being prepended. For our example query, the field indexes used to access columns in subquery rows are all shifted by 2, since there are 2 columns in the outer scope.
- Prepend outer scope row values to all rows being evaluated during subquery execution
The first two steps are simple to understand but difficult to get right, and needed lots lots of experimentation and testing to nail down. They’re also not that interesting to explain in detail. But the third step has a very simple and elegant solution worth examining.
To prepend our outer scope values every time the subquery executes,
we’ll just create a new, slightly altered copy of the query plan for
the subquery that prepends those values everywhere necessary. To do
this, we make use of a common function of the engine,
TransformUp. TransformUp recursively applies a transformation
function to a Node and its children, and is the main way that
analyzer functions do their job. Here’s the entire, relatively succinct
implementation of the transformation function that prepends outer
scope values.
// prependNode wraps its child by prepending column values onto any result rows
type prependNode struct {
UnaryNode
row sql.Row
}
type prependRowIter struct {
row sql.Row
childIter sql.RowIter
}
func (p *prependRowIter) Next() (sql.Row, error) {
next, err := p.childIter.Next()
if err != nil {
return next, err
}
return p.row.Append(next), nil
}
func (p *prependNode) RowIter(ctx *sql.Context, row sql.Row) (sql.RowIter, error) {
childIter, err := p.Child.RowIter(ctx, row)
if err != nil {
return nil, err
}
return &prependRowIter{
row: p.row,
childIter: childIter,
}, nil
}
func (s *Subquery) Eval(ctx *sql.Context, row sql.Row) (interface{}, error) {
scopeRow := row
// Any source of rows, as well as any node that alters the schema of its children, needs to be wrapped so that its
// result rows are prepended with the scope row.
q, err := TransformUp(s.Query, prependScopeRowInPlan(scopeRow))
if err != nil {
return nil, err
}
iter, err := q.RowIter(ctx, scopeRow)
...
}
// prependScopeRowInPlan returns a transformation function that prepends the row given to any row source in a query
// plan. Any source of rows, as well as any node that alters the schema of its children, needs to be wrapped so that its
// result rows are prepended with the scope row.
func prependScopeRowInPlan(scopeRow sql.Row) func(n sql.Node) (sql.Node, error) {
return func(n sql.Node) (sql.Node, error) {
switch n := n.(type) {
case *Project, sql.Table:
return &prependNode{
UnaryNode: UnaryNode{Child: n},
row: scopeRow,
}, nil
default:
return n, nil
}
}
}If we did everything right, then every time the subquery is evaluated,
we will create an altered copy of the query plan that gets columns
from the outer query added to it. For our example query, the altered
query plan would look like this for the first row in the states
table:
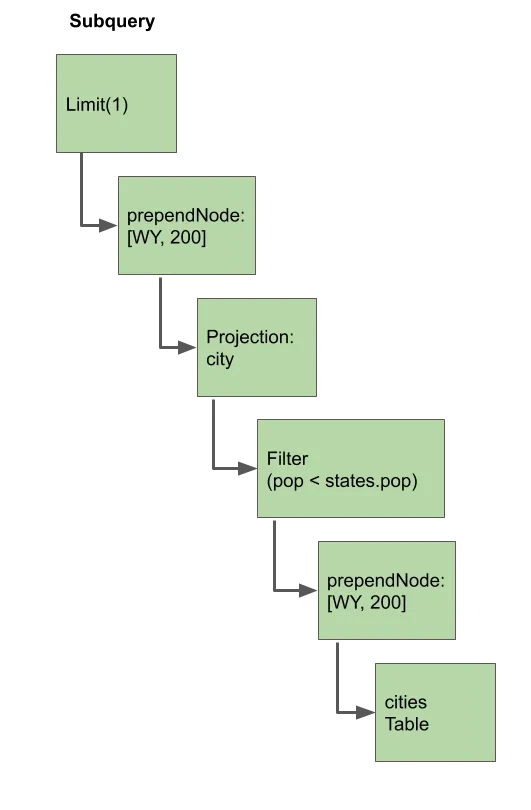
Every time the subquery expression is evaluated with a new row, a new
version of the plan is generated that prepends the appropriate outer
scope values. Note that this method introduces an unnecessary
prependNode above the top Projection node. Some parent nodes of a
Projection Node might need access to the outer scope, but Limit
does not. This could be optimized away in another round of work.
Debugging query analysis#
The current engine analyzer has over two dozen analyzer rules, each of which has various subtleties. Understanding how they interact and change the execution tree can be challenging. The debugger is always helpful, but the object graphs are so massive that digging through them can get very tedious.
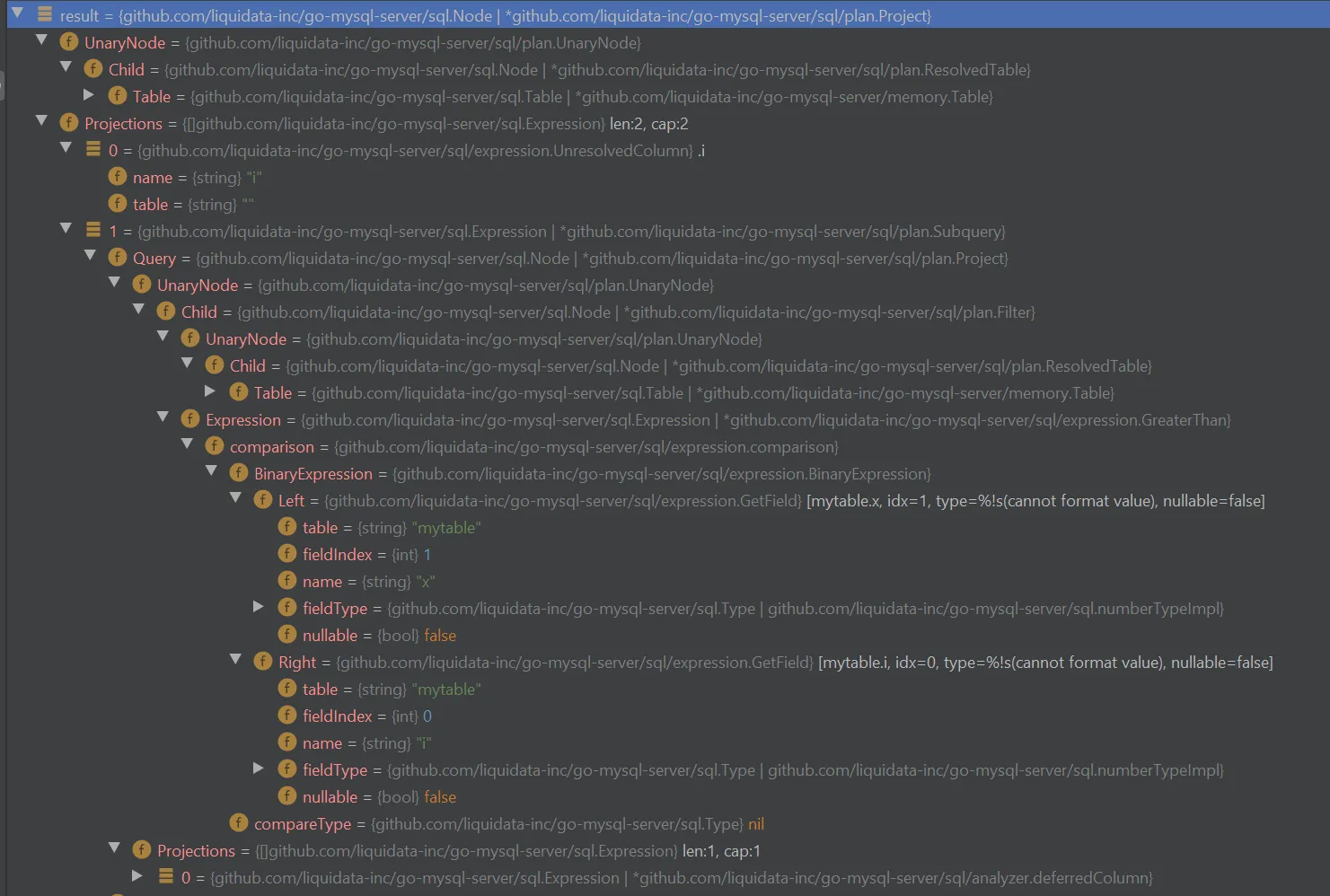
To make debugging during development more tractable, I implemented a couple different improvements.
DebugString() method#
DebugString(), which complements the standard fmt.String(), is a
pseudo-standard in the golang world. If your object implements it,
you’ll get better debug information in GoLand and other debuggers. In
the engine, I use it to return a textual representation of Nodes
that show me at a glance all the relevant information they contain, so
I don’t have to dig through their guts in the debugger GUI.
Diff printing in the analyzer#
With DebugString() implemented for most of the nodes that I cared
about, I next added logging to the analyzer to compute and output the
diff between analyzer steps, using the same diff library used by the
popular testify testing library. This makes it easy to what each
step is actually doing to the execution tree.
func (a *Analyzer) LogDiff(prev, next sql.Node) {
if a.Debug && a.Verbose {
if !reflect.DeepEqual(next, prev) {
diff, err := difflib.GetUnifiedDiffString(difflib.UnifiedDiff{
A: difflib.SplitLines(sql.DebugString(prev)),
B: difflib.SplitLines(sql.DebugString(next)),
FromFile: "Prev",
FromDate: "",
ToFile: "Next",
ToDate: "",
Context: 1,
})
if err != nil {
panic(err)
}
if len(diff) > 0 {
a.Log(diff)
}
}
}
}Here’s a sample diff when resolving a subquery:
INFO: default-rules/0/resolve_subquery_exprs/default-rules/0/resolve_subquery_exprs: --- Prev
+++ Next
@@ -3,5 +3,5 @@
├─ Grouping()
- └─ Filter([two_pk.pk2, idx=7, type=TINYINT, nullable=false] IN (Project(pk2)
- └─ Filter(c1 < opk.c2)
- └─ UnresolvedTable(two_pk)
+ └─ Filter([two_pk.pk2, idx=7, type=TINYINT, nullable=false] IN (Project([two_pk.pk2, idx=14, type=TINYINT, nullable=false])
+ └─ Filter([two_pk.c1, idx=15, type=TINYINT, nullable=false] < [opk.c2, idx=2, type=TINYINT, nullable=false])
+ └─ Table(two_pk)Conclusion#
This work is the latest in our ongoing mission to deliver 100% MySQL compatibility to Dolt and go-mysql-server. If this mission speaks to you, you can get involved by finding and filing issues, or submitting a PR. Or just download Dolt to try it yourself today!