
At DoltHub we are building Dolt, a relational database with Git-like version control features. Naturally we are interested in measuring the performance profile of Dolt, and we would also like to make it easy for contributors to assess the effect of their contributions are having on performance. This blog post details how we built a benchmarking “harness” for Dolt around sysbench, an industry standard toolkit for benchmarking databases.
Requirements#
Measuring database, or indeed program, performance is a notoriously tricky problem. Modern processors engage in complicated multiplexing, and there is large element of randomness involved in program execution time. For example, almost everyone at DoltHub uses a MacBook Pro, but we aren’t all doing the same thing when we run our database benchmarks. This means the database, and the benchmarking program itself, are sharing compute and memory resources with a different set of programs whose requirements have the ability to influence execution time.
Fortunately there are tools out there that exist for helping us with measuring performance even if we can’t isolate hardware through time. One such tool is sysbench. Running sysbench against Dolt requires the following steps:
- build Dolt at the commit you want to test, often the current working set
- create a test database, and fire up the SQL server
- run a (long)
sysbenchcommand with a list of tests
This will produce a benchmark at the given commit, but how do we know that the changes at this commit have improved performance? A better approach might be to repeat the previous steps for an ancestor commit, and check that the diff between the two has improved performance. However, this leaves developers to:
- build two copies of Dolt, each at a different commit, requiring them to stash/commit changes etc.
- create two separate test databases, one with each binary, and launch two SQL server processes (ensuring port isolation, etc.)
- run the
sysbenchcommands and capture the results while being careful to ensure that the results correspond to the correct commits
This introduces a host of possible clerical errors, not to mention a lot of work. We decided to a build some basic tools that would allow our team, and any open source contributors, to do this kind of comparative benchmarking. Our goal was to lower the cost of assessing the performance impact of a given set of changes. The interface we wanted to achieve was allowing developers to isolate a “patch” by choosing two commits:
$ ./benchmark_dolt <from_commit> <to_commit>We would then take care of building Dolt binaries for each commit, running benchmarks inside containers (to achieve a bit more uniformity and control), and optionally publishing the results.
Architecture#
We now examine each of the components we put together to produce a uniform benchmark:
sysbench: the measurement tool we chose to employ, we explain why- building and benchmarking: how we actually build the binaries and run the benchmarks behind the simple interface we laid out above
- publishing: how we publish to DoltHub
sysbench#
We mentioned at the outset that we chose to build on top of sysbench. After some digging around it seemed to be the clear choice for benchmarking databases. As well as being an industry standard choice, the creator of sysbench was also a contributor to MySQL, a major source of inspiration for us. sysbench also provided important scripting capabilities, allowing users to define custom Lua scripts that measured arbitrary query performance.
This last capability was crucial for us. Though Dolt is a relational database, its set of target use-cases are not primarily (at least for now) in the traditional Online Transaction Processing (OLTP) space. Most of sysbench’s out of the box benchmarks are OLTP oriented, but with the ability to script our own benchmarks we are able to measure things like full table scan performance, and other more ETL oriented operations.
This struck the right balance for us. We got the robust measurement tools that sysbench provides, but the ability to test Dolt in the ways that would prove most useful to current and prospective users, as well as aiding the development team.
Building and Benchmarking#
The following commands are run from dolt/benchmark-tools, where dolt is the root directory of the Dolt Git repository.
To build and run a benchmark, users simply specify current to build of the local working set, or a commmittish, a commit or a pointer that can be recursively resolved to a commit. Our scripts then take care of producing the relevant binaries in a clean and repeatable way. For example to compare the current working set to commit 19f9e571d033374ceae2ad5c277b9cfe905cdd66, we run the following dolt/benchmark-tools, where current is implicit when one commit is provided:
$ ./run_benchmarks.sh bulk_insert oscarbatori 19f9e571d033374ceae2ad5c277b9cfe905cdd66This will kick off building and benchmarking. The results of the build can be found in dolt/benchmark-tools/working, noting that dolt/benchmark-tools/working/dolt is a clone of the remote repository to avoid tampering with the user’s local working set (particularly as those changes are very likely to be under test):
$ ls -ltr working
total 207744
drwxr-xr-x 20 oscarbatori staff 640 Oct 12 13:20 dolt
-rwxr-xr-x 1 oscarbatori staff 52818645 Oct 12 13:22 19f9e571d033374ceae2ad5c277b9cfe905cdd66-dolt
-rwxr-xr-x 1 oscarbatori staff 52783582 Oct 12 13:23 ebe6956d1457b83eb9aac9bec4bae1596f63f263-dirty-doltWe inserted dirty to the binary built off the HEAD of the the local working set to indicate the repository was not clean, along with the result of git rev-parse HEAD.
Once the binaries shown above have been produced, the actual benchmarking can take place. We do this inside a Docker using a Python wrapper around sysbench, running the following, which is taken from the run_benchmarks.sh script (with appropriate value substitution):
$ docker run --rm -v `pwd`:/tools oscarbatori/dolt-sysbench /bin/bash -c '
set -e
set -o pipefail
ln -s /tools/working/ebe6956d1457b83eb9aac9bec4bae1596f63f263-dirty-dolt /usr/bin/dolt
cd /tools
dolt config --add --global user.name benchmark
dolt config --add --global user.email benchmark
python3 \
sysbench_wrapper.py \
--committish=ebe6956d1457b83eb9aac9bec4bae1596f63f263-dirty \
--tests=bulk_insert \
--username=oscarbatori
'This mounts the dolt/benchmark-tools directory in /tools on our container, adds the relevant Dolt binary to the execution path, and then executes our sysbench wrapper. The wrapper takes care of standing up the Dolt SQL server, executing the tests, and parsing the output. The output appears as as a CSV per binary being tested, with a row per test:
ls -ltr output
total 16
-rw-r--r-- 1 oscarbatori staff 494 Oct 12 13:22 19f9e571d033374ceae2ad5c277b9cfe905cdd66.csv
-rw-r--r-- 1 oscarbatori staff 492 Oct 12 13:23 ebe6956d1457b83eb9aac9bec4bae1596f63f263-dirty.csvWe have now produced a relatively uniform benchmark across two arbitrary commits to Dolt. This doesn’t eliminate all variance, but it’s a pretty good shot at producing directly comparable results.
Publishing#
While we do realize that results are so context dependent as to be often not useful for comparison, we wanted users to be able to publish results. Dolt is still sufficiently immature that even with hardware and software sourced variance we should be able to spot broad trends over time. with this in mind we decided to share the Dolt performance results inside a Dolt database, hosted on DoltHub. This offers all the benefits of Dolt, namely a portable SQL database, as well as a web interface for quick analysis.
To make it easy to publish results we provide a Python script that publishes the results (note this requires Doltpy, Dolt’s Python API):
python \
push_output_to_dolthub.py \
--results-directory output \
--remote-results-db dolthub/dolt-benchmarks-test \
--remote-results-db-branch oscarbatori/test-runThis will create a branch called oscarbatori/test-run on our benchmarks database. Open source contributors will need to fork this database, and raise a pull request. You can read more about working with Dolt forks in our documentation. An abridged result sets can be seen below (taken from the SQL query here):
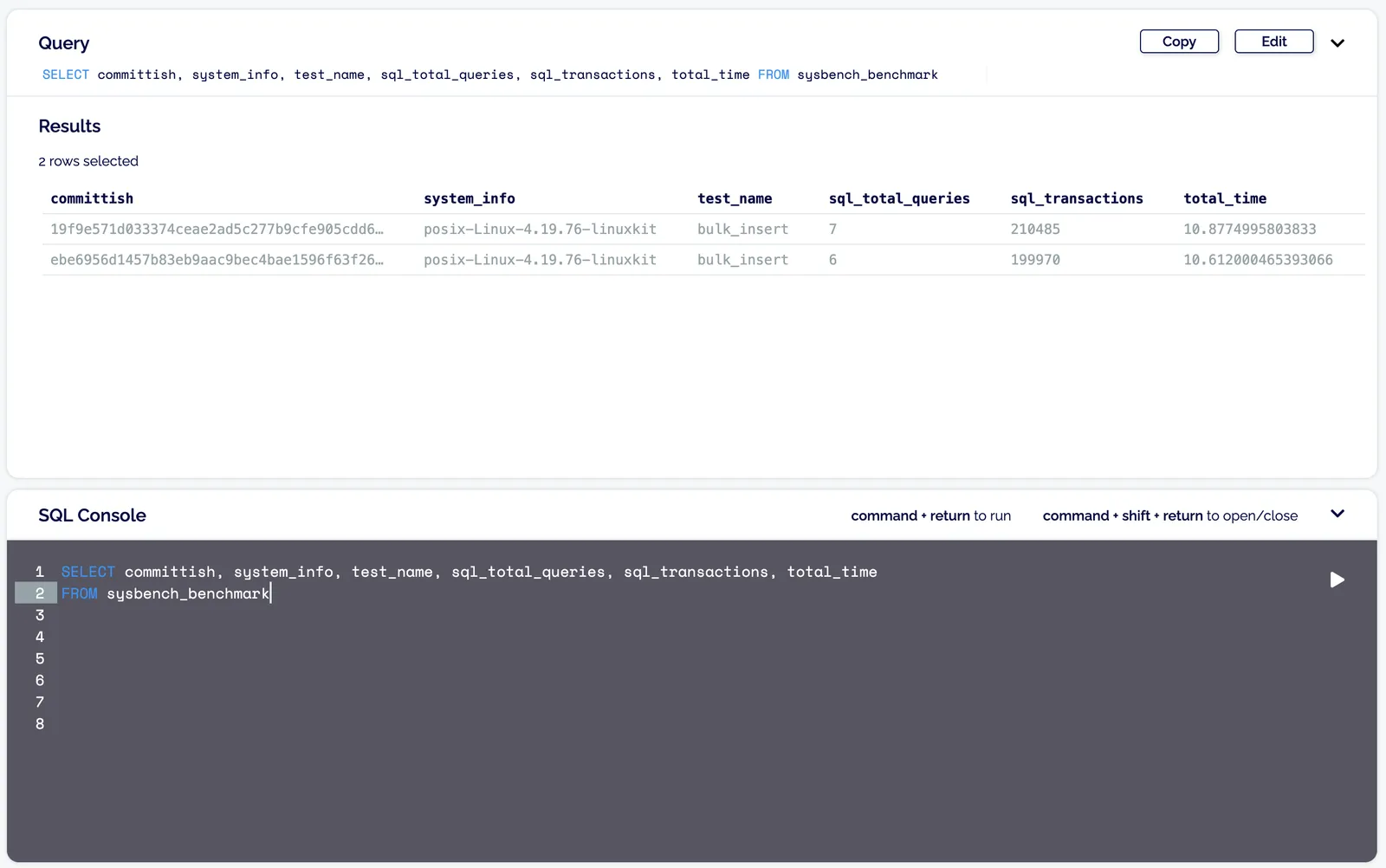
Clearly this change did not improve bulk insert performance meaningfully, but it illustrates that with a single command we were able to produce a robust comparison of a patch chosen by specifying two arbitrary commits.
Conclusion#
We started out with the need to benchmark the performance of Dolt, and observed that it was a hard problem to solve. Benchmarking in general is hard, and producing comparable benchmarks across time and hardware is devilishly hard. We also observed that without tooling it is a labor intensive and error prone process.
We spent this post reviewing the architecture of our solution to this problem. Using Docker, Python, and some shell scripts, we provided Dolt contributors with a way to do relatively robust performance benchmarking on their changes in a way that does a reasonable job of achieving hardware isolation, all in one command.
In the near future we will publish a follow up diving into the custom benchmarks we are building to tease out performance issues with Dolt, as well as providing more transparency to our current and prospective customers.