

Background#
An explosion of data driven products and business processes is creating an urgent need for best practices to ensure data reaching end users is high quality. This data could be in the form of machine learning models, combining upstream data sources to deliver “data products,” or more generally any way that public and third party data makes their way to end users. Data quality is now becoming a key pillar of product quality.
Great Expectations (GE) is an open source library designed to meet this need. GE is designed for validating, documenting, and profiling your data. Users define expectations about a data source, and validate those expectations as new data arrives. Dolt is a version controlled SQL database that combines a familiar query interface with Git-like features for managing a full version history of schema and data. This post shows how Dolt and GE form a potent combination for identifying and validating new batches of data.
Dolt’s version control features are made possible by a commit graph storage layer that allows users to associate any state of the database with a commit hash. By appending a single DOLT_COMMIT call to their SQL writes and updates the entire write is associated with a commit hash, or branch. Every row written or updated can then easily be retrieved for validation, no schema design required. This is also true for schema changes. GE in turn can run tests and validation against these updated rows using a simple SQL query to retrieve the batch.
Again, no schema design is required to achieve this. No longer are users forced to choose between slow and clunky data checks against an entire data set, potentially unreliable sampling, or expensive to design and maintain schemas that support versioning in traditional databases.
We will start by examining why building version control into existing databases is expensive, before introducing Dolt as a potential solution.
Batch#
Digging into batches, there are a few possibilities for what kind of schema designs are needed to capture batches that depend on how the data is being published:
- append only, meaning appending a timestamp (if one isn’t present) will make easy to identify batches
- time series, but where values are restated, meaning that an additional schema elements are required to capture versions when a record is updated
- restatement, meaning the entire datasets is restated (quite common, especially for public data), again necessitating schema design to achieve versioning
This range of scenarios means that when designing tools for ingesting and validating data, data engineering teams need to actively understand the nature of each data source, and make proactive schema design choices in order to make “batches” available for testing in a tool like GE.
Let’s see how Dolt removes the schema design challenge here, making easier to adopt tools like GE for data ingestion.
Introducing Dolt#
In the introduction we described Dolt as a “SQL database with Git-like version control features.” What that means in practice is that Dolt is SQL database with a commit-graph like storage layer that associates every committed state of the database with a commit hash. Users can point branches at those hashes to provide convenient names for versions. To make this practically useful the entire commit graph, including cell level diffs, are exposed in SQL, which is implemented as a superset of the MySQL dialect.
This means that for users to achieve cell level diffs on versions of their data the only required change is adding DOLT_COMMIT call to SQL writes. Taking inspiration from best practices for source code testing, the setup looks something like this?
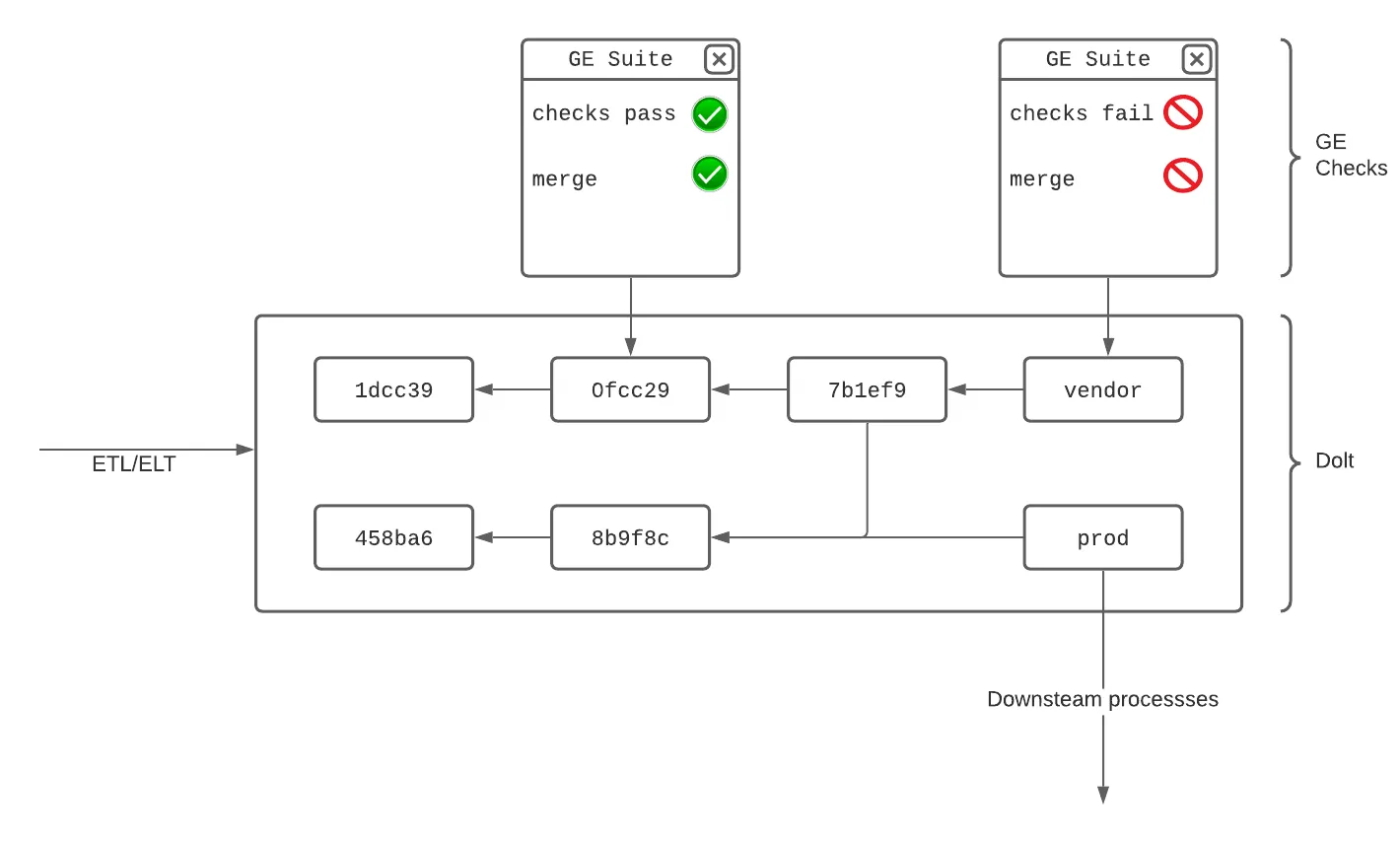
In this setup a GE suite is taking on the role of a unit or integration test suite. Dolt is making this possible by exposing data differences to be tested.
Example#
GE’s documentation provides a helpful example in a tutorial. It provides two files, one for January and one for February, containing New York City taxi trip data. The example shows how to calibrate an initial set of expectations on the January file and run the resulting expectations suite on the February file.
Let’s walk through the example where instead of CSV files, the upstream data is in Dolt. Incremental writes are made to the vendor branch for validation before merging in to prod, as described in the previous section. First run the following commands to clone the repository containing the GE examples, and install GE via pip:
$ pip install great_expectations
$ git clone https://github.com/superconductive/ge_tutorialsThe data files mentioned above can be found in ge_tutorials/data:
$ ls -ltr ge_tutorials/data
total 3760
-rw-r--r-- 1 you staff 954456 Jun 11 14:54 yellow_tripdata_sample_2019-01.csv
-rw-r--r-- 1 you staff 966571 Jun 11 14:54 yellow_tripdata_sample_2019-02.csvNext let’s install Dolt, and ingest them into a versioned table.
Install Dolt#
Before we get going, let’s create a Dolt database using the sample data from the example to emulate a production setting where we are ingesting third party data onto a branch. Before doing any of this you need a copy of Dolt, which is easy on Mac:
$ brew install doltOr if you don’t use Homebrew, or are on another *nix system:
$ sudo bash -c 'curl -L https://github.com/dolthub/dolt/releases/latest/download/install.sh | sudo bash'You can find more installation options, including Windows, in our documentation.
Ingest Data#
If you’re feeling lazy, you can just clone the data from a DoltHub repository and skip to the next section, noting that we add checkout call to create local pointers to the remote branches we will use in the demo:
$ dolt clone dolthub/ge-taxi-demo
$ dolt checkout vendor && dolt checkout prodFor readers who want to learn how to import data into Dolt, let’s start from scratch. Writing data into Dolt is much simpler than other databases, and schema inference is pretty mature. First create a new database:
$ mkdir ge-taxi-demo && cd ge-taxi-demo
$ dolt init
Successfully initialized dolt data repository.Now import a data file to a Dolt branch called prod:
$ dolt checkout -b prod
Switched to branch 'prod'
$ dolt branch
master
* prod
$ dolt table import --pk pickup_datetime,dropoff_datetime -c trip_data ~/ge_tutorials/data/yellow_tripdata_sample_2019-01.csv
Rows Processed: 10000, Additions: 10000, Modifications: 0, Had No Effect: 0
Import completed successfully.Next, create a commit to associate with this state of the database:
$ dolt add trip_data && dolt commit -m 'Added first cut of trip data'
commit 1s61u4rbbd26u0tlpdhb46cuejd1dogj
Author: oscarbatori <oscarbatori@gmail.com>
Date: Mon Jun 14 13:52:58 -0400 2021
Added first cut of trip data
Next let’s load the second data file to a branch called vendor:
$ dolt checkout -b vendor
Switched to branch 'vendor'
$ dolt table import -u trip_data ~/Documents/ge_tutorials/data/yellow_tripdata_sample_2019-02.csv
Rows Processed: 10000, Additions: 10000, Modifications: 0, Had No Effect: 0
Import completed successfully.
$ dolt add trip_data && dolt commit -m 'incremental write for 2019-02'
commit 3030evntp7ghv0b8m01u7nmfobs9vujm
Author: oscarbatori <oscarbatori@gmail.com>
Date: Mon Jun 14 13:58:07 -0400 2021
incremental write for 2019-02
We now have a Dolt database with two branches, vendor and prod that emulate our production data ingestion scenario.
GE Tutorial with Dolt#
We are now ready to actually initialize and build the GE suite and start running it against our database of taxi data. Since Dolt is a SQL database, and GE interacts with it via SQL Alchemy, the first step is simple, a single command to stand up Dolt SQL Server:
$ pwd
$HOME/ge-taxi-demo
$ dolt branch
master
* prod
vendor
$ dolt sql-server
Starting server with Config HP="localhost:3306"|U="root"|P=""|T="28800000"|R="false"|L="info"
INFO: NewConnection: client 1
INFO: audit trail
INFO: ConnectionClosed: client 1Without configuration Dolt runs as root with an empty password. We can now initialize a GE suite:
$ pwd
$HOME/ge-taxi-demo
$ great_expectations init
Using v2 (Batch Kwargs) API
___ _ ___ _ _ _
/ __|_ _ ___ __ _| |_ | __|_ ___ __ ___ __| |_ __ _| |_(_)___ _ _ ___
| (_ | '_/ -_) _` | _| | _|\ \ / '_ \/ -_) _| _/ _` | _| / _ \ ' \(_-<
\___|_| \___\__,_|\__| |___/_\_\ .__/\___\__|\__\__,_|\__|_\___/_||_/__/
|_|
~ Always know what to expect from your data ~
Let's configure a new Data Context.
First, Great Expectations will create a new directory:
great_expectations
|-- great_expectations.yml
|-- expectations
|-- checkpoints
|-- notebooks
|-- plugins
|-- .gitignore
|-- uncommitted
|-- config_variables.yml
|-- documentation
|-- validations
OK to proceed? [Y/n]: y
The next step prompt asks us to configure a data source, which we do via a SQL Alchemy connection string:
Would you like to configure a Datasource? [Y/n]: y
What data would you like Great Expectations to connect to?
1. Files on a filesystem (for processing with Pandas or Spark)
2. Relational database (SQL)
: 2
Which database backend are you using?
1. MySQL
2. Postgres
3. Redshift
4. Snowflake
5. BigQuery
6. other - Do you have a working SQLAlchemy connection string?
: 6
Give your new Datasource a short name.
[my_database]: ge-taxi-demo
Next, we will configure database credentials and store them in the `ge-taxi-demo` section
of this config file: great_expectations/uncommitted/config_variables.yml:
What is the url/connection string for the sqlalchemy connection?
(reference: https://docs.sqlalchemy.org/en/latest/core/engines.html#database-urls)
: mysql+mysqlconnector://root@127.0.0.1:3306/ge_taxi_demo
Attempting to connect to your database. This may take a moment...
Great Expectations will now add a new Datasource 'ge-taxi-demo' to your deployment, by adding this entry to your great_expectations.yml:
ge-taxi-demo:
credentials: ${ge-taxi-demo}
data_asset_type:
class_name: SqlAlchemyDataset
module_name: great_expectations.dataset
class_name: SqlAlchemyDatasource
module_name: great_expectations.datasource
The credentials will be saved in uncommitted/config_variables.yml under the key 'ge-taxi-demo'
Would you like to proceed? [Y/n]: y
Great Expectations connected to your database!
================================================================================Success, GE has connected to Dolt via SQL Alchemy! Let’s step through a few more prompts to get our initial set of checks defined.
Would you like to profile new Expectations for a single data asset within your new Datasource? [Y/n]: y
You have selected a datasource that is a SQL database. How would you like to specify the data?
1. Enter a table name and schema
2. Enter a custom SQL query
3. List all tables in the database (this may take a very long time)
: 3
Warning: If you have a large number of tables in your datasource, this may take a very long time.
Would you like to continue? (y, n): y
Which table would you like to use? (Choose one)
1. trip_data (table)
: 1
Name the new Expectation Suite [trip_data.warning]: ge_taxi_demo
Great Expectations will choose a couple of columns and generate expectations about them
to demonstrate some examples of assertions you can make about your data.
Great Expectations will store these expectations in a new Expectation Suite 'ge_taxi_demo' here:
file:///Users/oscarbatori/Documents/dolt-dbs/ge-taxi-demo/great_expectations/expectations/ge_taxi_demo.json
Would you like to proceed? [Y/n]: y
Generating example Expectation Suite...
Done generating example Expectation Suite
================================================================================
Would you like to build Data Docs? [Y/n]: y
The following Data Docs sites will be built:
- local_site: file:///Users/oscarbatori/Documents/dolt-dbs/ge-taxi-demo/great_expectations/uncommitted/data_docs/local_site/index.html
Would you like to proceed? [Y/n]: y
Building Data Docs...
Done building Data Docs
Would you like to view your new Expectations in Data Docs? This will open a new browser window. [Y/n]: y
================================================================================
Congratulations! Great Expectations is now set up.That represents the straight forward part of the tutorial. To recap we:
- loaded the sample data into a
prodbranch and then made an incremental write to avendorbranch to simulate a production setting - we stood up Dolt SQL Server
- we initialized GE and pointed it at the database server
We now need to configure GE to examine the next batch of data. We can easily see that batch using dolt diff --summary, which shows the describes the incremental. First we check out the vendor branch:
$ dolt checkout vendor && dolt branch
Switched to branch 'vendor'
master
prod
* vendor
$ dolt diff --summary prod
diff --dolt a/trip_data b/trip_data
--- a/trip_data @ dehf33s9cftu0ops03u8ihj6q65fct7v
+++ b/trip_data @ a6glmt38jdqpu741jf6cfdddlb5nig68
10,000 Rows Unmodified (100.00%)
10,000 Rows Added (100.00%)
0 Rows Deleted (0.00%)
0 Rows Modified (0.00%)
0 Cells Modified (0.00%)
(10,000 Entries vs 20,000 Entries)In order to run our newly created GE suite against this new set of rows we need to tell GE how to identify it by defining a “batch”. Let’s see how to do that in Dolt SQL. Recall that Dolt associates every committed state of the database with commit hash. That means given our branches vendor and prod we can use dolt_diff_trip_data to query only the rows touched by our update:
select
to_vendor_id as vendor_id,
to_pickup_datetime as pickup_datetime,
to_dropoff_datetime as dropoff_datetime,
to_passenger_count as passenger_count,
to_trip_distance as trip_distance,
to_rate_code_id as rate_code_id,
to_store_and_fwd_flag as store_and_fwd_flag,
to_pickup_location_id as pickup_location_id,
to_dropoff_location_id as dropoff_location_id,
to_payment_type as payment_type,
to_fare_amount as fare_amount,
to_extra as extra,
to_mta_tax as mta_tax,
to_tip_amount as tip_amount,
to_tolls_amount as tolls_amount,
to_improvement_surcharge as improvement_surcharge,
to_total_amount as total_amount,
to_congestion_surcharge as congestion_surcharge
from
dolt_diff_trip_data
where
to_commit = hashof('vendor')We can use this query to identify our batch, and thus configure GE to always validate the difference between our prod and vendor branches. These data checks can then act as a “gate” on merging newly published data into production, thus preventing errors from moving downstream.
Defining a Batch#
Our next batch will be defined using the query above. We can run the following command to launch a Jupyter notebook:
$ great_expectations suite edit ge_taxi_demoTo make clear what has changed, we have commented out the initial definition of the batch that GE provided:
import datetime
import great_expectations as ge
import great_expectations.jupyter_ux
from great_expectations.checkpoint import LegacyCheckpoint
from great_expectations.data_context.types.resource_identifiers import (
ValidationResultIdentifier,
)
context = ge.data_context.DataContext()
# Feel free to change the name of your suite here. Renaming this will not
# remove the other one.
expectation_suite_name = "ge_taxi_demo"
suite = context.get_expectation_suite(expectation_suite_name)
suite.expectations = []
# First batch
# batch_kwargs = {
# "data_asset_name": "trip_data",
# "datasource": "ge-taxi-demo",
# "limit": 1000,
# "schema": "ge_taxi_demo",
# "table": "trip_data",
# }
query = '''
select
to_vendor_id as vendor_id,
to_pickup_datetime as pickup_datetime,
to_dropoff_datetime as dropoff_datetime,
to_passenger_count as passenger_count,
to_trip_distance as trip_distance,
to_rate_code_id as rate_code_id,
to_store_and_fwd_flag as store_and_fwd_flag,
to_pickup_location_id as pickup_location_id,
to_dropoff_location_id as dropoff_location_id,
to_payment_type as payment_type,
to_fare_amount as fare_amount,
to_extra as extra,
to_mta_tax as mta_tax,
to_tip_amount as tip_amount,
to_tolls_amount as tolls_amount,
to_improvement_surcharge as improvement_surcharge,
to_total_amount as total_amount,
to_congestion_surcharge as congestion_surcharge
from
dolt_diff_trip_data
where
to_commit = hashof('vendor')
'''
batch_kwargs = {
"datasource": "ge-taxi-demo",
"query": query
}
batch = context.get_batch(batch_kwargs, suite)
batch.head()After running through the rest of the notebook cells to leave our suite unchanged, we can run our checks with this new batch, and update our data documentation:
batch.save_expectation_suite(discard_failed_expectations=False)
results = LegacyCheckpoint(
name="_temp_checkpoint",
data_context=context,
batches=[
{
"batch_kwargs": batch_kwargs,
"expectation_suite_names": [expectation_suite_name]
}
]
).run()
validation_result_identifier = results.list_validation_result_identifiers()[0]
context.build_data_docs()
context.open_data_docs(validation_result_identifier)The demo is configured to fail on the second batch, illustrating how GE alerts users to problems occurring in incremental writes. Our modified demo also produces a failure:
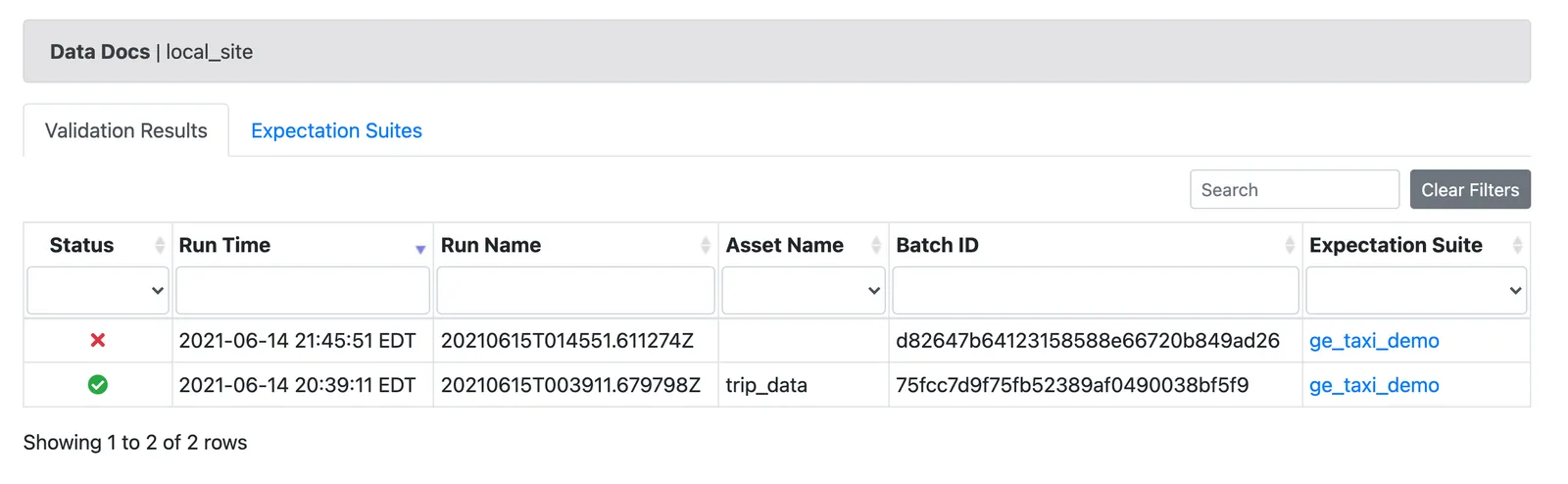
Conclusion#
In this demo we showed how to elevate the quality of your data ingestion practices by combining Dolt with GE, a library for validating, documenting, and profiling your data. Specifically we ran through the GE introductory demo replacing file based storage with Dolt’s commit graph backed SQL database for versioning tabular data.
With Dolt it was trivial to identify batches, making schema design and maintenance unnecessary. No snapshot configuration was required for rolling forwards and backwards in time, Dolt does these things instantly. Diffs provide transparency into the causes of failing checks. These native features make it easier to adopt best practices, such as GE checks. With commit graph based storage layer provided by Dolt the kind of best practices incubated in a CI/CD context become a natural choice for protecting your production processes from data errors, and ultimately lowering operational overhead and elevating quality.