
Since its launch in 2008, GitHub has catalyzed the open source software world and accelerated the culture of software collaboration. Source control was an old idea at that point, but GitHub offered a centralized place to discover and collaborate on new projects. We created DoltHub to foster that same collaboration around open data sets, and now DoltHub allows exploration of those dataset via SQL queries on the web.
Let’s use the baseball-databank repository to demonstrate. The initial view shows the repository’s tables on the left and the data in the center, but if we want to understand the usefulness of this dataset we can do better than scrolling through its rows. Let’s say we want to do a simple correlation analyzing the relationship between player salary and batting average. We’ll start by checking what years we have data for.
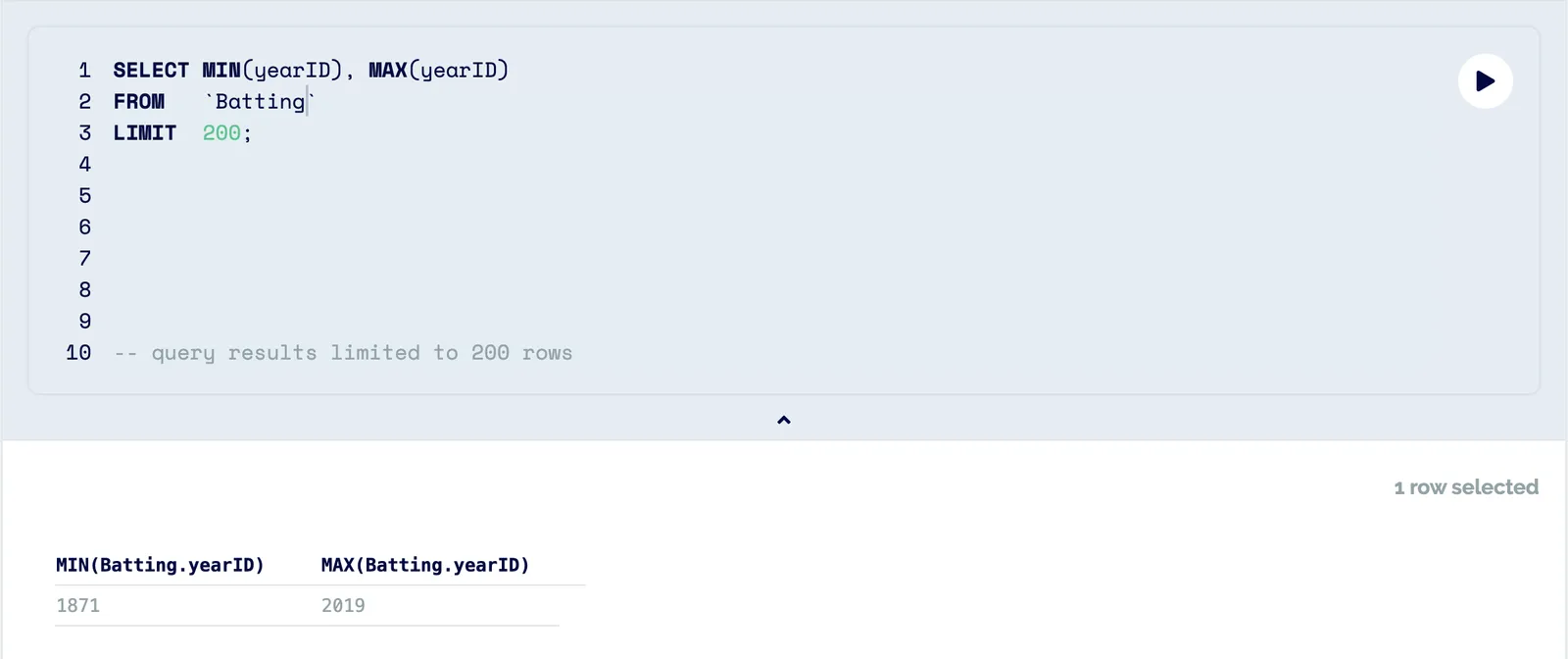
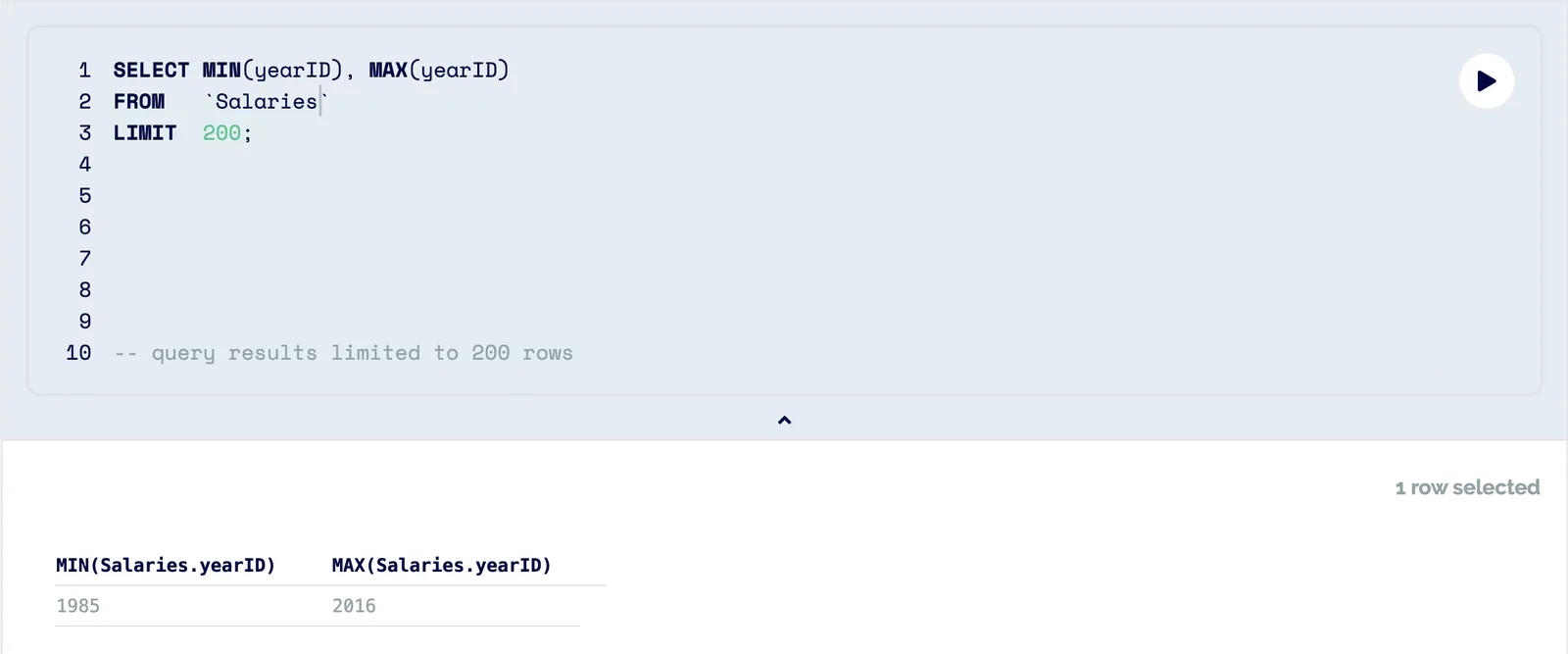
Next, we can do some sanity checks to ensure we trust our source.
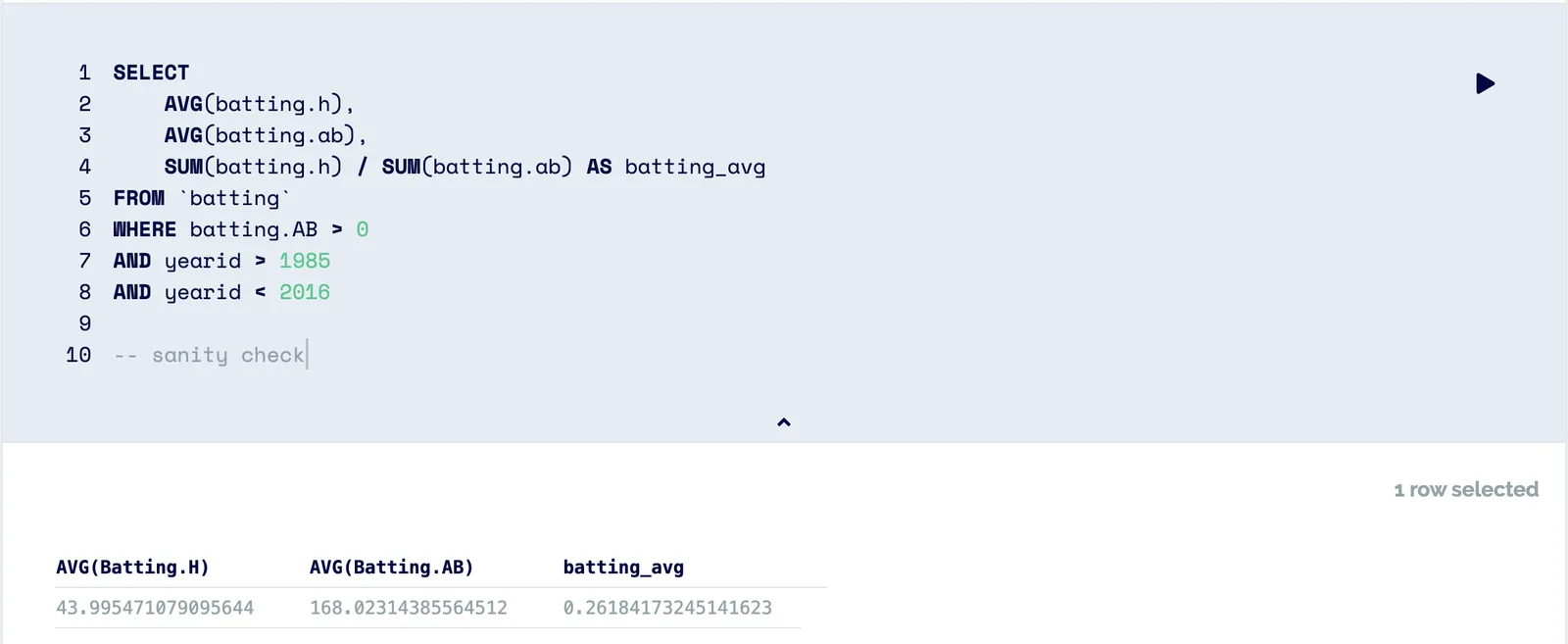
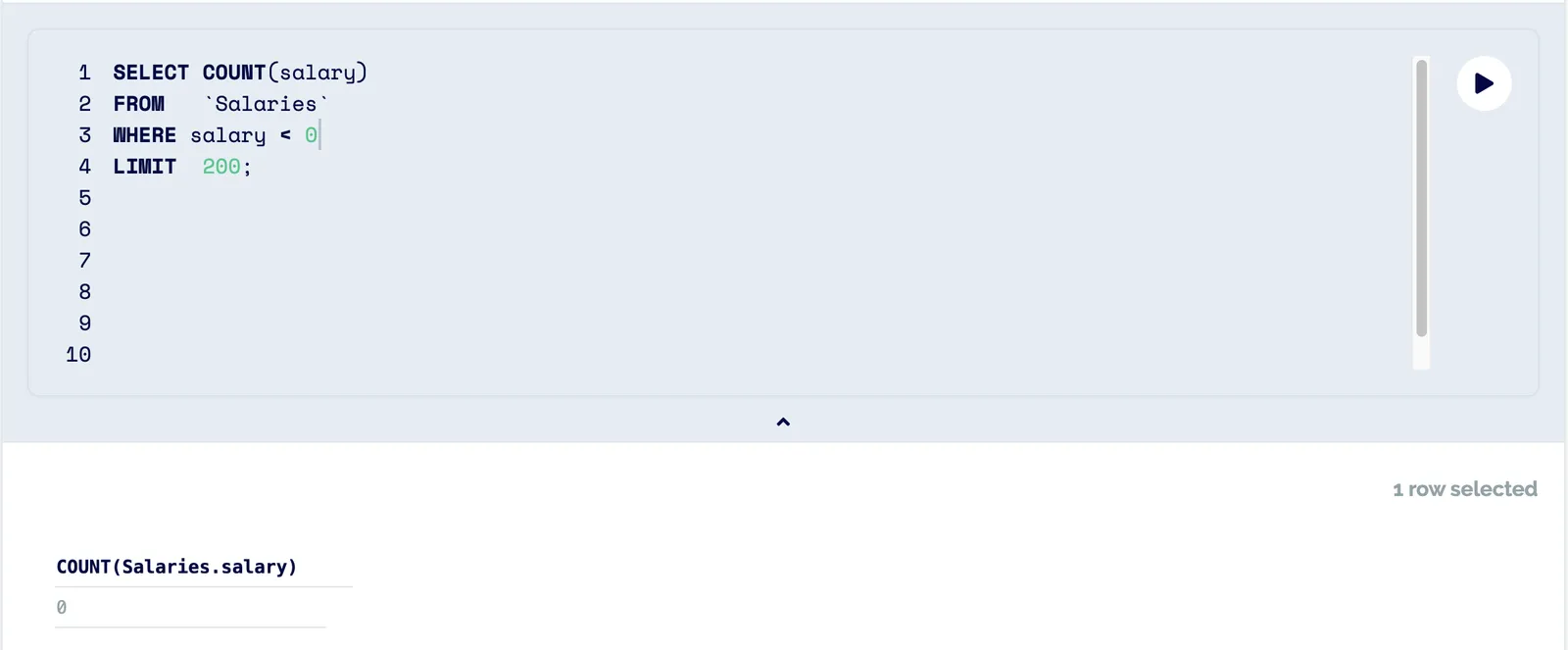
It seems that everything is in order. At this point we can grab the data and perform our analysis.
If you haven’t done so already, install Dolt
> sudo curl -L https://github.com/dolthub/dolt/releases/latest/download/install.sh | sudo bashand clone the repository
> dolt clone dolthub/baseball-databankRows and cells in isolation don’t tell the full story. Queries on the web offer a lightweight way to explore the shape of the dataset, and decide whether it’s worth cloning locally.
Hosting a service that can query any repository on DoltHub presented unique challenges in development. Hosting a traditional
database instance per repository is prohibitively expensive. Cloning repositories on-demand would introduce server state
and would scale poorly. Thankfully Dolt’s storage layer is immutable and content-addressable, meaning that the we can
fetch the correct subset of data on-demand from the remote S3 chunk store. Queries are automatically fetched from the HEAD
of each branch, so collaborator’s changes will be reflected on DoltHub as soon as they dolt push.
Currently, queries are limited to read-only select, describe and show statements. In the future we will extend this
functionality to querying diffs and generating pull requests from write queries. We’ve also placed limits on the compute
time and the number of rows returned by a single query. Once you know what data is available, you can easily get the full
dataset including history with dolt clone.