
Dolt is Git for data. We built Dolt to help teams collaborate on data sets using the forking, branching, and merging workflows that Git popularized. These workflows are what enable software engineers to collaborate on source code, and they’re what enable data engineers to collaborate on datasets. And besides making it possible for multiple data scientists to build a dataset without stomping on each other’s edits, a fully versioned dataset can be audited. You can inspect the history for the value of every cell in every table: who put it there, what their commit message was, what other values changed in that same commit.
So far, we’ve been focused on providing these basic Git workflows for Dolt databases, and on exposing the same audit information through the SQL interface via special system tables. Today, we’re announcing a major new dataset collaboration feature that has no real analogue in Git: saved queries.
Saved queries: a simple example#
To demonstrate this feature, let’s create a saved query on DoltHub’s Coronavirus dataset.
To start, we’ll clone the dataset so we can run SQL on it:
% dolt clone dolthub/corona-virus
% cd corona-virusNext, we need an interesting query we want to contribute to the dataset. The question we want to answer is: which reporting location has the worst mortality rate to date? Here’s a query that answers that question, and some results:
dolt sql -q "select *, deaths/(cases + .01) as mortality_rate from current order by mortality_rate desc limit 20;"
+----------------+--------------+--------------+-------+--------+-----------+----------------------+
| country | state | last updated | cases | deaths | recovered | mortality_rate |
+----------------+--------------+--------------+-------+--------+-----------+----------------------+
| Philippines | | 2020-02-12 | 3 | 1 | 1 | 0.33222591362126247 |
| Iran | | 2020-02-23 | 43 | 8 | 0 | 0.1860032550569635 |
| France | | 2020-02-15 | 12 | 1 | 4 | 0.08326394671107411 |
| Mainland China | Hubei | 2020-02-23 | 64084 | 2346 | 15343 | 0.03660819602268959 |
| Taiwan | Taiwan | 2020-02-23 | 28 | 1 | 2 | 0.035701535166012134 |
| Mainland China | Hainan | 2020-02-23 | 168 | 5 | 106 | 0.0297601333253973 |
| Hong Kong | Hong Kong | 2020-02-23 | 74 | 2 | 11 | 0.02702337521956492 |
| Mainland China | Xinjiang | 2020-02-23 | 76 | 2 | 28 | 0.026312327325351926 |
| Mainland China | Heilongjiang | 2020-02-23 | 480 | 12 | 222 | 0.024999479177517134 |
| Mainland China | Tianjin | 2020-02-23 | 135 | 3 | 81 | 0.022220576253610846 |
| Mainland China | Gansu | 2020-02-23 | 91 | 2 | 78 | 0.021975607076145477 |
| Italy | | 2020-02-23 | 155 | 3 | 2 | 0.019353590090961874 |
| Mainland China | Hebei | 2020-02-23 | 311 | 6 | 219 | 0.01929198418057297 |
| Mainland China | Henan | 2020-02-23 | 1271 | 19 | 868 | 0.014948741551994084 |
| Mainland China | Guizhou | 2020-02-23 | 146 | 2 | 102 | 0.013697691938908295 |
| Mainland China | Yunnan | 2020-02-23 | 174 | 2 | 115 | 0.01149359232228033 |
| Mainland China | Jilin | 2020-02-23 | 91 | 1 | 54 | 0.010987803538072738 |
| Mainland China | Chongqing | 2020-02-23 | 575 | 6 | 335 | 0.010434601137371524 |
| Mainland China | Beijing | 2020-02-23 | 399 | 4 | 189 | 0.010024811408235383 |
| South Korea | | 2020-02-23 | 602 | 6 | 18 | 0.009966611850301491 |
+----------------+--------------+--------------+-------+--------+-----------+----------------------+SQL note: adding .01 to the cases column prevents division by zero
errors for places without any deaths, and also results in the entire
expression being evaluated as a float instead of an integer.
This is a pretty interesting result that I want to share with my
teammates. So I can save it to the
Dolt database by using the
‑‑save flag when I run the query:
% dolt sql -q \
"select *, deaths/(cases + .01) as mortality_rate from current order by mortality_rate desc limit 20;" \
--save "Mortality rates" -m "Mortality rates for every place with reported cases"Running the query with these extra flags will still execute and print
results like normal, but now when I run dolt status I notice that
there’s a modified table in the working set:
% dolt status
On branch master
Changes not staged for commit:
(use "dolt add <table>" to update what will be committed)
(use "dolt checkout <table>" to discard changes in working directory)
modified: dolt_query_catalog(The table is modified because this repository already had saved
queries. If this is the first query saved for the repo, you would see
the dolt_query_catalog table being added, not modified).
Let’s examine how the repository changed as a result of adding a new saved query:
% dolt diff
diff --dolt a/dolt_query_catalog b/dolt_query_catalog
--- a/dolt_query_catalog @ cll5juqgufk982g2gdaqn0p2h7f2nugi
+++ b/dolt_query_catalog @ gf7848pisd0ek5bif1255b4bkmo72s8m
+-----+--------------+---------------+-----------------+------------------------------------------------------------------------------------------------------+------------------------------------------------------+
| | id | display_order | name | query | description |
+-----+--------------+---------------+-----------------+------------------------------------------------------------------------------------------------------+------------------------------------------------------+
| + | a129ff983944 | 7 | Mortality rates | select *, deaths/(cases + .01) as mortality_rate from current order by mortality_rate desc limit 20; | Mortality rates for every place with reported cases. |
+-----+--------------+---------------+-----------------+------------------------------------------------------------------------------------------------------+------------------------------------------------------+We can commit changes to this table and push to master, just like any other data change:
% dolt add .
% dolt commit -m "Added a saved query."Viewing saved queries on DoltHub#
Saving queries to repositories is cool, but the real magic happens when you push those changes back to the DoltHub origin and view the repo on the web. If you visit the coronavirus dataset on DoltHub, you’ll notice a new section in the left pane of the window:
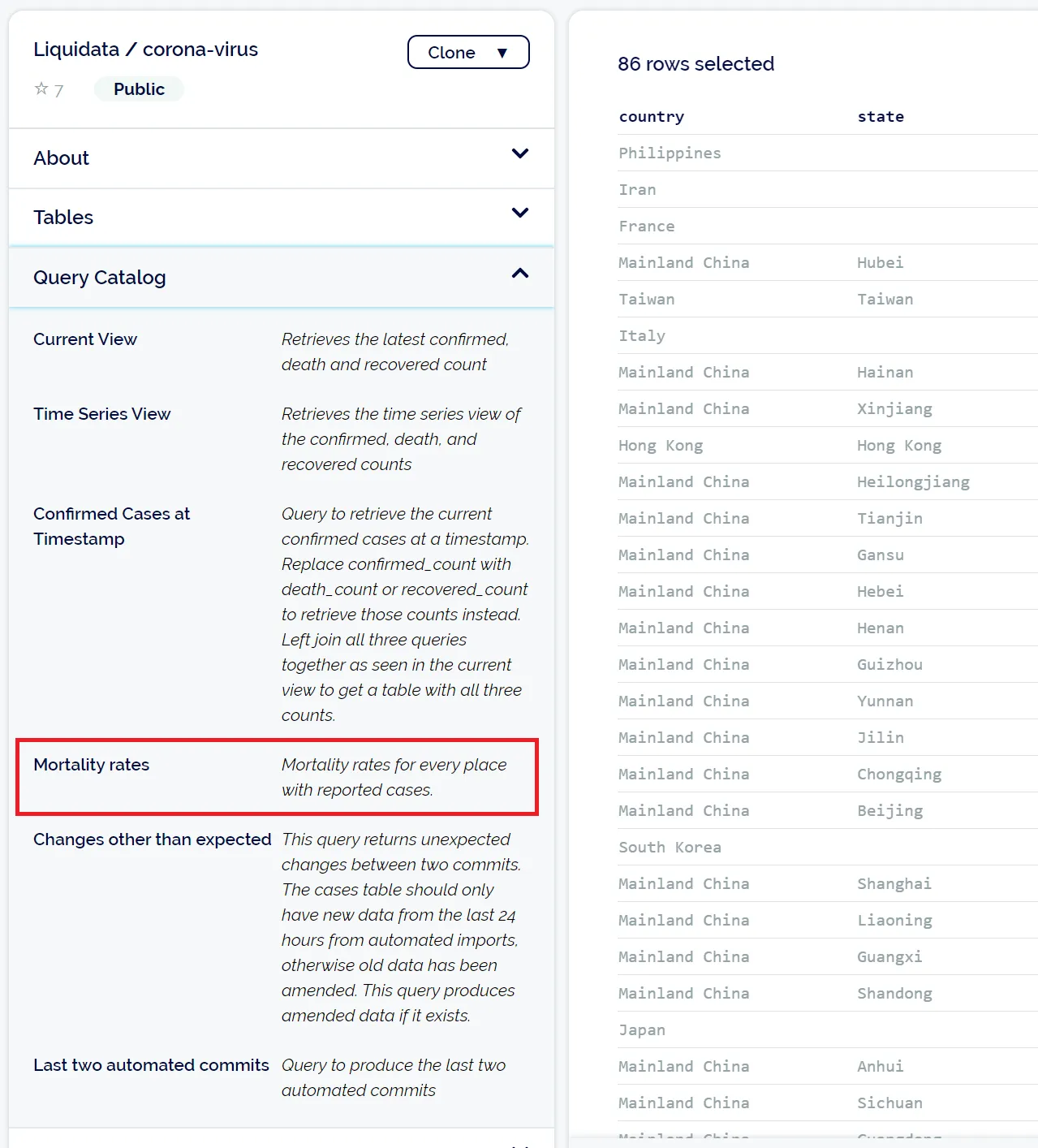
Clicking on any saved query in DoltHub immediately executes it and displays the results. To share the results of these or any other queries, just copy the URL from your browser like with any other page. Here’s a direct link to the mortality rate query results.
Editing saved queries#
Because saved queries are stored in the dolt_query_catalog system
table, editing saved queries is as simple as issuing SQL
statements. Let’s say that I create a view for my new saved query like
so:
create view mortality_rates as
select *, deaths/(cases + .01) as mortality_rate
from current order by mortality_rate desc;Now that I have this view, I want to update my saved query to reflect
the new results. To do this, first I find it in the
dolt_query_catalog table:
select * from dolt_query_catalog where query like '%mortality%';
+--------------+---------------+-----------------+---------------------------------------------------------------------------------------------+------------------------------------------------------+
| id | display_order | name | query | description |
+--------------+---------------+-----------------+---------------------------------------------------------------------------------------------+------------------------------------------------------+
| f0a8983a8c35 | 4 | Mortality rates | select *, deaths/(cases + .01) as mortality_rate from current order by mortality_rate desc; | Mortality rates for every place with reported cases. |
+--------------+---------------+-----------------+---------------------------------------------------------------------------------------------+------------------------------------------------------+Then I issue an update statement like so:
update dolt_query_catalog
set query = 'select * from mortality_rates'
where id = 'f0a8983a8c35';Note that if you’re following along at home, your id value will be
different — it’s randomly generated when a query is saved. Also note
that we could have accomplished this in a single UPDATE statement
with the where clause from the first SELECT, but that could
inadvertently update more rows if they included the word “mortality”,
so it’s safer with two queries.
Now when we run dolt status, we can see that two tables were modified:
% dolt status
On branch master
Changes not staged for commit:
(use "dolt add <table>" to update what will be committed)
(use "dolt checkout <table>" to discard changes in working directory)
modified: dolt_query_catalog
modified: dolt_schemasAnd if we run dolt diff, we can see exactly which rows changed:
% dolt diff
diff --dolt a/dolt_schemas b/dolt_schemas
--- a/dolt_schemas @ ff15tr0clb9l9gvej8b529nk0trkvu51
+++ b/dolt_schemas @ lorokt90da1ud98knp62vl9hmh4a696d
+-----+------+-----------------+--------------------------------------------------------------------------------------------+
| | type | name | fragment |
+-----+------+-----------------+--------------------------------------------------------------------------------------------+
| + | view | mortality_rates | select *, deaths/(cases + .01) as mortality_rate from current order by mortality_rate desc |
+-----+------+-----------------+--------------------------------------------------------------------------------------------+
diff --dolt a/dolt_query_catalog b/dolt_query_catalog
--- a/dolt_query_catalog @ i9jpi3qq06tiv002qb34hlg3v9epknfo
+++ b/dolt_query_catalog @ gf7848pisd0ek5bif1255b4bkmo72s8m
+-----+--------------+---------------+-----------------+---------------------------------------------------------------------------------------------+------------------------------------------------------+
| | id | display_order | name | query | description |
+-----+--------------+---------------+-----------------+---------------------------------------------------------------------------------------------+------------------------------------------------------+
| < | f0a8983a8c35 | 4 | Mortality rates | select *, deaths/(cases + .01) as mortality_rate from current order by mortality_rate desc; | Mortality rates for every place with reported cases. |
| > | f0a8983a8c35 | 4 | Mortality rates | select * from mortality_rates | Mortality rates for every place with reported cases. |
+-----+--------------+---------------+-----------------+---------------------------------------------------------------------------------------------+------------------------------------------------------+A couple final notes:
-
You can also use SQL
INSERTstatements to create new saved queries, although due to quoting it’s usually easier from the command line using the‑‑saveflag. -
The
display_orderfield will re-arrange the order queries appear on DoltHub -
The
descriptionfield (added by the-mflag) is optional, but it’s good practice to document your saved queries with it.
A less morbid example#
I don’t know about you, but all this talk about dying from coronavirus is really bringing me down. Honestly, it makes me want to get super, duper high. Luckily, we have a Dolt dataset that records the lab-tested potency of various strains of commercial recreational marijuana in Washington State. Let’s figure out what the strongest weed is:
doltsql> select test_strain, avg(thc_max) from tests where inventory_type = 'Flower Lot' group by 1 order by 2 desc limit 20;
+--------------------+--------------------+
| test_strain | AVG(tests.thc_max) |
+--------------------+--------------------+
| Liberty Haze 00016 | 37.80834 |
| Liberty Haze 00027 | 37.300564 |
| Liberty Haze 00022 | 36.47355 |
| Liberty Haze 00025 | 35.974540000000005 |
| BD_7_16-11-02 | 35.4394 |
| Kosher Tangie #8 | 34.7292 |
| Liberty Haze 00020 | 34.18342 |
| WIFI_8_16-09-02 | 33.5982 |
| Liberty Haze 00026 | 33.49863833333333 |
| Grape OG #2 | 32.995 |
| OREG_T6_16.04.27 | 32.62886666666667 |
| Tangie Land | 32.5347 |
| Bubba Kush 00010 | 32.485366666666664 |
| Fruity Pebbles OG | 32.4271 |
| Kosher Kush 00005 | 32.263335 |
| CANTELOPE | 31.7811 |
| Liberty Haze 00021 | 31.76712857142857 |
| Liberty Haze 00013 | 31.7639 |
| GGLU_T03_16.12.26 | 31.749850000000002 |
| WIFI25 x ACHEM | 31.7303 |
+--------------------+--------------------+Let’s go ahead and save that query (without the limit) for future reference:
dolt sql -q \
"select test_strain, avg(thc_max) from tests where inventory_type = 'Flower Lot' group by 1 order by 2 desc;" \
--save "Highest THC flower strains" \
-m "Flower strains ordered by their average THC measurement"And I’ll add another one for high-CBD strains:
dolt sql -q \
"select test_strain, avg(cbd_max) from tests where inventory_type = 'Flower Lot' group by 1 order by 2 desc;" \
--save "Highest CBD flower strains" \
-m "Flower strains ordered by their average CBD measurement"If coronavirus news has you freaked out, please refer to these results here and here.
Conclusion#
The query catalog is just the beginning of the social features we will be building for Dolt and DoltHub. Just for starters, soon we’ll let you suggest new saved queries from the web as a PR for the repository owner. We have a lot of other cool ideas, and we hope you’ll stick around on this blog as we announce them in the months to come. Download Dolt today to try it out yourself!