
We’re writing Dolt, the world’s first and only version-controlled SQL database. And we’ve been at it for a long time, over six years! We believe in the product more than ever, and new customers keep finding us and asking where we’ve been all their lives. It’s been a fun ride.
About a year ago Tim produced a timeline of the Dolt as a product and a company. Last week we realized that we were coming up on the tenth anniversary of the first commit in the Dolt codebase, made on June 2, 2015. Ten years ago today! So we figured now is a good time to update the timeline and talk about the journey that got us here.
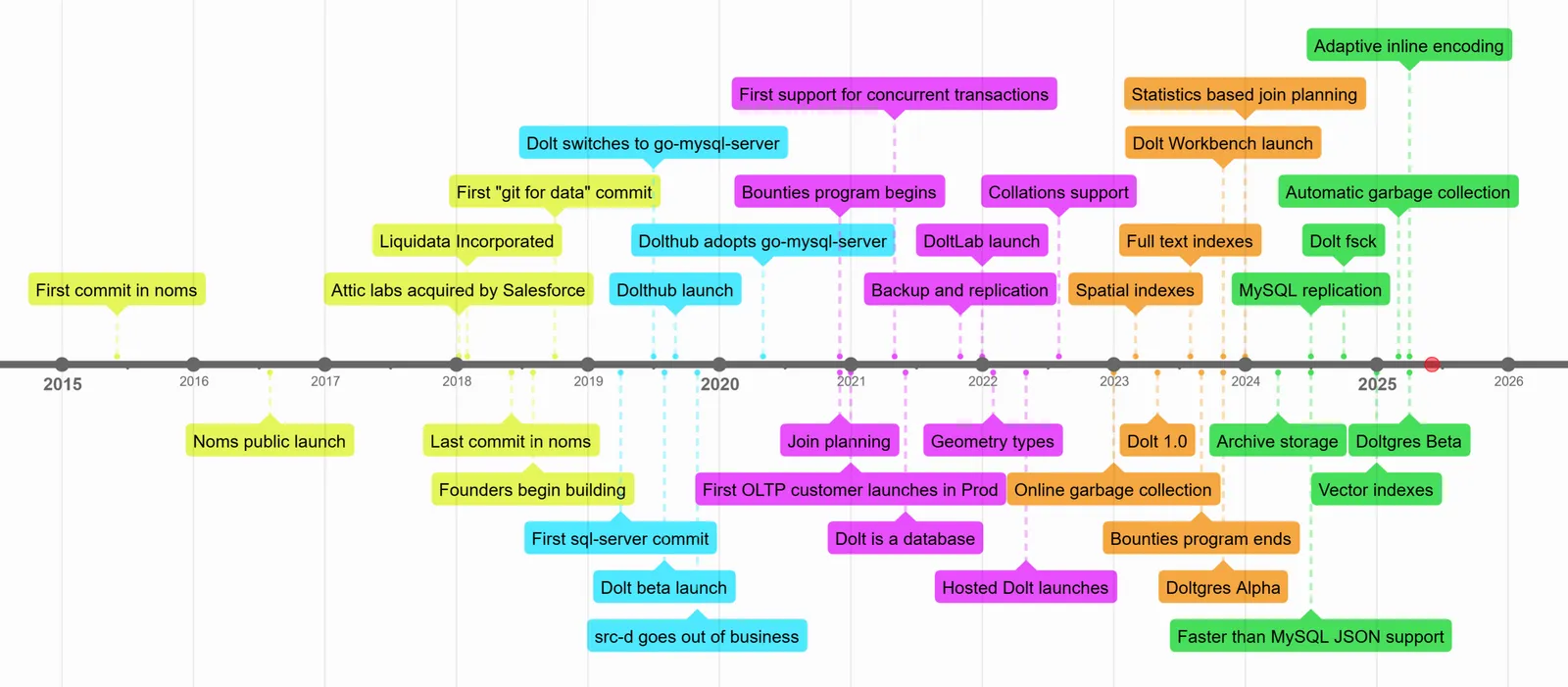
Tim’s timeline is written from the perspective of the CEO who takes money from investors and writes our paychecks. Mine is a bit more focused on the engineering and technology that made the product what it is today, so my view of things is a little different.
The early years: noms and the founding#
These events are colored yellow in the timeline.
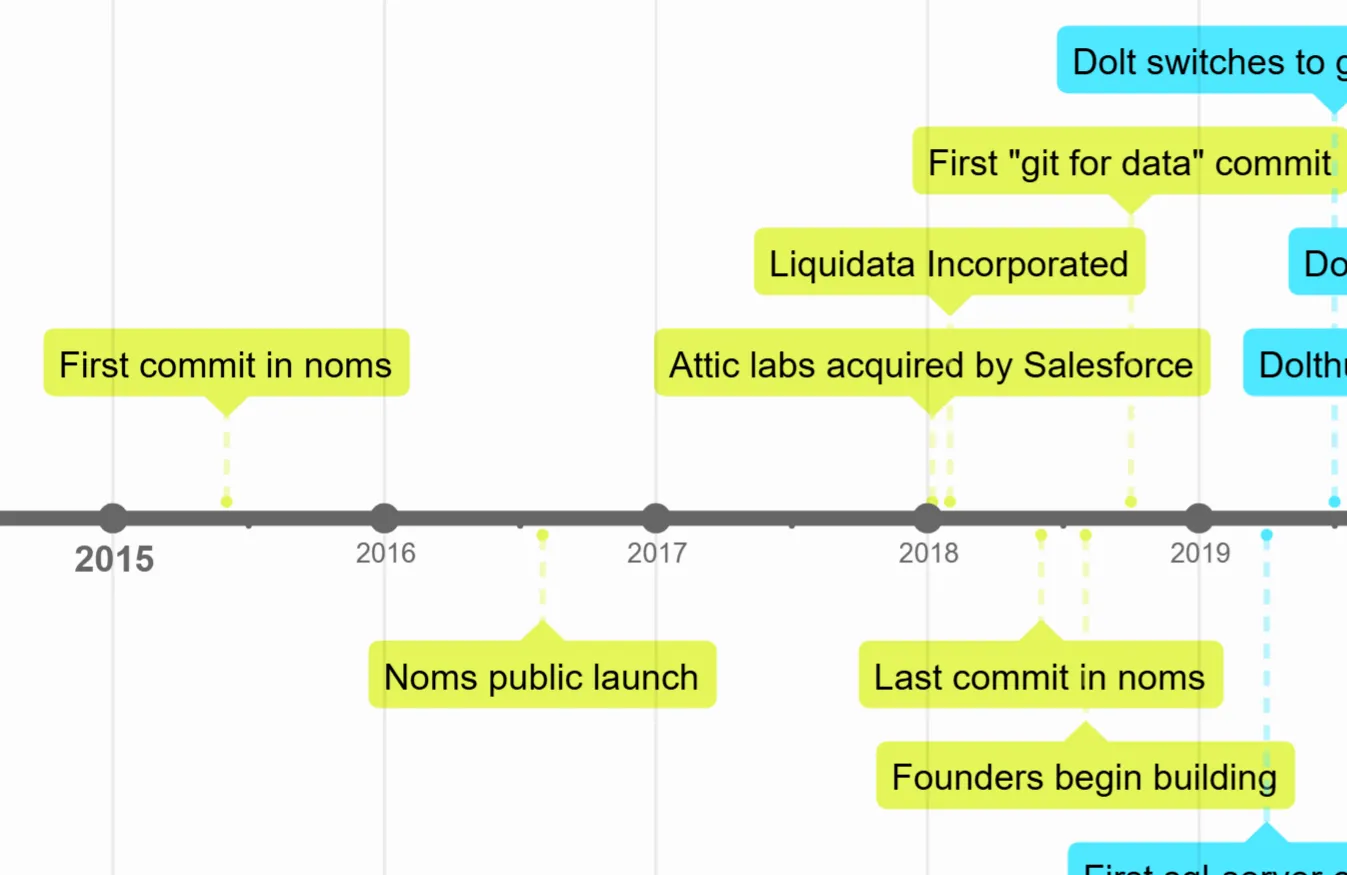
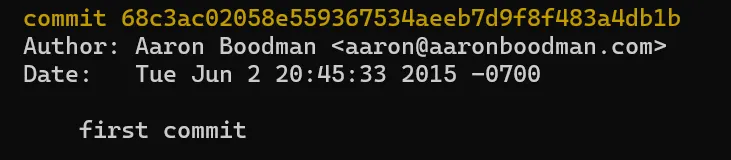
The event that started this all off was Aaron Boodman writing the first commit in the noms repository. He wrote an appropriate commit message.
As far as we can tell, noms is the world’s first implementation of a prolly
tree, the data structure that
powers Dolt and Doltgres. Prolly trees are what make structural sharing possible, making it
efficient for Dolt to store many snapshots of a database.

Noms was a no-SQL database that never found traction in the market, but it was a technically impressive product that led to an acquisition by Salesforce in 2018. This was right around the time that DoltHub’s three founders quit their jobs at Snap with plans to start a data marketplace company. The company was incorporated and started building in the summer of 2018.
They figured one of the first steps to getting a data marketplace off the ground was a tool to make
collaborating on and syncing datasets possible, something like git, but for data. They found noms
sitting unused with a compatible license, and over a weekend
Brian pounded out the first prototype for Dolt, with a command
line based on git. dolt was born.
Git for data and the beginnings of SQL functionality#
These events are colored blue in the timeline.
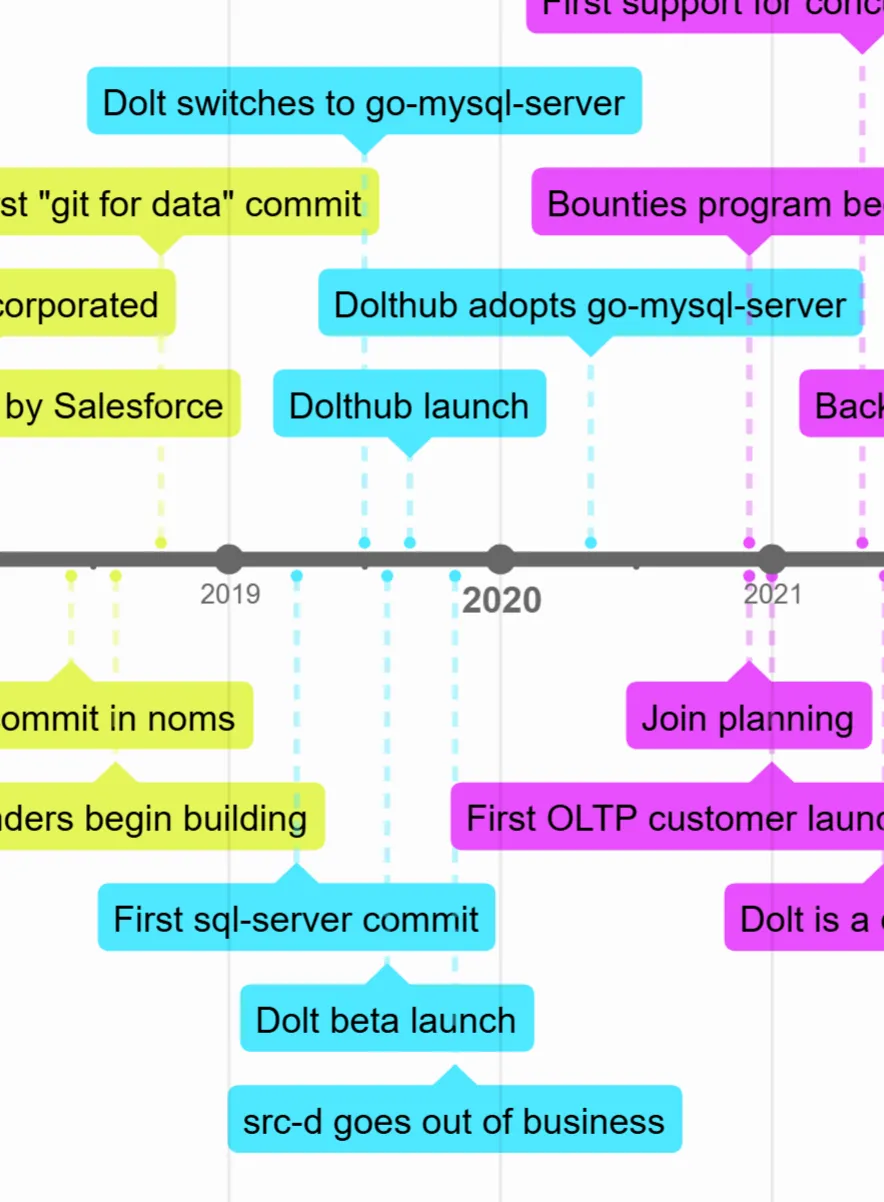
I joined the company in early 2019 on the pitch that we would build a lucrative data marketplace serving a market that would be worth tens of billions inside of a decade. My first project upon joining was to add SQL functionality to the tool. At the time, we had no intention of building an OLTP database, we just thought exposing SQL functionality would make the tool more useful and let it integrate with a lot of other tools in the space.
I started by rolling my own SQL engine, but it was slow going. Turns out building a query execution
engine is hard, who could have predicted that? After a month or so in development, someone else on
the team sent me a link to a cool SQL engine they found written in pure Go called
go-mysql-server. I very quickly determined the project
was much farther along and much better than my effort so far, so I scrapped what I had and migrated
our codebase to the new engine. Pretty soon I found some bugs and missing functionality, so I
started submitting PRs back. The engine was
already pretty functional and getting better at a rapid pace when src-d, the parent company
sponsoring the project, went out of business in late 2019. That was our cue to adopt the
go-mysql-server project,
creating our own fork and making it the authoritative one.
While this was happening, the rest of the team was busy building more git source control and data manipulation features into Dolt and launching DoltHub, our site to share Dolt databases. We launched DoltHub and Dolt in late 2019, still chasing the data sharing or marketplace use case.
But by 2020, something unexpected was happening: we were getting a lot of interest from prospective customers who wanted to run Dolt not for sharing data, but as an OLTP database with version control. The “helpful side feature” of SQL support had surprisingly turned into our product market fit.
Dolt is a database: table stakes#
These events are colored purple in the timeline.
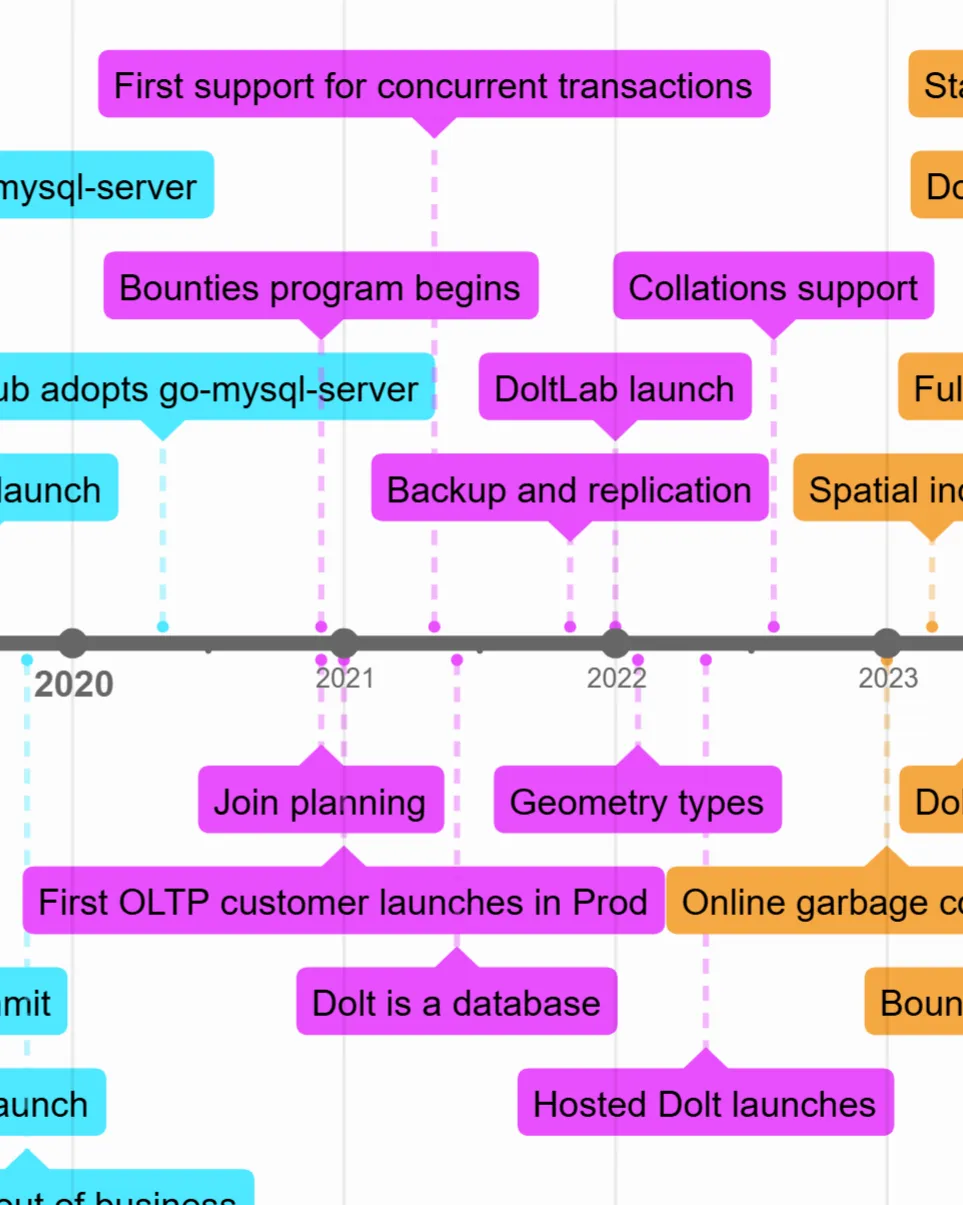
It took us months to realize that we were now a database company. Our SQL support was still quite limited and lots of things didn’t work or were way too slow, but one early customer, Turbine, had unreasonable faith in us and worked with us to close the gaps. They were willing to tolerate a 20x performance penalty relative to MySQL, which sounds absolutely bonkers in retrospect. Even crazier was the fact that we couldn’t hit that target for many of the queries they planned to run.
During this era we were furiously adding missing features and fixing bugs and improving performance in the SQL engine. This was when we first made it possible to join any number of tables efficiently — previously only joins of two tables could make use of indexes.
Turbine launched into production in early 2021, and we set about fulfilling the table stakes for being an OLTP database. Things like supporting transactions and sessions correctly, aggregates and windows, and the hundreds of functions MySQL bundles all needed to be built. Basic functionality customers expect from an OLTP database solution, like backups and replication, collation support, and geometry types all needed to be built. At the same time we were slowly but steadily making progress on performance and latency.
In June of 2021, we were ready to tell the world that Dolt is a database, and by that time it was mostly true.
This is also the era we launched our bounties program, which was a last-gasp attempt to see if the original data marketplace use case could be made to fly. (It couldn’t).
That’s not quite true though: while a data marketplace failed to materialize, we did find customers who liked the data sharing and collaboration capabilities of DoltHub, but didn’t want to share their data with the world, only with their company. DoltLab was born to meet this use case, and launched at the beginning of 2022.
A production quality, mature database#
These events are colored orange in the timeline.
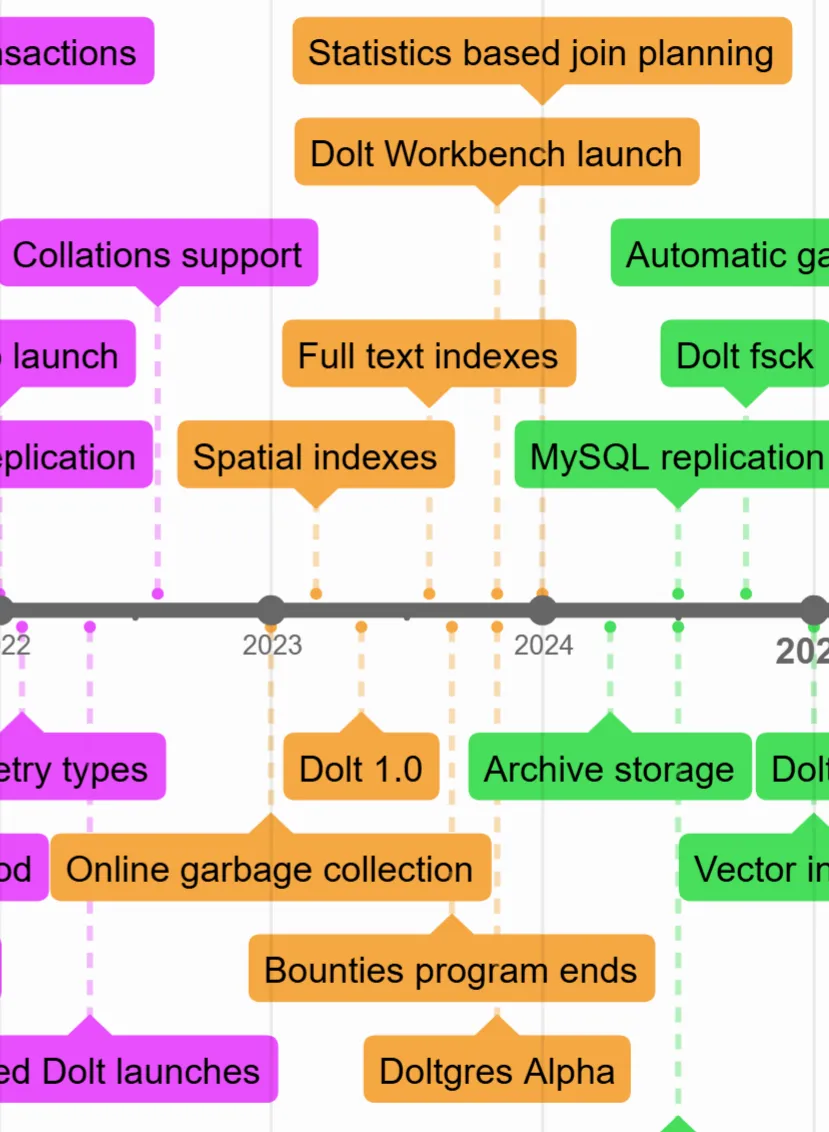
During this era, we were feeling increasingly confident that Dolt was the real deal, that we had created something powerful and new that would help a lot of people build new products and tools. We had several production customers throwing real-world workloads at our database and running queries as complex as anything we could imagine. Dolt was ready for prime time, and we were ready to tell the world.
With the launch of a new journaled storage
system, we finally had a true
ACID-compliant database. We were starting to pull even with MySQL on several key performance
metrics, and while we wouldn’t hit 99.9% correctness for another year, almost all of the remaining
bugs were obscure edge cases customers never saw in the wild. Dolt 1.0 launched in May of
2023, almost 5 years after work began and
almost 8 years since the first commit in noms that started it all.
With this foothold of stability and performance, we started expanding the set of features, adding spatial and full-text indexes for customers. We radically improved the performance of Dolt’s query planner and wrote our first implementation of statistics-based join planning. And we launched a native desktop application for querying and managing your Dolt databases.
This was also when we finally let the dream of a data marketplace die (for now) and ended our bounties program.
Finally, having built out almost all of the features required to make Dolt a drop-in MySQL replacement, we decided to fulfill one of our most frequent feature requests and build a Postgres-compatible version as well. Doltgres shipped its Alpha at the end of 2023.
The next generation of Dolt and Doltgres#
These events are colored green in the timeline.
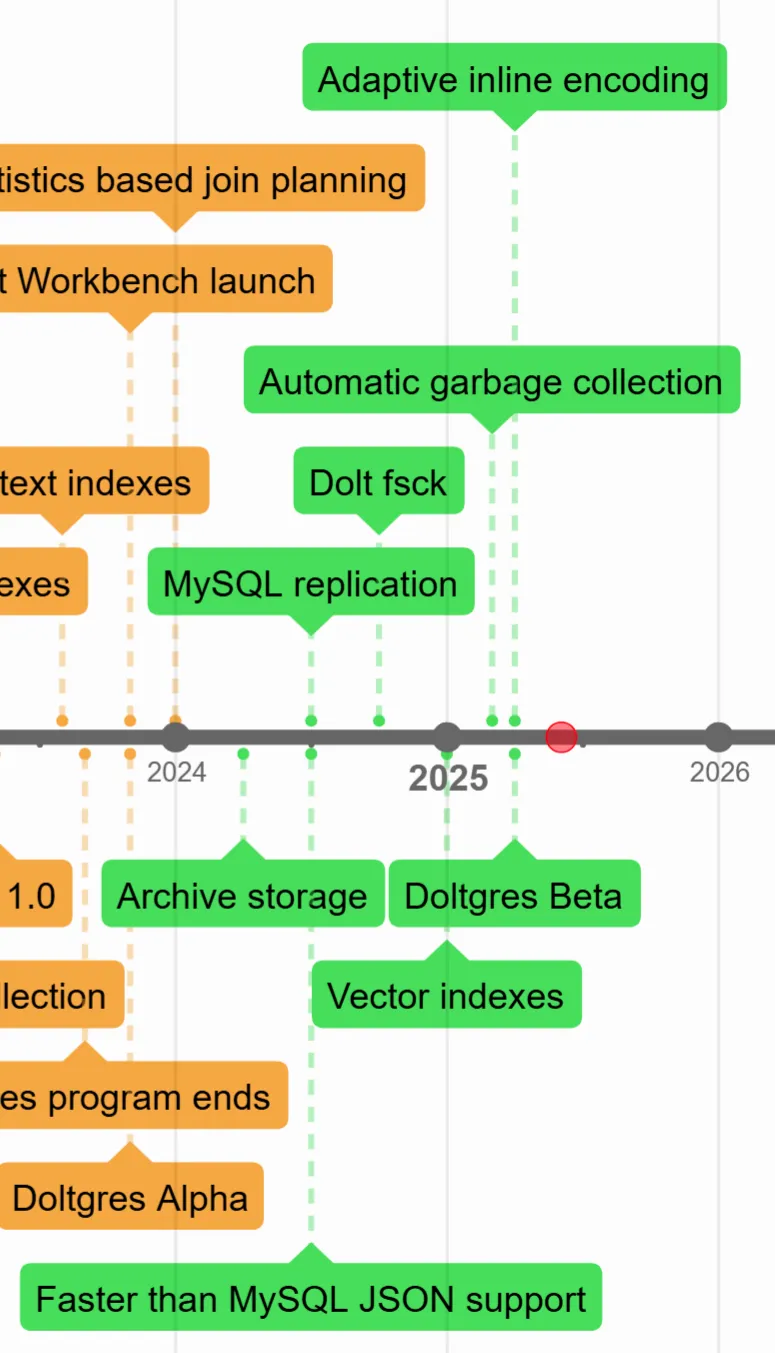
With a firm customer base and solid stability and performance, during this era we branched out into more advanced features for the database. We were no longer just rushing to catch up to MySQL, we were actively pushing past it and building features nobody else had.
Things like:
- An archive storage format to cut disk usage in half.
- JSON document search faster and more compact than MySQL
- Vector storage and indexes
- Replication from MySQL to Dolt with full snapshotting of every commit
- Adaptive inline encoding
We also kept building and refining the version control features, as well as making the engine faster. We finally got every single one of our 5.7 million correctness tests to pass in early 2024.
And with Dolt on solid footing, we were free to put about half the team to work on building out Doltgres. Last month we finally felt ready to call what we had Beta.
Conclusion#
The Dolt codebase turned 10 today. That’s a reason to celebrate! Why not install Dolt or Doltgres today and see what all that work was for?
Or come by our Discord to talk to our engineering team and meet other customers. We love hearing from new people.