
Today’s blog is about ACID transactions in Dolt, how we built them and what this means for Dolt users. Dolt first released SQL transactions 18 months ago. Since then we’ve continued to improve transactional performance in Dolt sql-server, but the core transactional model has remained largely the same. However, one major feature was missing from our transactional support: durability. Without durable transactions, data can be lost in the event of power-failure or an operating-system crash. In order to be fully ACID-compliant, we built a new persistence layer for Dolt that supported durable transactions at high throughput. Every committed transaction is now fully recoverable from disk in the event of any system failure. Let’s take a closer look at what ACID means and how we built our new persistent store.
The ACID Standard#
ACID is an acronym describing four core properties of transactions in a database system:
-
Atomicity: Transactions must be “all or nothing”, operations must not be partially applied.
-
Consistency: Committed transactions must not corrupt any database state.
-
Isolation: Data from in-progress transactions must not be visible to other transactions until it is committed.
-
Durability: Committed transactions must be fully recoverable in a system failure.
These definitions were first described in 1983 by researchers Theo Haerder and Andreas Reuter. They sought to characterize the stability of various database systems and the guarantees that they provided to their users. This was during an era of rapid development in database technology; the first version of the ANSI SQL standard wouldn’t be published until 1986. By defining ACID properties, Haerder and Reuter set the standard for transactional semantics in database systems.
Dolt Transactions#
In this past, we’ve written extensively about how Dolt stores table data, its commit graph, and how it leverages these primitives to support scalable database merges. For now, we’re going to set aside these higher-level features and focus on physical data storage in Dolt databases.
At the lowest level, Dolt databases are composed of “chunks”. Chunks are simply variable length byte strings that encode database objects and are stored in a content-addressed key-value store called a “chunk store”. For example, indexes in Dolt are stored in a B-tree-like data structure where each node in the tree is a chunk. Within these indexes, parent nodes refer to child nodes by storing their content addresses and dereference those addresses using a chunk store. Tables objects are similarly stored as chunks with content address references to each child object composing the table:
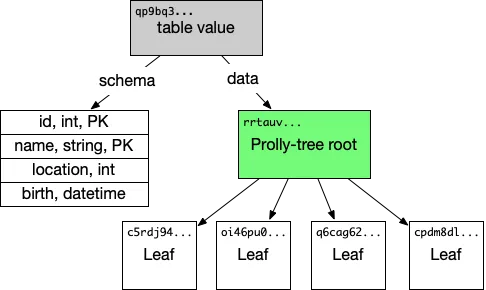
This hierarchical structure continues higher up the commit graph:
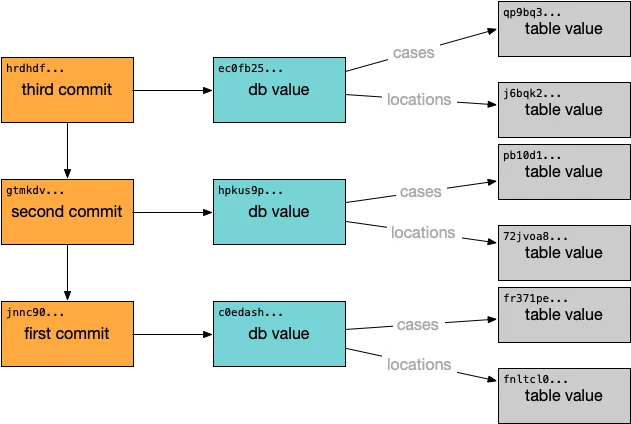
At the highest point in the commit graph is a single root chunk. All live data in the database is accessible by following references from this root. Each update to a database writes a new root chunk. With these storage concepts in mind, let’s explore how Dolt transactions meet the standard for ACID-compliance.
Atomicity#
The root chunk is key to atomic transactional updates in Dolt. Within a chunk store, the address of the root chunk is stored in the “manifest” file. The manifest stores various metadata about the database including the root chunk address and the location of each file storing chunk data. During a transaction commit, new chunk data is written to disk in height-order (child chunks before parents) with the root chunk written last. The manifest is then atomically overwritten, updating the database state with the newly committed transaction.
Consistency#
All chunk data in Dolt is immutable. Updates to table data use copy-on-write semantics, so committed data is never overwritten during a transaction. Failed transactions may leave behind chunks in the chunk store, but this new data will be unreachable without an update to the root chunk. This orphaned data will later be garbage collected.
Isolation#
Dolt’s transaction model is based on Multi-Version Concurrency Control. Each open transaction works on its own copy of the database. At commit time, these versions are merged together before writing their data to the database. Due to copy-on-write update methods, each transaction’s writes are naturally isolated from other transactions.
Durability#
The durability requirement of ACID means that all transactional data is flushed from memory to persistent storage
at commit time. For Dolt, this means that each chunk must be written out to a data file. However, to be fully durable
we must ensure that transactional data will survive a system crash or power failure. We must guarantee that file-system
writes are flushed to disk and not buffered in kernel-space memory. On unix-like systems, this is achieved with an
fsync() system call to each modified file or directory.
Journal Chunk Store#
This brings us to the crux of ACID transactions in Dolt: our existing chunk store implementation was not designed to
commit durable transactions with high throughput. For each commit, two new files are created, one for the new chunk data
and one for the new manifest. In order to durably persist this new data, we must perform fsync() calls on both of
these new files and on the directory that contains them. It’s worth noting that fsync() is a very expensive
operation. The exact cost is dependent on system hardware, but on every system it requires putting bits into a physical
medium. Most databases address this problem by writing all transactional data to a single, existing file and performing
only a single fsync() call to finalize a transaction. So we thought we’d try the same!
Our new “journal chunk store” works by writing all transactional data to a single, append-only file. The journal is
composed of two types of records: chunk records and root records. Each transaction writes its new data to the end of the
journal as chunk records. On transaction commit, the new root address of the transaction is written in a root record and
the file is flushed to disk with an fsync(). A manifest file is still needed to store other metadata about the
database, but this data is rarely updated. Co-locating fast-changing transactional data in the journal file allows us
to optimize our interactions with the file-system. The performance improvements from this change are significant.
In fact, the Journal Chunk Store is faster with fsync() turned on than our old Chunk Store is without fsync()!
| write_test | before | after | change |
| --------------------- | ------ | ----- | ------ |
| oltp_delete_insert | 11.87 | 6.09 | - 49 % |
| oltp_insert | 3.19 | 3.02 | - 5 % |
| oltp_read_write | 18.28 | 16.71 | - 9 % |
| oltp_update_index | 5.47 | 3.13 | - 43 % |
| oltp_update_non_index | 6.09 | 3.02 | - 50 % |
| oltp_write_only | 8.90 | 7.98 | - 10 % |
| types_delete_insert | 12.30 | 7.04 | - 43 % |This difference in performance is largely due to the smaller number of files created in the Journal Chunk Store. The old chunk store created a new chunk data file on every commit. At some point the number of these files will grow quite large, and the database must conjoin them into a smaller number of files. The current heuristic is to conjoin data files if there are more than 256 active files and these conjoin operations happen synchronously during commits. The new Journal Chunk Store rarely creates new data files, avoiding the need to continually conjoin.
Wrapping Up#
You can try the new Journal Chunk Store today! Our latest release v0.52.0 contains a beta release of this new
persistence layer. We’re initially releasing it behind a feature flag while we continue to test its stability. To use
it simple set the environment variable DOLT_ENABLE_CHUNK_JOURNAL=true. We’re excited about this new Dolt feature, both
for the performance and reliability benefits it will provide. If you’d like to learn more about Dolt’s storage layer,
or about possible use cases for Dolt, hit us up on Discord!