
Dolt is a SQL database with Git-like versioning features intended to be a drop-in replacement for MySQL. In order to be a drop-in replacement, Dolt needs to match MySQL behavior as closely as possible.
We chose sqllogictests, a collection of around 6 million sql correctness tests, as our correctness benchmark.
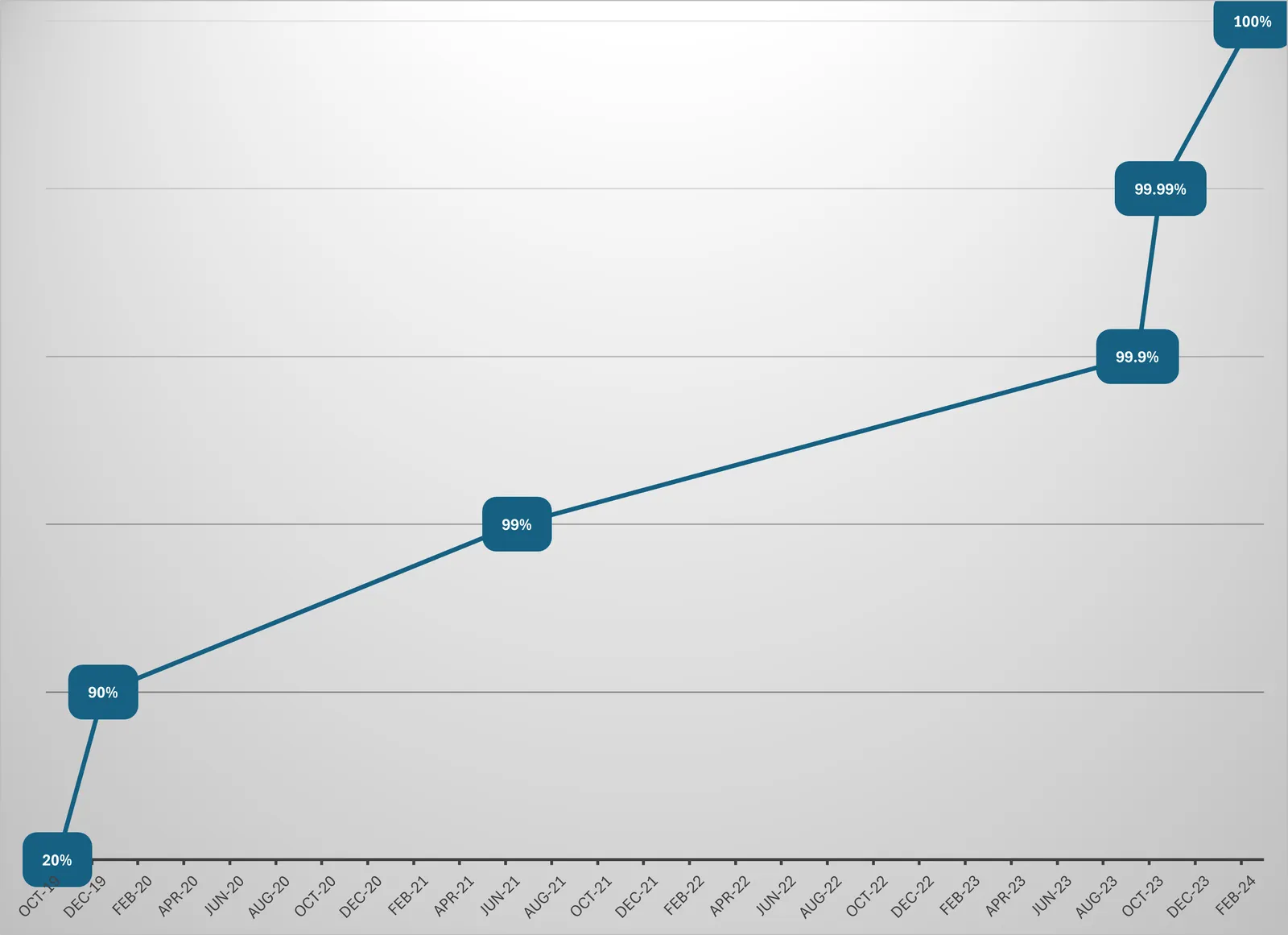
Over the course of the last 5 years, we’ve been steadily increasing Dolt’s correctness, and today we’re proud to announce that we’ve achieved 100% correctness. This is a huge milestone for us, and we’re excited to share it with you.
A Brief History#
On October 22, 2019, we first incorporated sqllogictests in our test suite.
Initially, we only had ~20% of the tests passing, with a majority of tests failing due to missing features.
A couple months later, on December 17, 2019, we managed to increase our correctness to 90%. The notable additions here were support for the ALL keyword and tables without Primary Keys.
A year and a half later, on June 28, 2021, we reached 99% correctness. We reached this milestone with support for VIEWS, Secondary Indexes, Window Functions, and support for DISTINCT over functions.
Roughly two years after that, on September 6, 2023, we achieved 99.9% correctness. The changes here revolved around aliasing, specifically over joins and lateral join, involving aggregations and using clauses.
A short month later, on October 11, 2023, we have 99.99% correctness.
There were a variety of changes here, such as parsing of extra table creation parameters, support for INTERSECT and EXCEPT, and large join performance improvements.
Which brings us to today, where the remaining 0.01% of tests have been fixed, and we have achieved 100% correctness.
Here’s a graph to illustrate our progress:
Decimals#
Ever since their inception, Decimals have been a pain point for us. Notably, we’ve struggled to match MySQL’s Decimal behavior during rounding, comparison, and conversion.
Depending on the scale (the number of digits after the decimal point) of the Decimals and the type of operation (addition, subtraction, multiplication, division), the resulting scale of the Decimal result would vary. This isn’t the first time we tackled this issue; however, this time we’ve managed to fix the remaining edge cases.
Additionally, these rounding rules actually change when using these decimals in a comparison. For example:
mysql> SELECT 1/3;
+--------+
| 1/3 |
+--------+
| 0.3333 |
+--------+mysql> SELECT 1/3 = 0.3333;
+--------------+
| 1/3 = 0.3333 |
+--------------+
| 0 |
+--------------+This is because the result of 1/3 is actually 0.333333333. We can use a CAST() to reveal the full precision.
mysql> SELECT CAST(1/3 AS DECIMAL(65,30));
+----------------------------------+
| CAST(1/3 AS DECIMAL(65,30)) |
+----------------------------------+
| 0.333333333000000000000000000000 |
+----------------------------------+Furthermore, the scale of the divisor and dividend can affect the scale of the result.
mysql> SELECT 1.0/3.0;
+---------+
| 1.0/3.0 |
+---------+
| 0.33333 |
+---------+mysql> SELECT CAST(1.0/3.0 AS DECIMAL(65,30));
+----------------------------------+
| CAST(1.0/3.0 AS DECIMAL(65,30)) |
+----------------------------------+
| 0.333333333333333333000000000000 |
+----------------------------------+After a dividing a bunch of numbers with various scales, we’ve uncover MySQL’s scale comparison rules.
Here’s a table to illustrate the rules:
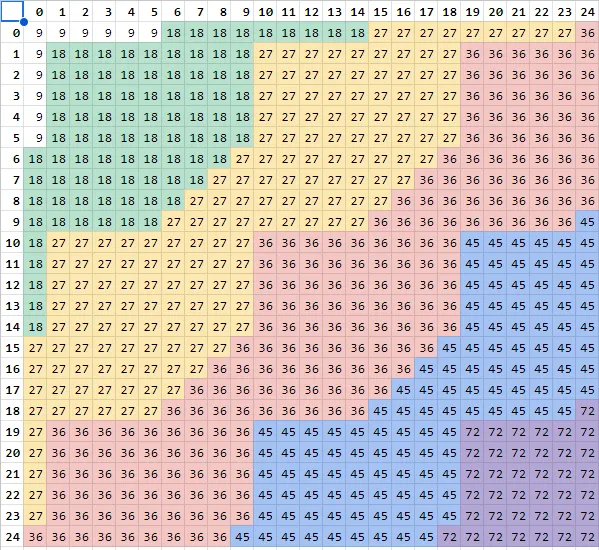
(The bolded numbers are the scales of the divisor and dividend.)
This table boiled down to this code snippet:
...
lScale, rScale := -1*l.Exponent(), -1*r.Exponent()
inc := int32(math.Ceil(float64(lScale+rScale+divPrecInc) / divIntPrecInc))
if lScale != 0 && rScale != 0 {
lInc := int32(math.Ceil(float64(lScale) / divIntPrecInc))
rInc := int32(math.Ceil(float64(rScale) / divIntPrecInc))
inc2 := lInc + rInc
if inc2 > inc {
inc = inc2
}
}
scale := inc * divIntPrecInc
...In the past, we’ve had issues with Decimal division performance as well. The solution was to use floating point division under the hood, and then convert the result to a Decimal. This was a performance improvement, but it also introduced a new set of correctness issues. Fortunately, the fixes here actually led to a performance improvement as well.
Here are some benchmarks to illustrate the performance improvements:
Before
BenchmarkDivInt-16 10000 695805 ns/op
BenchmarkDivFloat-16 10000 695044 ns/op
BenchmarkDivHighScaleDecimals-16 10000 694577 ns/op
BenchmarkDivManyInts-16 10000 1151316 ns/op
BenchmarkManyFloats-16 4322 618849 ns/op
BenchmarkDivManyDecimals-16 5721 699095 ns/opAfter:
BenchmarkDivInt-16 365416 3117 ns/op
BenchmarkDivFloat-16 1521937 787.7 ns/op
BenchmarkDivHighScaleDecimals-16 294921 3901 ns/op
BenchmarkDivManyInts-16 40711 29372 ns/op
BenchmarkManyFloats-16 174555 6666 ns/op
BenchmarkDivManyDecimals-16 52053 23134 ns/opIn the worst case, we see a 30x improvement, and in the best case we see a 880x improvement!
GROUP BY and HAVING Aliasing#
MySQL’s aliasing rules for GROUP BY and HAVING are unique.
GROUP BY and HAVING clauses can reference aliases, even if they are duplicates of column names.
One would expect these to throw an error, but MySQL lets you off with a warning.
Here’s an example:
mysql> SELECT * FROM tab;
+------+------+------+
| col0 | col1 | col2 |
+------+------+------+
| 15 | 61 | 87 |
| 91 | 59 | 79 |
| 92 | 41 | 58 |
+------+------+------+
3 rows in set (0.0005 sec)
mysql> SELECT col2 AS col0 FROM tab GROUP BY col0, col2 HAVING col2 > col0;
+------+
| col0 |
+------+
| 87 |
+------+
1 row in set, 2 warnings (0.0006 sec)
Warning (code 1052): Column 'col0' in group statement is ambiguous
Warning (code 1052): Column 'col0' in having clause is ambiguousHere col2 is aliased as col0, but the col0 in the GROUP BY and HAVING clauses are still referencing the original col0.
Typically, I wouldn’t expect people to run into this issue, but it was a part of the sqllogictests suite, so we fixed it.
Joins#
A handful of tests were failing due to some troublesome join behavior. Although there were only a few tests failing because of this, tracking down the root cause took a significant amount of time.
Here’s one of the smaller examples:
SELECT
x46, x3, x1, x5, x61, x47, x30, x52, x49, x63, x28, x53
FROM
t46, t3, t1, t5, t61, t47, t30, t52, t49, t63, t28, t53
WHERE
1 = a5 AND
b28 = a5 AND
b1 = a28 AND
b53 = a1 AND
b30 = a53 AND
b49 = a30 AND
b47 = a49 AND
b46 = a47 AND
b61 = a46 AND
b3 = a61 AND
b63 = a3 AND
b52 = a63All the failing queries followed this pattern: multiple tables with a single primary key, and a long chain of equality conditions, resulting in one row. Somewhere in our join reorder optimization, we were losing track of one of the AND conditions, resulting in way too many rows being returned.
What’s Next?#
While there are roughly 6 million queries in sqllogictests, it is still not a comprehensive test suite; there are many edge cases that are not covered.
Within our enginetests in the go-mysql-server repo, we have quite a few skipped tests that we need to address.
Additionally, sqllogictests were designed to be a correctness benchmark for generic SQL engines, so there are many MySQL specific features that are not covered.
Looking at our documentation, there are still quite a few missing functions and operators.
Furthermore, there is Dolt specific functionality that isn’t covered in sqllogictests that are not covered.
You can see our ever growing github issues.
Conclusion#
We’re proud to have achieved 100% correctness, but we’re not stopping here. As always, we’re working diligently to improve Dolt’s correctness, performance, and feature set. Want to help out? Check out our github and make a contribution. Feel free to reach out to us on Discord.