
sqllogictests is a collection of around 6 million sql correctness tests, designed to be used a as benchmark for SQL engine implementations. Although sqllogictests was made by the sqlite team, it can check for compatibility with several different SQL dialects.
Dolt is a drop-in replacement for MySQL that supports git-like semantics for version control, commit history, branches, merges, etc. But for it to be a drop-in replacement, it needs to match MySQL’s behavior exactly, warts and all. And it does. But you don’t need to take our word for it. Since we use sqllogictests to measure compatibility, anyone running a Dolt server can replicate our benchmarks.
The Journey So Far#
Matching MySQL’s behavior in every possible situation has been quite a journey.
- In 2019, we proudly announced 90% correctness with sqllogictests.
- In 2021, we reached 99% correctness.
- And just last month, September 2023, we reached 99.9% correctness.
We’re still not at 100%. But we’re getting closer every day. Assuming that we want to maintain our current trajectory of getting another nine every two years, we’re aiming to reach 99.99% sometime in 2025.
Just kidding. We have it right now. As of this morning, in fact. Which is really good timing, given that I scheduled this announcement post a month ago.
The Triage Stage#
See, as soon as we reached three nines, we started dreaming about four nines. We realized that we were down to a measly six thousand remaining conformance failures: small enough that we could probably categorize all of them. Then we could triage each category , rate by difficulty and number of affected tests, and then prioritize and delegate work. How could we do that so quickly? Using Dolt itself, of course! At DoltHub we believe in our own product enough to use it internally for all sorts of odds and ends. (“Eating your own dogfood,” as they say.)
We have a continuous integration job that runs the tests every day and exports the results as a csv, which meant I could just import the most recent results into a dolt table by using the dolt table import CLI command. From there, I removed any tests that were already passing, and then added a full text index on both the test query and the error message. Finally, I created an auxillary “tags” table that paired string tags with foreign keys to test results.
From there, it was easy:
- Select a random untagged test failure.
- Categorize the failure and tag it. Usually this was obvious based on the error message.
- Run a full text search to find all tests with similar errors and tag those too.
- Select a new untagged test failure and start the process over.
Since problems that cause more failures are disproportionally likely to show up in my random sample, the biggest issues were identified quickly. It only took an afternoon to assign tags to 90% of the remaining failures, which was all that we needed to get Dolt to 99.99% compatibility.
Once I had the failures identified, I created issues in GitHub to track them, and delegated the work to James, Max, and myself.
As we get closer to 100% correctness, the remaining tests become increasingly niche. If the main theme last time was “convenience features” that users might want but not need, the theme for this time might be “unused features” that most users are unlikely to ever encounter. These are statements we don’t expect users to actually write. Some of them are outdated or specific to MySQL’s inner workings, while others have no resemblance to anything that an actual human being (or ORM) would ever actually produce: degenerate cases that exist only to stress-test SQL engines.
But its important to support these corner cases anyway. Because when something gets used by enough people, it’s going to be used in ways unimaginable. No matter what bizzare use case you have, we want you to be able to push Dolt to its limits.
(Speaking of which, if you have a bizarre use case for Dolt, we encourage you to tell us about it on our Discord, or write about it. We’re always looking to find new ways that people integrate Dolt into their projects.)
Like our last correctness announcement, we’re going to take a behind-the scenes-look at some of the issues we solved to get to four nines. But before we do, remember this meme?
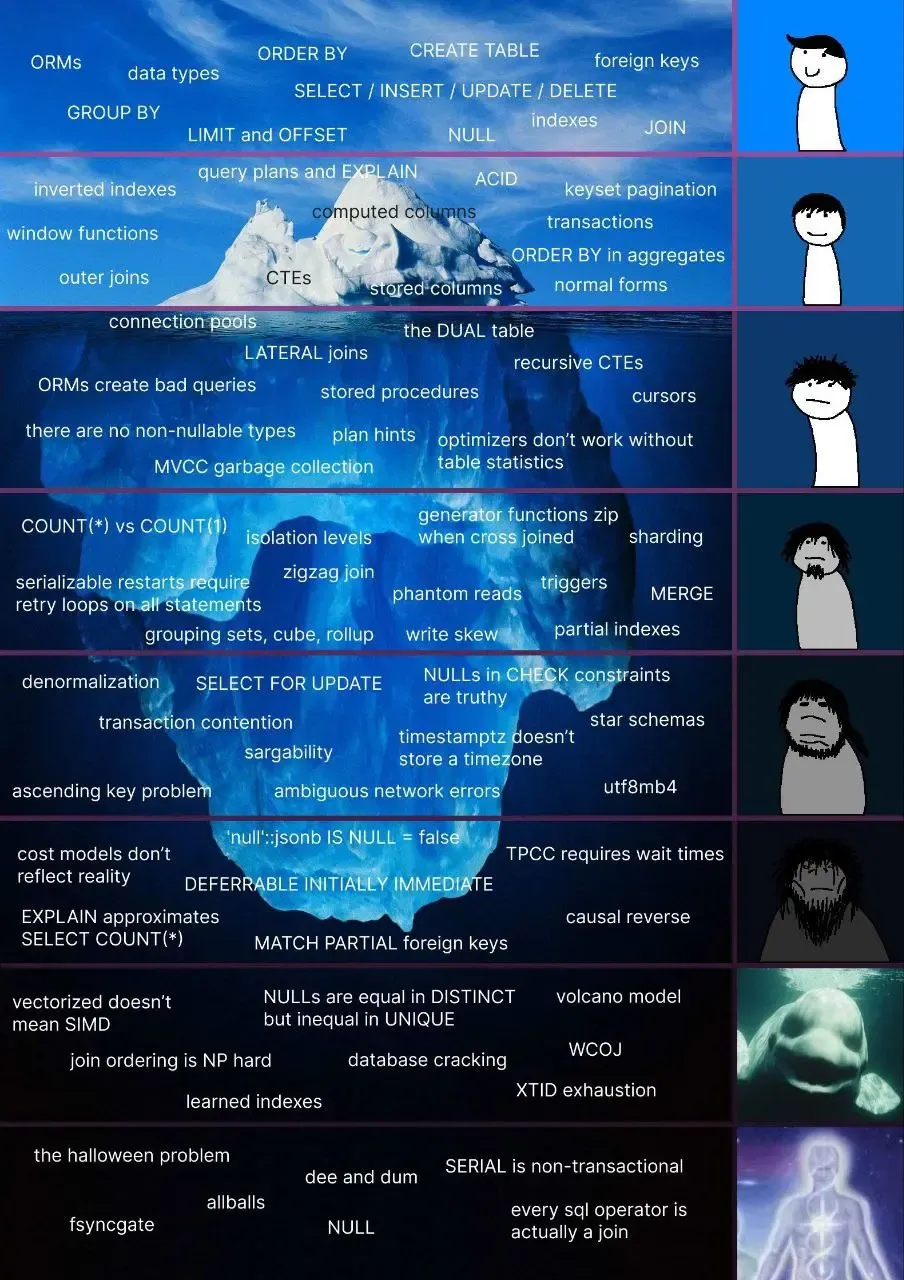
It made the rounds a couple months ago. At least one of the items near the bottom of the image will be making an appearance before the end of this post. Buckle up, we’re going diving.
What’s New in Dolt#
Parsing unneeded parameters#
A common trend in this batch was table settings that only made sense in the context of the MySQL engine. The most emblematic of these was SECONDARY_ENGINE, a parameter that could be passed to CREATE TABLE and ALTER TABLE statements. Its purpose was to allow MySQL users to select an alternate execution engine for their query. It looks like this:
CREATE TABLE tab (id int primary key) SECONDARY_ENGINE rapid;Notably, the parameter has no impact on the final result of statements. It’s effectively an exposed implementation detail.
But it’s still part of the MySQL grammar. So we parse it now. We don’t do anything with the parsed value, but we still parse it.
There were actually a bunch of parameters like this.
Intersect and Except#
We already had support for UNION operator, which combines two result sets, returning any row that appears in either:
(SELECT 1 as a) UNION (SELECT 2);
+---+
| a |
+---+
| 1 |
| 2 |
+---+Now we support the other two set operations: INTERSECT and EXCEPT. INTERSECT returns the rows that appear in both child results sets, while EXCEPT returns the rows that appear in one set but not the other.
CREATE TABLE a (i int);
INSERT INTO a VALUES (1), (2);
CREATE TABLE b (i int);
INSERT INTO b VALUES (2), (3);
(TABLE a) INTERSECT (TABLE b);
+---+
| i |
+---+
| 2 |
+---+
(TABLE a) EXCEPT (TABLE b);
+---+
| i |
+---+
| 1 |
+---+
This one is a lot like the features that got us to three nines: an actual feature that can be used to write more readable queries, but isn’t strictly speaking necessary. You can get the same behavior from writing joins:
SELECT * FROM a JOIN b USING (i);
+---+
| i |
+---+
| 2 |
+---+
SELECT * FROM a LEFT JOIN b USING (i) WHERE b.i IS NULL;
+---+
| i |
+---+
| 1 |
+---+
But I think INTERSECT and EXCEPT are a little bit more readable here.
Also, the behavior isn’t exactly the same as JOIN, since you can also write INTERSECT ALL and EXCEPT ALL, which handle duplicate rows:
CREATE TABLE c (i int);
INSERT INTO c VALUES (1), (1), (1), (1), (1);
CREATE TABLE d (i int);
INSERT INTO d VALUES (1), (1), (1);
-- MAX(3, 5) = 3
(TABLE c) INTERSECT ALL (TABLE d);
+---+
| i |
+---+
| 1 |
+---+
| 1 |
+---+
| 1 |
+---+
-- 5 - 3 = 2
(TABLE c) EXCEPT ALL (TABLE d);
+---+
| i |
+---+
| 1 |
+---+
| 1 |
+---+Those would be trickier to write as JOINS. At least, I couldn’t find a way to do it. If anyone reading this has a clever way to write this as a join, shoot me a message on Discord and I’ll give you a shout-out in my next blog post.
Of everything mentioned in this announcement, this work was the only one that’s a real user-facing feature, and it’s all thanks to James for implementing it. Thank you, James!
Name resolution order#
Sometimes in a complicated enough expression, an identifier might feasibly refer to multiple different columns. For example, consider the following:
CREATE TABLE x (a int, b int, c int)
CREATE TABLE y (a int, b int, c int)
SELECT x.a, y.b AS a, x.c + y.c AS a FROM x JOIN y GROUP BY a ORDER BY aPop quiz: What does a bind to in the GROUP BY expression? What about the ORDER BY expression?
Do they at least bind to the same thing? (Hint: If they did, then I wouldn’t be writing this.)
It turns out that MySQL has different preference rules for GROUP BY vs ORDER BY. GROUP BY prefers to bind to columns in the input tables, while ORDER BY prefers to bind to columns in the results. (The actual behavior is even more complicated.) In this specific example, ORDER BY a binds to the result column x.c + y.c AS a, while GROUP BY a binds to the column x.a on table x. Since we weren’t expecting these two expressions to have different rules for binding to columns, we were computing the wrong results for GROUP BY. This has now been fixed.
We definitely recommend that you don’t write expressions like this, with ambiguous column names. Still, in the event that you do, Dolt now has you covered.
Intermission#
Based on my triage work, these issues should have been enough to get us to 99.99% conformance. In a moment of hubris, I announced my success to the team and went home.
The next morning, I look at the latest benchmark results:
total tests 5937463
ok 5936365
not ok 570
timeout 1
correctness_percentage 99.9899.98… so close, but not what I had been planning for. Had I missed something? Maybe some of the failing tests actually had multiple problems, and fixing the first issue would allow the second one to become visible.
I get an email from Tim. He’d seen the results too and felt like something wasn’t adding up. He did some back of the napkin math:
> 1 - (570+1)/5937463
0.9999038And something else wasn’t adding up either (in this case, literally):
> 5936365 + 570 + 1
5936936This wasn’t all the tests. There were 527 tests unaccounted for. Where were they?
Turns out, there was one other status code that the tests could return (other than ok, not ok, and timeout): did not run. I’d ignored this value during my initial triage, and these accounted for the missing tests. But why were they not running? Fortunately, the test harness output contained a filename and line number for each test, and all the skipped tests were from the same file… curiously, it was the same file as the timed out test. It turned out that when the test timed out, the test harness killed the process, which preempted every subsequent test in the file.
The harness had a pretty generous timeout setting of 20 minutes. Curious as to what kind of query could take 20 minutes to run, I opened up one of the tests.
SELECT x46,x59,x60,x24,x5,x28,x17,x19,x36,x51,x30,x25,x48,x31,x63,x7,x20,x10,x27,x32,x62,x21,x14,x15,x58,x50,x13,x43,x56,x12,x40,x41,x6,x45,x23,x54,x37,x8,x3,x22,x34,x29,x33,x55,x38,x26,x39,x35,x18,x52,x1,x2,x4,x11,x47,x44,x61,x49,x53,x64,x57,x42,x9,x16
FROM t17,t7,t30,t12,t49,t23,t63,t51,t33,t43,t9,t62,t21,t48,t36,t1,t4,t25,t6,t35,t52,t58,t50,t14,t32,t53,t22,t13,t15,t10,t19,t61,t5,t11,t40,t29,t46,t31,t60,t55,t54,t16,t42,t2,t20,t39,t8,t38,t44,t41,t56,t64,t37,t59,t34,t3,t24,t57,t18,t45,t26,t27,t47,t28
WHERE a49=b21 AND b32=a16 AND a62=b15 AND b43=a26 AND b27=a54 AND a57=b34 AND b44=a35 AND a51=b8 AND b56=a31 AND a33=b63 AND b37=a10 AND a21=b16 AND b23=a7 AND a37=b7 AND a32=b50 AND a6=b39 AND a14=b47 AND b9=a25 AND a27=b6 AND a29=b40 AND a60=b36 AND b64=a45 AND b46=a36 AND a39=b41 AND b61=a64 AND b17=a50 AND a63=b14 AND a18=b25 AND b29=a2 AND b58=a24 AND a28=b42 AND a12=b57 AND a56=b2 AND a4=b1 AND b19=a8 AND a41=b48 AND a61=b52 AND a40=b20 AND a3=b62 AND a11=b33 AND a23=b26 AND a34=b28 AND b60=a52 AND a31=10 AND b30=a59 AND b53=a47 AND b5=a55 AND b18=a43 AND b3=a44 AND a13=b24 AND a46=b35 AND a30=b51 AND a17=b59 AND b54=a5 AND a38=b4 AND a53=b55 AND b22=a20 AND a19=b38 AND b13=a42 AND a58=b49 AND a1=b45 AND b12=a48 AND a15=b10 AND a22=b11Oh. Oh dear.
The Final Boss#
That’s a 64 table join.
Some experimentation showed that as the number of tables in a join increases past around 15, Dolt’s performance begins to noticeably degrade and take a few seconds. At 25 tables, joins took around an hour. Extrapolating from there, a 64 table join would take 3.5 million years. That’s about 3.4 million years longer than I’m willing to wait. (And I’d have to explain the resulting AWS bill.) Something had to be done about this.
Performance profiling revealed that Dolt wasn’t even spending all of that time executing the join: all of the runtime was planning the join.
Join planning is an important step in our analysis pipeline. See, while we sometimes imagine large joins as a single process, both the SQL grammar and Dolt’s SQL engine represent JOIN as a binary operation. In order to join N tables, we need to perform N-1 binary joins (and choose a physical execution plan for each of them.) Our then-current implementation adopted a brute-force approach that computes the best join plan for every possible combination of tables. The number of ways to order these joins is called the Catalan Numbers, and it grows exponentially. Our implementation leverages dynamic programming to prevent redundant computation, but the runtime was still exponential.
There has to be a better way. Maybe someone on the Internet found a way to…

I told you this meme would be relevant.
Join ordering is an NP-hard problem. This basically means for the general case, There’s no approach that’s faster than just trying every single possible option.
We could just disable join ordering and hope that the order supplied in the query happens to be optimal (or at least, good enough.) That’s often the case for human-written queries. But it’s clearly not the case here. We tried it anyway, while disabling join ordering did help, it wasn’t enough: the default ordering was still too slow for the engine.
So we can’t reorder the joins, but we also can’t not reorder the joins. We were caught in a pincer between two inviolable laws of mathematics with no clear solution.
Maybe if this is such a hard problem, MySQL doesn’t handle it either? Let’s see how MySQL handles the smaller 25 table join, the one that takes us only an hour.
mysql> SELECT x13,x20,x6,x32,x54,x39,x28,x47,x43,x24,x30,x25,x2,x53,x40,x23,x52,x5,x18,x63,x31,x59,x11,x51
FROM t43,t52,t32,t53,t28,t5,t47,t51,t31,t13,t40,t18,t24,t20,t63,t30,t59,t39,t54,t25,t23,t11,t6,t2
WHERE a2=b20
AND b25=a20
AND a54=b32
AND b40=a6
AND a28=10
AND a24=b47
AND a25=b23
AND b52=a31
AND a47=b54
AND b31=a30
AND b51=a53
AND b59=a5
AND a11=b13
AND a13=b53
AND a63=b30
AND b43=a18
AND a28=b5
AND b18=a23
AND b24=a40
AND b39=a59
AND a32=b11
AND a39=b63
AND b6=a52
AND b2=a51
+-----------------+------------------+----------------+-----------------+-----------------+-----------------+------------------+-----------------+------------------+-----------------+-----------------+------------------+----------------+-----------------+------------------+-----------------+-----------------+----------------+-----------------+------------------+-----------------+-----------------+-----------------+-----------------+
| x13 | x20 | x6 | x32 | x54 | x39 | x28 | x47 | x43 | x24 | x30 | x25 | x2 | x53 | x40 | x23 | x52 | x5 | x18 | x63 | x31 | x59 | x11 | x51 |
+-----------------+------------------+----------------+-----------------+-----------------+-----------------+------------------+-----------------+------------------+-----------------+-----------------+------------------+----------------+-----------------+------------------+-----------------+-----------------+----------------+-----------------+------------------+-----------------+-----------------+-----------------+-----------------+
| table t13 row 9 | table t20 row 10 | table t6 row 1 | table t32 row 3 | table t54 row 6 | table t39 row 7 | table t28 row 10 | table t47 row 5 | table t43 row 10 | table t24 row 1 | table t30 row 3 | table t25 row 10 | table t2 row 8 | table t53 row 2 | table t40 row 10 | table t23 row 9 | table t52 row 2 | table t5 row 3 | table t18 row 7 | table t63 row 10 | table t31 row 8 | table t59 row 6 | table t11 row 3 | table t51 row 6 |
+-----------------+------------------+----------------+-----------------+-----------------+-----------------+------------------+-----------------+------------------+-----------------+-----------------+------------------+----------------+-----------------+------------------+-----------------+-----------------+----------------+-----------------+------------------+-----------------+-----------------+-----------------+-----------------+
1 row in set (0.29 sec)Never mind. How are they doing it? Explain yourself, MySQL. Reveal your secrets.
mysql> EXPLAIN SELECT x13,x20,x6,x32,x54,x39,x28,x47,x43,x24,x30,x25,x2,x53,x40,x23,x52,x5,x18,x63,x31,x59,x11,x51
FROM t43,t52,t32,t53,t28,t5,t47,t51,t31,t13,t40,t18,t24,t20,t63,t30,t59,t39,t54,t25,t23,t11,t6,t2
WHERE a2=b20
AND b25=a20
AND a54=b32
AND b40=a6
AND a28=10
AND a24=b47
AND a25=b23
AND b52=a31
AND a47=b54
AND b31=a30
AND b51=a53
AND b59=a5
AND a11=b13
AND a13=b53
AND a63=b30
AND b43=a18
AND a28=b5
AND b18=a23
AND b24=a40
AND b39=a59
AND a32=b11
AND a39=b63
AND b6=a52
AND b2=a51
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+--------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+--------------------------------------------+
| 1 | SIMPLE | t28 | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |
| 1 | SIMPLE | t5 | NULL | ALL | PRIMARY | NULL | NULL | NULL | 10 | 10.00 | Using where |
| 1 | SIMPLE | t59 | NULL | ALL | PRIMARY | NULL | NULL | NULL | 10 | 10.00 | Using where; Using join buffer (hash join) |
| 1 | SIMPLE | t39 | NULL | ALL | PRIMARY | NULL | NULL | NULL | 10 | 10.00 | Using where; Using join buffer (hash join) |
| 1 | SIMPLE | t63 | NULL | ALL | PRIMARY | NULL | NULL | NULL | 10 | 10.00 | Using where; Using join buffer (hash join) |
| 1 | SIMPLE | t30 | NULL | ALL | PRIMARY | NULL | NULL | NULL | 10 | 10.00 | Using where; Using join buffer (hash join) |
| 1 | SIMPLE | t31 | NULL | ALL | PRIMARY | NULL | NULL | NULL | 10 | 10.00 | Using where; Using join buffer (hash join) |
| 1 | SIMPLE | t52 | NULL | ALL | PRIMARY | NULL | NULL | NULL | 10 | 10.00 | Using where; Using join buffer (hash join) |
| 1 | SIMPLE | t6 | NULL | ALL | PRIMARY | NULL | NULL | NULL | 10 | 10.00 | Using where; Using join buffer (hash join) |
| 1 | SIMPLE | t40 | NULL | ALL | PRIMARY | NULL | NULL | NULL | 10 | 10.00 | Using where; Using join buffer (hash join) |
| 1 | SIMPLE | t24 | NULL | ALL | PRIMARY | NULL | NULL | NULL | 10 | 10.00 | Using where; Using join buffer (hash join) |
| 1 | SIMPLE | t47 | NULL | ALL | PRIMARY | NULL | NULL | NULL | 10 | 10.00 | Using where; Using join buffer (hash join) |
| 1 | SIMPLE | t54 | NULL | ALL | PRIMARY | NULL | NULL | NULL | 10 | 10.00 | Using where; Using join buffer (hash join) |
| 1 | SIMPLE | t32 | NULL | ALL | PRIMARY | NULL | NULL | NULL | 10 | 10.00 | Using where; Using join buffer (hash join) |
| 1 | SIMPLE | t11 | NULL | ALL | PRIMARY | NULL | NULL | NULL | 10 | 10.00 | Using where; Using join buffer (hash join) |
| 1 | SIMPLE | t13 | NULL | ALL | PRIMARY | NULL | NULL | NULL | 10 | 10.00 | Using where; Using join buffer (hash join) |
| 1 | SIMPLE | t53 | NULL | ALL | PRIMARY | NULL | NULL | NULL | 10 | 10.00 | Using where; Using join buffer (hash join) |
| 1 | SIMPLE | t51 | NULL | ALL | PRIMARY | NULL | NULL | NULL | 10 | 10.00 | Using where; Using join buffer (hash join) |
| 1 | SIMPLE | t2 | NULL | ALL | PRIMARY | NULL | NULL | NULL | 10 | 10.00 | Using where; Using join buffer (hash join) |
| 1 | SIMPLE | t20 | NULL | ALL | PRIMARY | NULL | NULL | NULL | 10 | 10.00 | Using where; Using join buffer (hash join) |
| 1 | SIMPLE | t25 | NULL | ALL | PRIMARY | NULL | NULL | NULL | 10 | 10.00 | Using where; Using join buffer (hash join) |
| 1 | SIMPLE | t23 | NULL | ALL | PRIMARY | NULL | NULL | NULL | 10 | 10.00 | Using where; Using join buffer (hash join) |
| 1 | SIMPLE | t18 | NULL | ALL | PRIMARY | NULL | NULL | NULL | 10 | 10.00 | Using where; Using join buffer (hash join) |
| 1 | SIMPLE | t43 | NULL | ALL | NULL | NULL | NULL | NULL | 10 | 10.00 | Using where; Using join buffer (hash join) |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+--------------------------------------------+Interesting. MySQL found a plan where every join is optimized into a hash join. And it did it without having to inspect every single possible plan.
MySQL’s EXPLAIN exposes an important piece of the puzzle by showing us that such an optimization is even possible for this query. It turns out, every similar test in the test suite is amenable to such an optimization, but only if we can identify the join order that allows it. I already said that it’s not possible to efficiently do join planning in the general case. But we don’t need to solve it for the general case: just this specific one.
Dolt already performs something called Functional Dependency Analysis in order to deduce information about the relationships between different columns in a relation. I suspected that it should be possible to use the results of this analysis as a heuristic to guide the join order: pick an order that the heuristic tells us should be the best, then check if it’s good enough. If it is, we’re done! No brute force required.
This approach paid off. I’m skimming over a lot of the details here, because to talk about Functional Dependencies and Join Planning in full would be an entire blog post on its own. Maybe my next post will explore it in more detail since it’s a riveting tale (assuming you like graph theory as much as I do). But the important part is: a query that once took longer to run than the entirety of human civilization now takes a tenth of a second. And although we were targeting a very specific set of benchmark queries with this optimization, we weren’t just “optimizing for the benchmark”. The improvements that we made to join planning will likely have a positive impact on many user queries as well.
Finally, after I finished this I realized that MySQL doesn’t actually find the best plan for every single one of these test cases, only some of them. And for many of them, especially the larger ones, it still times out. But Dolt handles them all now. Does that mean that Dolt is now more MySQL compliant than MySQL? Because that would be a great marketing line.
Looking Past The Finish Line#
And after that, we made it. 99.99% correctness on sqllogictests. A collection of six million tests and we now handled all but six hundred of them.
So we have four nines. That means five nines is next, right?
Well, maybe. But maybe not.
We want Dolt to be as correct as it can be, but there’s a lot more to correctness than a single set of benchmarks. And as comprehensive as sqllogictests is, it still doesn’t cover everything. We know that theres some types of queries that don’t occur at all in its tests, and unlike SECONDARY_ENGINE, some of those queries are things that users actually need. Having healthy benchmarks is good, but it only goes so far, especially if the tests don’t cover all of the actual use cases we see.
That’s why we’re in the process of improving our test coverage by adding other benchmarks to our suite, including
When we add these benchmarks, we expect our correctness percentage to go down. In fact, we hope it does, because that means that we’re actually improving our test coverage and making our conformance assessment more accurate.
99.99% is just a number. Up until now, we’ve been improving Dolt’s correctness by raising this number. Perhaps now it’s time to improve Dolt’s correctness by lowering it… so we can raise it again.
No matter what happens next, we’ll keep you updated.
(And as always, if you have thoughts about conformance testing, or if want to chat with us, you can always reach out on Twitter, Discord, or GitHub.)