
Dolt is a version controlled database. How would you use such a thing?
Does your business create data? How do you maintain and compare many copies of that data? Do the people that create the data make mistakes? What’s the process to recover from mistakes when they occur? Is it painful?
Once you generate the data, how do you use it? Do you use the data in Machine Learning pipelines? Do you use ML to fill in data gaps? How do you compare the fill results of different ML models?
Turbine chose Dolt to solve the data generation and model training challenges above for cancer cell behavior data. Turbine is one of Dolt’s first customers. In this blog we’ll tell their story.

Before Dolt#
Turbine builds virtual cancer cells and uses AI to train their behavior to match biology. Simulating how these virtual cells react to different methods of intervention allows the company to deliver value and drive efficiency throughout the drug development pipeline. One of such virtual cell’s underlying database consists of dozens of tables, containing gigabytes of biological data points. Turbine needs to keep track of different versions of virtual cells so they can reproduce simulation results and improve their model.
Turbine builds its simulations on top of a huge collection of biological data containing cell lines, mutations, drug effects and the connections between all of these. This complex data is continuously extended with the addition of newly acquired measurements, information about new proteins, or simply, the calibration of the parameters describing the behavior of the system.
The data is altered in multiple ways: new data can be imported, AI algorithms might fine tune the parameters that influence the model behavior, and even biologists may manually alter the network. This work is distributed among many teams, who might work on different projects.
Here are some examples of the types of projects being executed in parallel by research teams:
- Extend the model requiring change to the schema itself.
- Expand the network with new proteins .
- Calibrate the model parameters by automatically fine-tuning parameters with AI scripts based on new laboratory results.
All of this change should preserve the system’s integrity at all times, allowing each team to proceed independently, so different stable versions should be available simultaneously.
Before migrating to Dolt’s distributed branch and merge technology, all of this work was done in a MongoDB instance. MongoDB’s flexibility was a great solution for rapid prototyping, but it didn’t provide the stability and integrity that Turbine needed: data consistency and real, git-like versioning and branching. Users used to change documents that were used by other teams, and the lack of foreign keys caused integrity issues; all of which was identified much later, when biologists started to interpret simulation outputs.
How they found us#
Turbine’s CTO, Kristof Szalay, saw one of Dolt’s original viral HackerNews posts. He was intrigued because he thought applying the Git version control model to a database could fix Turbine’s data consistency issues and allow Turbine to manage multiple versions of their simulation data more efficiently.
He sent us an email and we set up a meeting. From the start, Turbine knew what they were getting into.
“This is such a big problem for us, we’re willing to go through the pain of being early adopters”.
Turbine’s Requirements#
Turbine needed Dolt’s version control features but they also needed a full featured, fast OLTP database. Turbine would make use of foreign keys for data quality. Queries would be complex, often joining over ten tables.
Turbine set the requirement that no query slower than 20X MySQL. This was the line in the sand. They would provide all the queries and give us the opportunity to optimize Dolt for them. We were given two months to make approximately 100 queries work within these requirements.
The Journey#
It’s important to note that at the time, Dolt had just started support greater than 2 table JOINs. Turbine’s simulation queries had 16 table JOINs. Of the 100 or so queries provided, approximately 30 did not meet the 20X criteria. Some were just slower than 20X MySQL. Some did not return at all.
We were able to optimize a query every two days or so at the same time converting our immature SQL engine into something more mature. Turbine’s use case made Dolt’s SQL engine into something we imagined could be used as an Online Transaction Processing (OLTP) database engine, the thrust of our work today.
In March 2021, we got the all clear from Turbine that Dolt had passed proof of concept and would be put in production. Turbine worked for the next few months to migrate their applications and machine learning pipelines to Dolt. Dolt currently runs in production. Here’s Turbine’s latest commit graph.
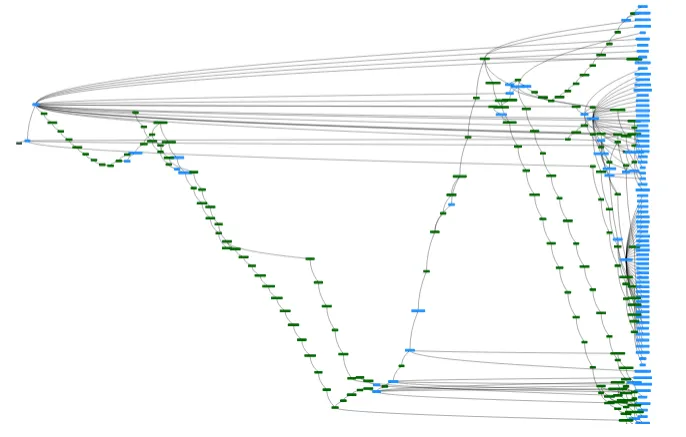
The Result#
The Turbine Application#
Turbine now deploys an application backed by a central Dolt database that is used by multiple teams. Turbine added a branch, diff and merge workflow to the application to facilitate collaboration amongst the teams. The teams now work on their own branches and share changes with each other when they are ready. Teams run simulations based off specific commits for reproducibility. The simulations spin up dozens of compute nodes and read from Dolt with the extremely complex queries mentioned above.
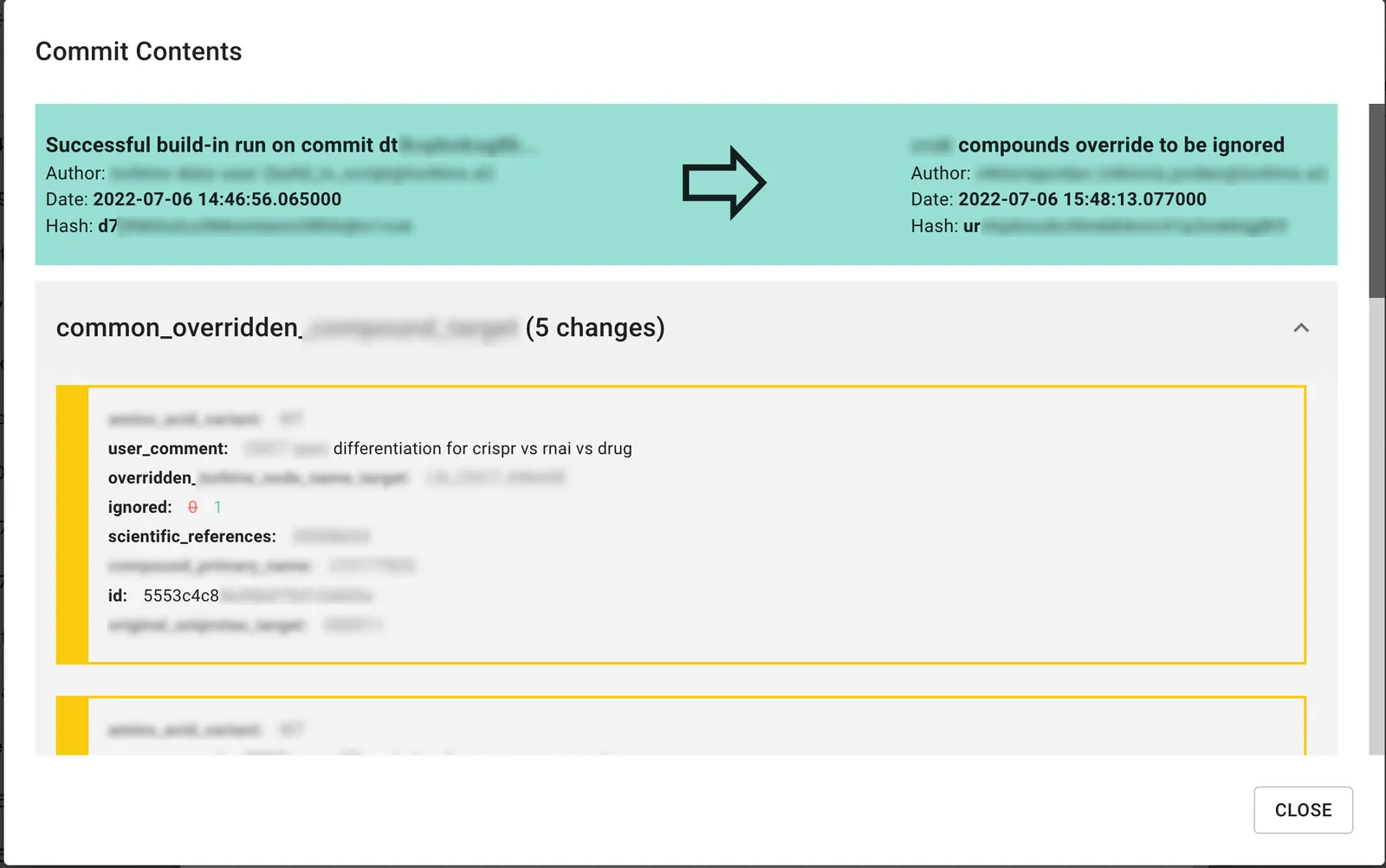
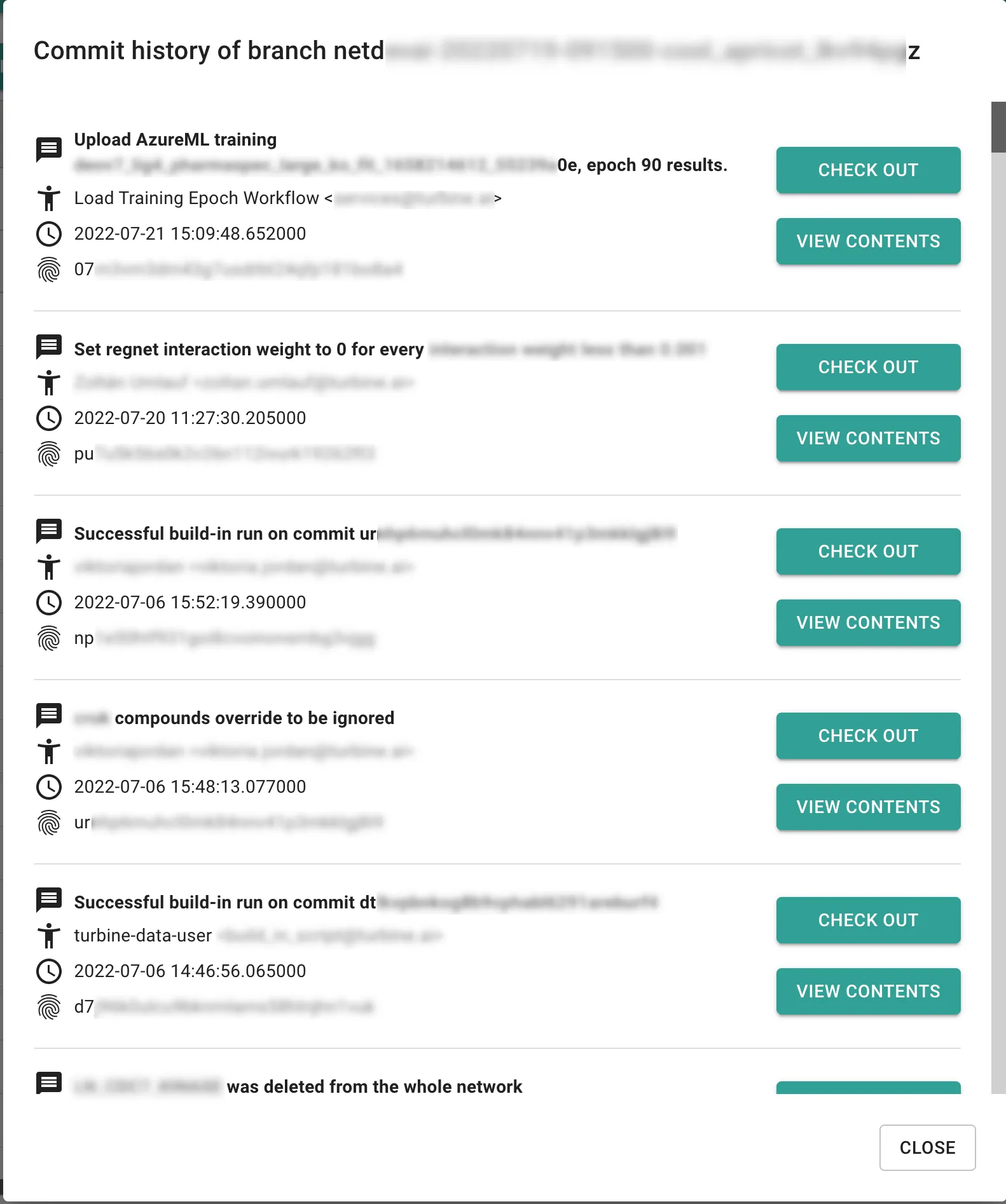
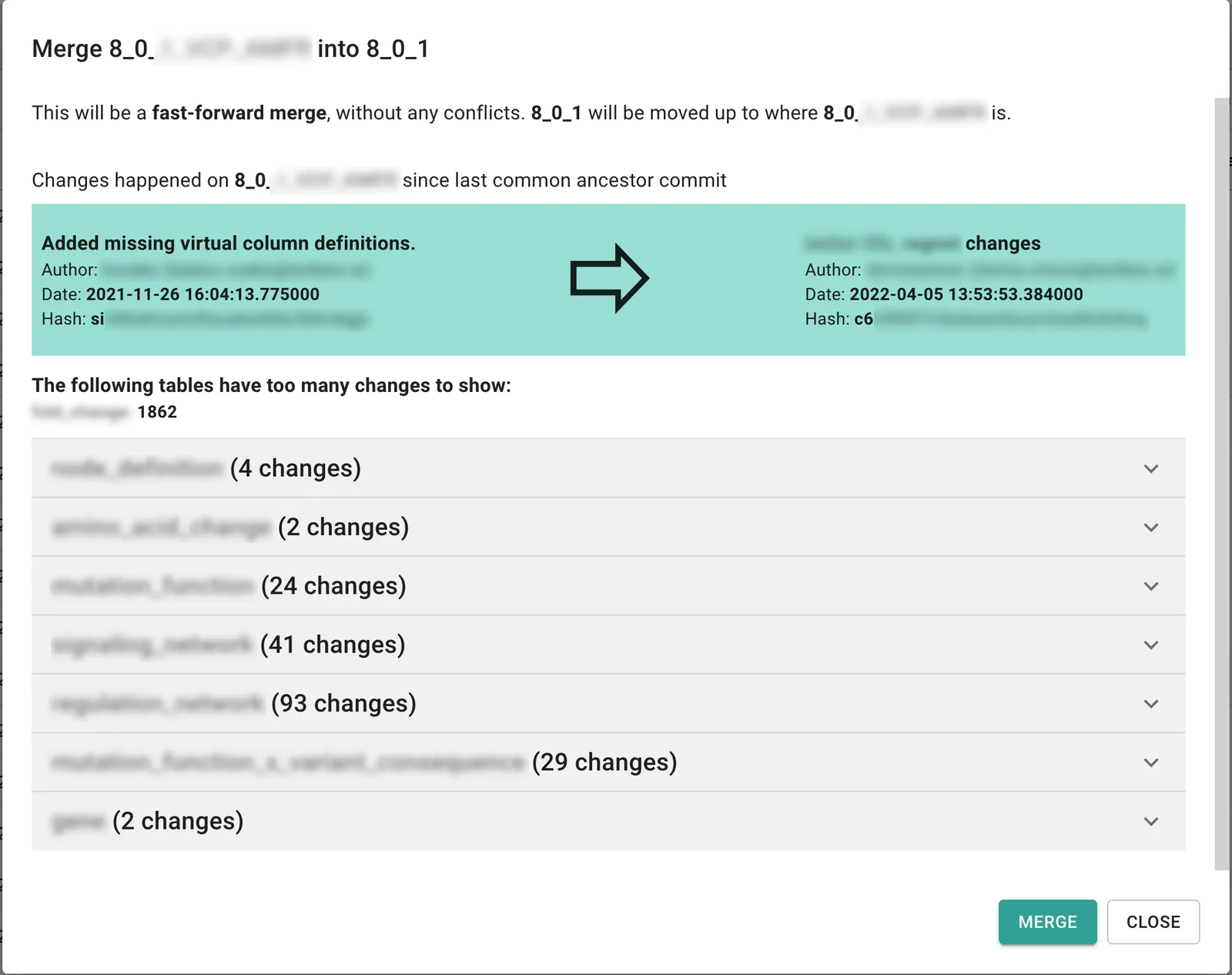
Below find images of their commit information, history, and merge differences pages. The application is modern, getting users the versioning information when they need it. This is made possible by Dolt’s ability to expose versioning data via SQL. Note, confidential information is blurred out for this public blog.
Notice in the commit information page, users can enter human descriptions of their changes and see the differences created by a specific commit.
On the commit history page you can see the sequence of changes that led to your current state and rewind to any specific commit using the “CHECK OUT” button.
Finally, when you are ready to merge, the application shows the differences between the two copies you would like to merge.
Anecdotally, in the process of migrating to Dolt, Turbine had a Dolt logo as a sticker in their internal Discord. About three times per week as they were dealing with a data quality issue they tell us that they would respond with the Dolt logo in chat, as to say “Dolt will fix this”. Turbine reports error free data ingestion made possible by their migration to Dolt.
Machine Learning#
Turbine’s machine learning pipeline is powered off of Dolt. Turbine uses machine learning to “fine tune” the cancer cell simulation. Multiple models are run and the results are compared to see which one performed best.
Dolt allows full reproducibility of all Turbine’s models. Each model is trained at an immutable Dolt commit. This means Turbine can always recreate a model. Moreover, Turbine uses Dolt’s branch features to organize their machine learning data saving operations work.
Performance#
Turbine shared the following performance results with us, comparing Dolt, MySQL, and MongoDB for their use case. These are large scale analytical queries with the numbers in the headers representing the number of dimensions in their queries.
10Clx100drug 100Clx10drug 100Clx200drug
mysql 0:00:59 0:01:12 0:30:20
dolt 0:02:55 0:04:31 0:40:29
mongodb 0:11:41 0:36:42 0:56:40As you can see, for these large scale analytical queries, Dolt is between 50% and 400% slower than MySQL, converging on parity as the queries get larger. Not bad, certainly outperforming the 4-5X on average we report for the sysbench test suite.
Somewhat surprisingly, Dolt is up to 8X faster than MongoDB for this use case. Benchmarking Dolt against MongoDB is not easy because Dolt and MongoDB have entirely different storage and query syntax. Any attempt at an apples-to-apples benchmark would be unfair. However, surprisingly, Dolt is faster than Turbine’s previous solution.
Conclusion#
Turbine is close to the canonical Dolt use case. Use Dolt to decentralize your data collection or generation processes to reduce operational issues. Use branch, diff, and merge to improve data quality even further. Once you have great data use Dolt’s version control capabilities to help you iterate faster on and compare machine learning models.
Sound like something that could help you at your company? Join our Discord and let’s discuss your use case.