
Dolt is the world’s first version controlled SQL database. How would you build such a thing?
A few months ago, I wrote an article outlining the motivations, requirements, and choices that led to Dolt’s Architecture. Today, in the next article in my architecture series, I am going to focus on Dolt’s storage engine architecture in similar detail.
Dolt’s storage engine is heavily influenced and shares code with Noms. We here at DoltHub have immense respect for the Noms team’s pioneering work, without which Dolt would not exist.
Motivation: Database Version Control#
Dolt’s storage engine is motivated by the desire to add Git-style version control to databases. Both Noms and Dolt share this vision. Noms attempts to achieve the vision on a generic, document-like database while Dolt restricts the vision to an Online Transaction Processing (OLTP) SQL database. Currently, Noms is not under active development while Dolt is.

Git-style version control on a database provides a number of useful features including:
- Instantaneous rollback to any previous state
- A full, queryable audit log of all data back to inception
- Multiple evolving branches of data
- The ability to merge data branches
- Fast synchronization with remote versions for backup or decentralized collaboration
- Queryable differences (ie. diffs) between versions
Requirements#
As noted in an earlier, requirements exercise for Dolt itself, a storage engine for a SQL database with Git-style versioning would provide:
- Tables
A SQL database is a collection of tables. Tables have rows and columns. The columns have schema: names, types, and constraints. Columns can have indexes to improve query performance. Advanced database features like views, stored procedures, and triggers would also be useful. Tables must be able to be accessed via standard SQL select, insert, update, and delete queries.
- Performance at Scale
A modern relational database must be performant at large scale. In particular, sub-linear worst case scaling on seek (ie. select) is a must.
- Fast diff
Comparing and producing the differences between two versions must be fast. Displaying diffs to a user is a common operation. Querying diffs must also be supported and should be as fast as a regular select query. Moreover, merge relies on diffs so fast diff is essential for merge operations at scale.
- Structural Sharing
To offer version control in a database, all versions of the data must be stored. Storing a full copy of the database at every change is untenable. Data that does not change between versions must share storage.
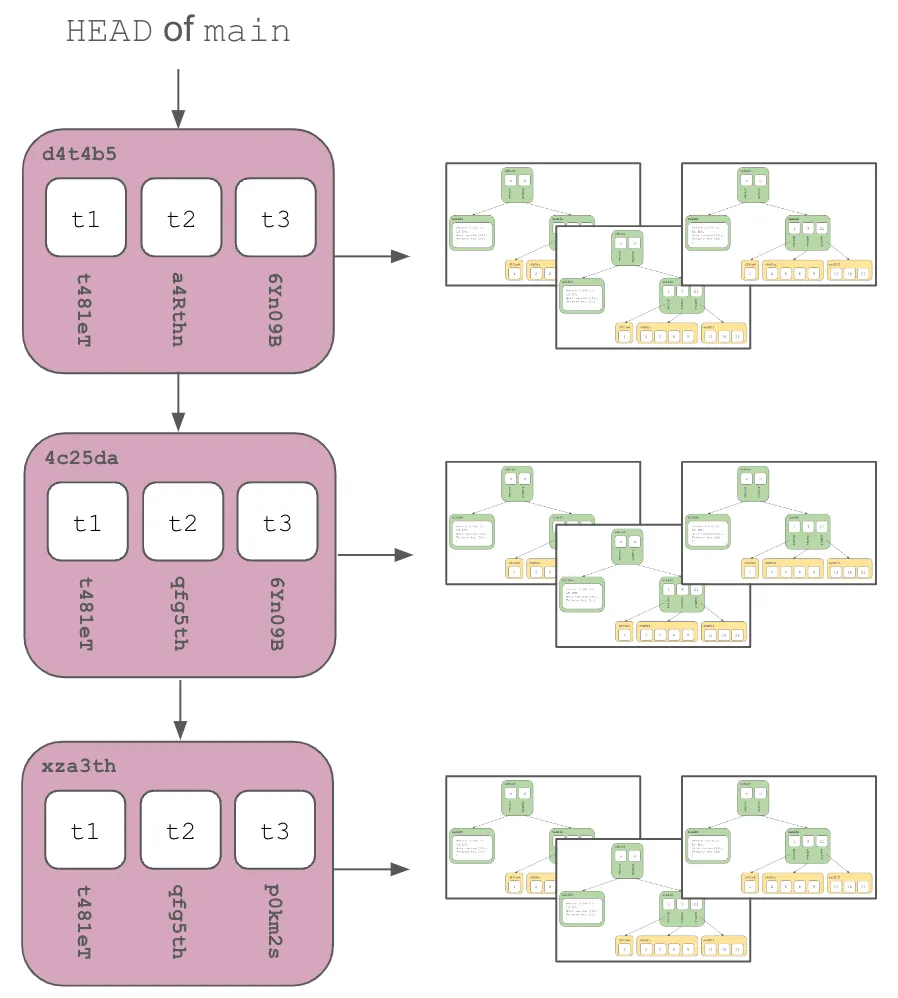
Prolly Trees + Commit Graph = Dolt Storage Engine#
Dolt’s storage engine is built on a Git-style commit graph of Prolly Trees. Table schema and data is stored in Prolly Trees. The roots of those Prolly Trees along with other metadata are stored in a commit graph to provide Git-style version control. We’ll start by explaining Prolly Trees and then show how these fit into a commit graph.
The Database Backbone: Search Trees#
Databases are built on top of Search Trees, a class of data structure. Most databases are built on B-trees.
Dolt is built on a novel Search Tree, closely related to a B-tree, called a Probabilistic B-Tree, or Prolly Tree for short. As far as we can tell, Prolly Trees were invented by the Noms team specifically for database version control and they also coined the term.
B-Trees#
Most SQL databases you are familiar with, like Postgres or MySQL, are built on B-tree storage. Tables are represented as a map of primary keys to values and the keys of that map are stored in a B-tree. Values are stored in the leaf nodes.
B-tree storage allows for fast seek (ie. select) with reasonable write performance (ie. insert, update, delete). B-trees have proven to be the ideal data structure to back databases.
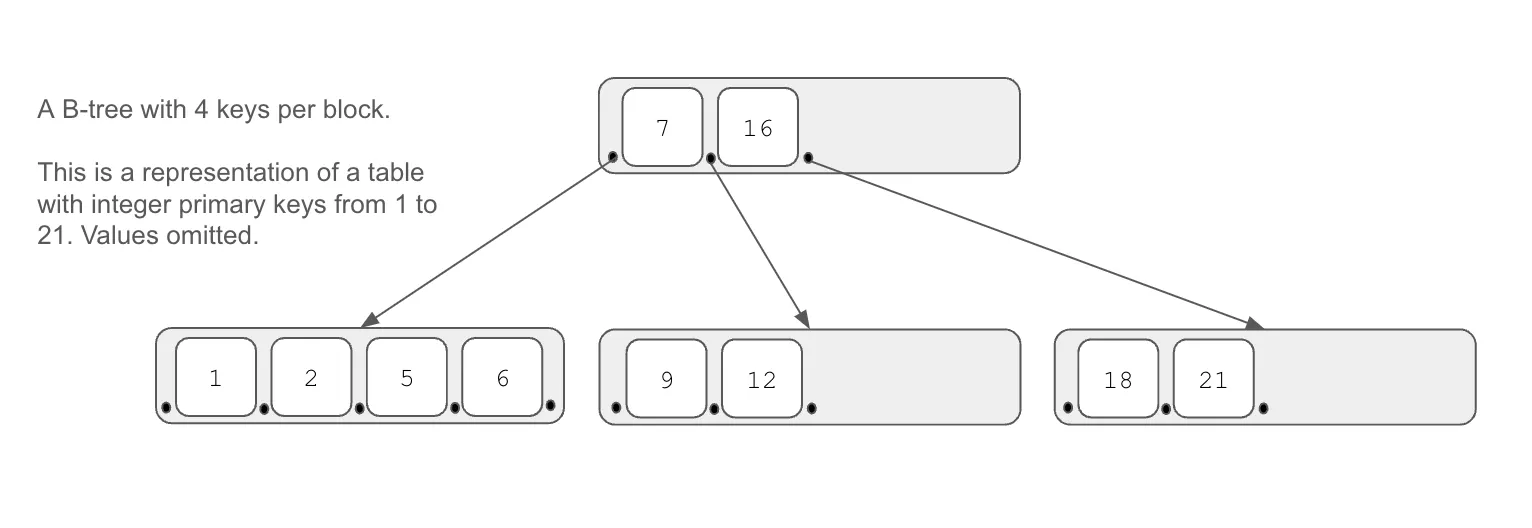
However, finding the differences between two B-trees requires scanning both trees and comparing all values, an operation that scales with the size of the tree. This operation is slow for large trees.
Also, writes to B-trees are not history independent, the order of the writes internally changes the structure of the tree. Thus, storage cannot be easily shared between two versions of the same tree.
Prolly Trees#
A Prolly Tree, or Probabilistic B-tree, is a content-addressed B-tree.
Similarly to B-trees, a map of primary keys to values are used to represent tables. Keys form the intermediary nodes and values are stored in the leaf nodes. Because of their similarity to B-trees, Prolly trees approximate B-tree performance of basic SQL database read and write operations like select, insert, update, and delete. Content-addressing allows for fast comparison (ie. diff) and structural sharing of versions.
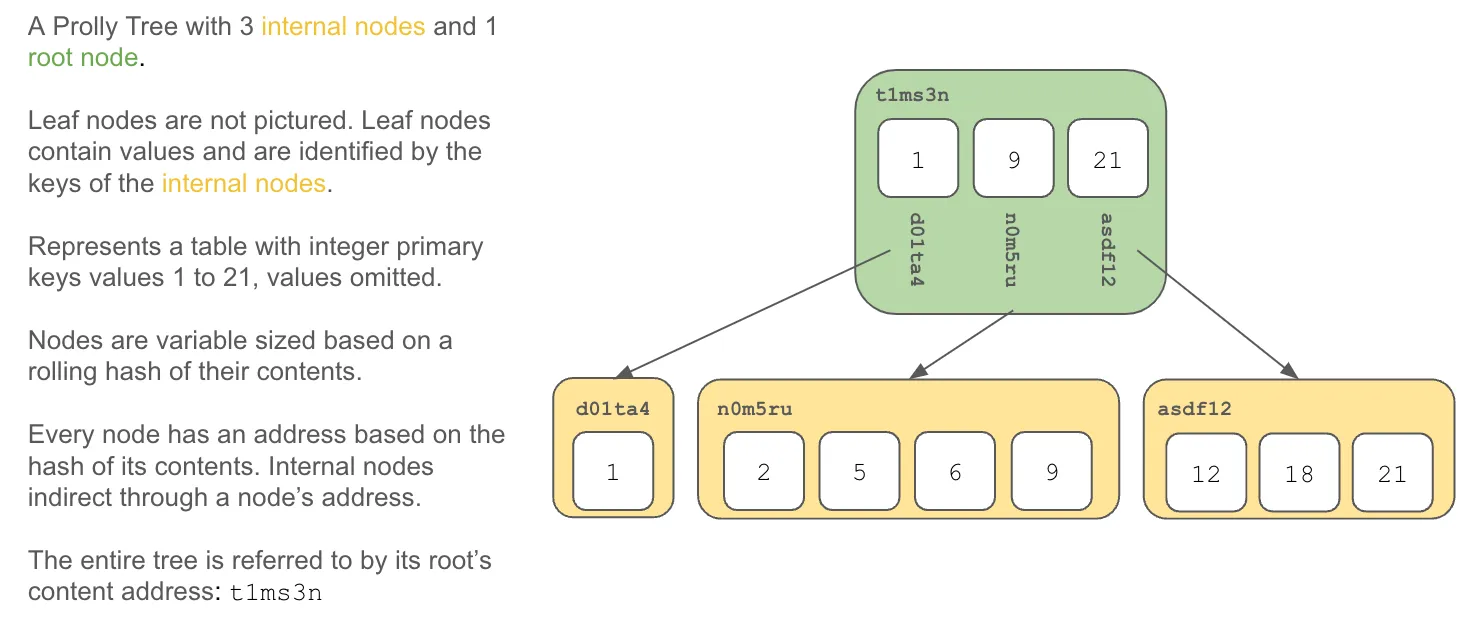
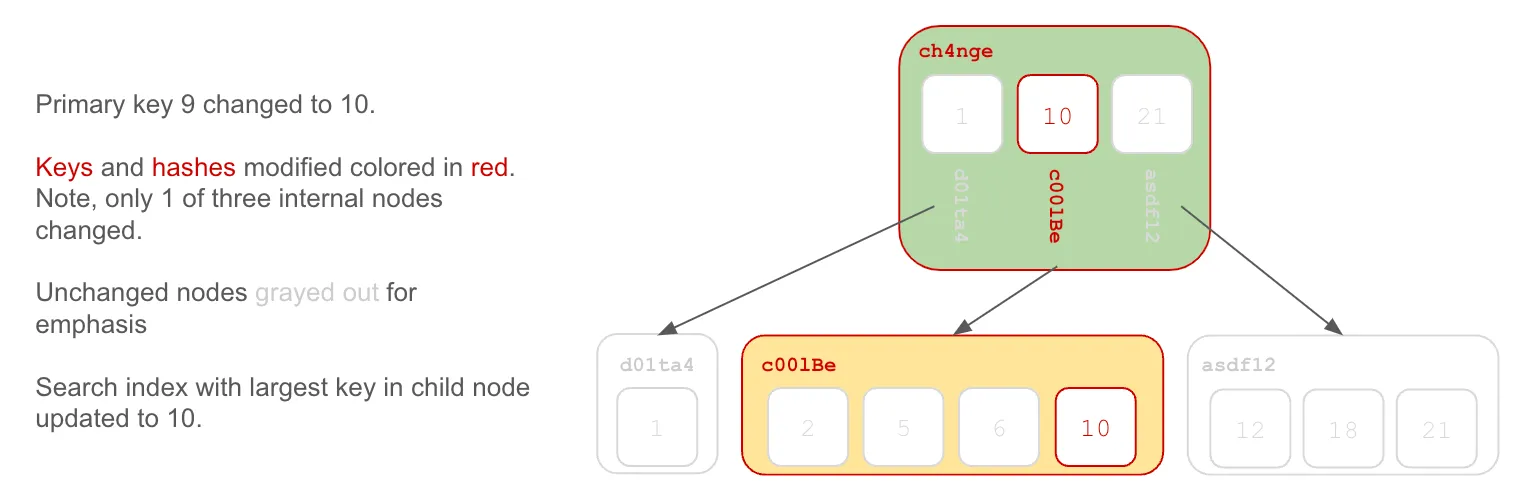
In Prolly Trees, each internal node in the B-tree is labelled with an immutable, history independent hash or content address built from the node’s contents. This allows fast comparison of two Prolly Trees. One simply needs to look at the root hash of the tree to tell if two trees are different. Walking the tree following paths with nodes of different values quickly identifies differences in the tree. Thus, calculating the difference between two Prolly trees scales with the size of the differences, not the size of the tree.
Moreover, sections of the tree that share the same root hash can share storage between versions because the contents of the trees are necessarily the same. When laid out in a commit graph, Prolly Tree roots share storage if the root hash of the tree or any sub-tree are the same in each version.
Prolly trees are described in more detail here.
Comparison#
The Noms documentation provides the following useful algorithmic, big O() comparison of B-trees and Prolly Trees:
| Operation | B-Trees | Prolly Trees |
|---|---|---|
| 1 Random Read | logk(n) | logk(n) |
| 1 Random Write | logk(n) | (1+k/w)*logk(n) |
| Ordered scan of one item with size z | z/k | z/k |
| Calculate diff of size d | n | d |
| Structural sharing | ❌ | ✅ |
n: total leaf data in tree, k: average block size, w: window width
As you can see a Prolly Tree approximates B-tree performance on reads and writes while also offering the ability to compute differences in time proportional to the size of differences rather than the total size of the data.
Commit Graph#
Effectively, Prolly Tree storage laid out in a Commit Graph, or Merkle DAG of versions, allows for Git-style version control on a SQL database. Dolt, the world’s first version controlled SQL database, is working proof of the combination of a Commit Graph with Prolly Trees effectiveness.
How do we turn the table data storage described above into a SQL database? We must make all the contents of the database Prolly Trees and hash the roots together. The data in tables is by far the most complex tree. But in Dolt, it’s Prolly Trees all the way down.
Table data is stored in a Prolly Tree as described above: a map of primary keys to the values in additional columns. Thus, each table version has an immutable hash of the data in the table. In SQL, tables also have schema. Table schema is stored in a much simpler Prolly Tree and given a content address. The combination of the roots of the schema and data Prolly Trees form the content address of the table.
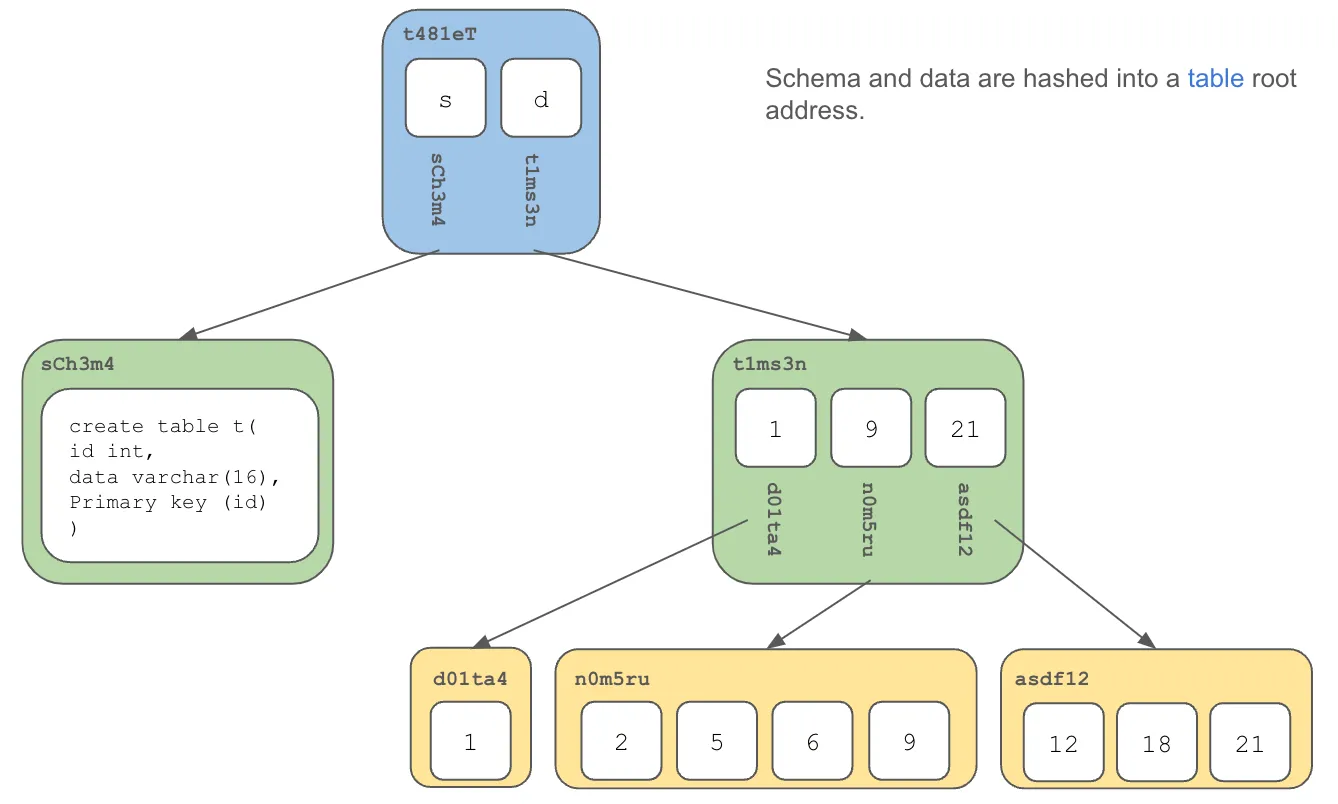
The content addresses of the tables in the database are then hashed to form the content address of the database.
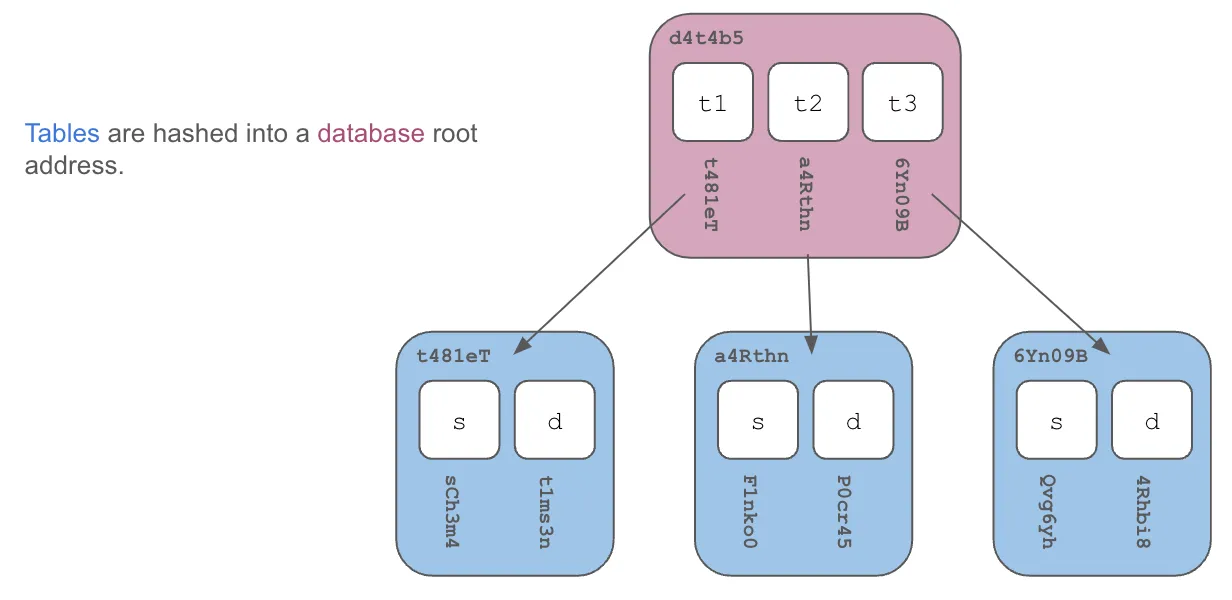
Finally, we lay these database roots out in a commit graph of database versions. Any subtree where the roots have the same content-address are only stored once, accomplishing structural sharing.
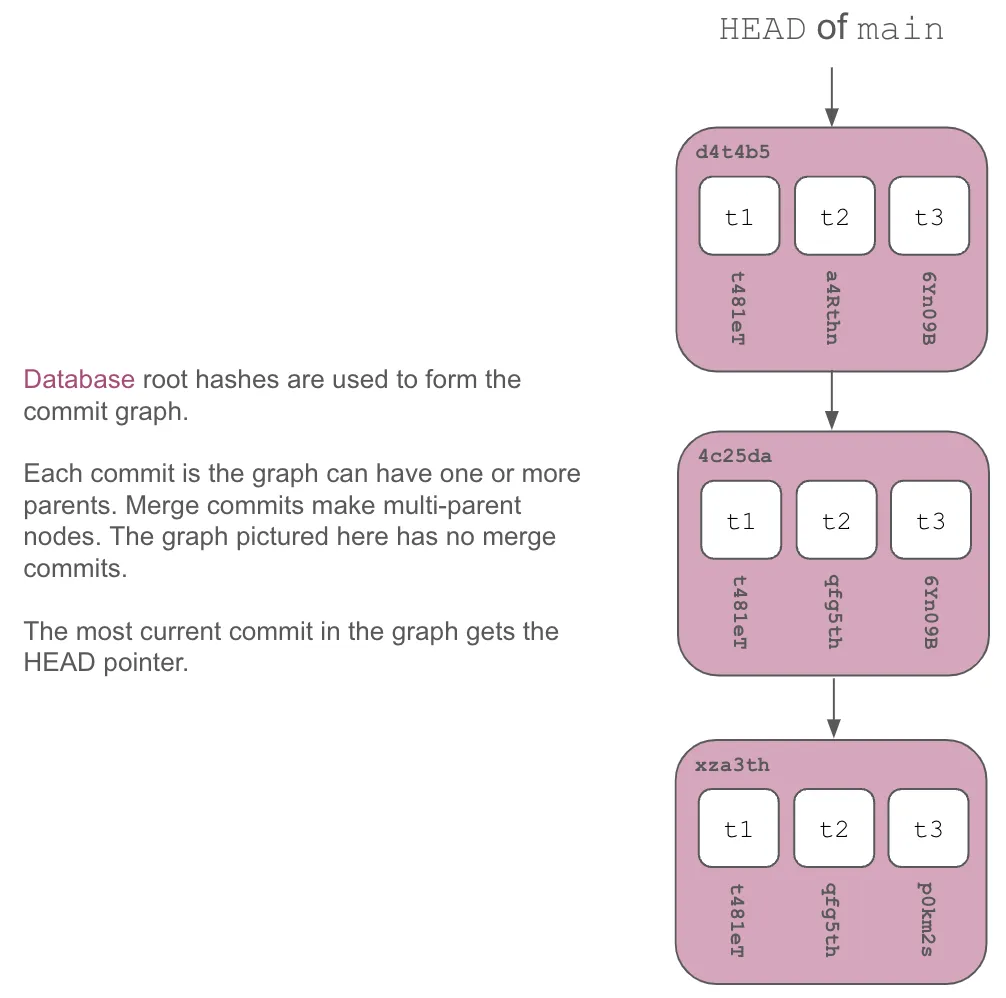
And, thus, you end up with Dolt’s storage engine.
The Dolt commit graph is described in more detail here, specifically how it enables diffs, branches, and merges.
Further Reading#
Aaron has blogged in detail over time about various elements of our storage engine. The final blog. “How to Chunk Your Database into a Merkle Tree” details changes we made between version one and version two of the storage engine. At this point, Dolt’s storage engine deviated significantly from Noms.
- How Dolt Stores Table Data
- The Dolt Commit Graph and Structural Sharing
- Efficient Diff on Prolly Trees
- Cell-level Three-way Merge in Dolt
- Dolt Implementation Notes — Push And Pull On a Merkle DAG
- How to Chunk Your Database into a Merkle Tree
Conclusion#
As you can see, Dolt uses Prolly Tree storage of schema and data laid out in a commit graph to achieve database version control at the storage layer. Curious to learn more? Come by our Discord and ask us some questions.