
Dolt is a MySQL-compatible version-controlled database. It’s the only SQL database with branches that you can diff, merge and sync. Over the past year, performance has been a central focus of Dolt development. Our long-term goal is to be as performant as MySQL. But what does performance parity mean exactly? Today we’ll talk about the present and future of Dolt benchmarks and see how we stack up against MySQL on the TPC-C benchmark.
Sysbench vs TPC-C#
Currently, Dolt uses Sysbench to measure its primary performance metrics. To this point, Sysbench has been a valuable tool in improving system performance. However, there are two major drawbacks to this approach. First, each Sysbench benchmark focuses on the single-threaded performance of an individual query. This is useful for characterizing the performance of basic access patterns like insert and point lookups, but fails to replicate a realistic workload for the database. Secondly, our suite of benchmarks has consistently changed over time as we find new queries we need to optimize. These new benchmarks provide us with important metrics about Dolt, but they complicate our ability to measure changes over time.
TPC-C is an industry standard benchmark measuring the transactional throughput of a database. It simulates a real-world workload through a mix of complex, concurrent transactions. Each transaction is composed of multiple queries and contains a mix of reads and writes:
TPC-C simulates a complete computing environment where a population of users executes transactions against a database. The benchmark is centered around the principal activities (transactions) of an order-entry environment. These transactions include entering and delivering orders, recording payments, checking the status of orders, and monitoring the level of stock at the warehouses.
Running TPC-C on Dolt#
We first ran TPC-C against Dolt last October. At that time, our transactional support was brand new and we had to significantly modify the benchmark in order to get it running. Since then, we’ve rewritten our storage engine and greatly improved our capabilities as an OLTP database. Today, you can run TPC-C against Dolt out-of-the-box. If you’d like to run it yourself, check out this script in our Github repo.
Our default scale parameters are still relatively small; we create a single warehouse and use only 2 concurrent threads. We run the benchmark for 10 seconds with a 1 second reporting interval. To get a sense for how much progress we’ve made, let’s compare the results for the old and new storage formats. TPC-C reports both transactions-per-second (tps) and queries-per-second (qps). Each transaction runs 30 queries on average. First the old storage format:
[ 1s ] thds: 2 tps: 1.00 qps: 54.89 (r/w/o: 24.95/25.95/3.99) lat (ms,95%): 155.80 err/s 0.00 reconn/s: 0.00
[ 2s ] thds: 2 tps: 1.00 qps: 34.01 (r/w/o: 14.00/18.01/2.00) lat (ms,95%): 1533.66 err/s 0.00 reconn/s: 0.00
[ 3s ] thds: 2 tps: 3.00 qps: 29.00 (r/w/o: 12.00/11.00/6.00) lat (ms,95%): 1903.57 err/s 0.00 reconn/s: 0.00
[ 4s ] thds: 2 tps: 0.00 qps: 27.00 (r/w/o: 12.00/15.00/0.00) lat (ms,95%): 0.00 err/s 0.00 reconn/s: 0.00
[ 5s ] thds: 2 tps: 2.00 qps: 44.00 (r/w/o: 19.00/21.00/4.00) lat (ms,95%): 2159.29 err/s 0.00 reconn/s: 0.00
[ 6s ] thds: 2 tps: 0.00 qps: 30.00 (r/w/o: 14.00/16.00/0.00) lat (ms,95%): 0.00 err/s 0.00 reconn/s: 0.00
[ 7s ] thds: 2 tps: 1.00 qps: 42.00 (r/w/o: 17.00/23.00/2.00) lat (ms,95%): 2045.74 err/s 0.00 reconn/s: 0.00
[ 8s ] thds: 2 tps: 2.00 qps: 48.00 (r/w/o: 22.00/22.00/4.00) lat (ms,95%): 5607.61 err/s 0.00 reconn/s: 0.00
[ 9s ] thds: 2 tps: 0.00 qps: 61.00 (r/w/o: 31.00/30.00/0.00) lat (ms,95%): 0.00 err/s 0.00 reconn/s: 0.00
[ 10s ] thds: 2 tps: 2.00 qps: 38.00 (r/w/o: 17.00/17.00/4.00) lat (ms,95%): 2632.28 err/s 0.00 reconn/s: 0.00
[ 11s ] thds: 1 tps: 1.00 qps: 28.00 (r/w/o: 13.00/14.00/1.00) lat (ms,95%): 3151.62 err/s 0.00 reconn/s: 0.00
[ 12s ] thds: 1 tps: 0.00 qps: 20.00 (r/w/o: 10.00/10.00/0.00) lat (ms,95%): 0.00 err/s 0.00 reconn/s: 0.00
SQL statistics:
queries performed:
read: 208
write: 227
other: 28
total: 463
transactions: 14 (1.13 per sec.)
queries: 463 (37.40 per sec.)
ignored errors: 0 (0.00 per sec.)
reconnects: 0 (0.00 per sec.)We’re getting a little over 1 transaction per second (tps). That’s bad! You might actually do better yourself with pencil and paper. For context, MySQL can process about 220 tpc using this same configuration. The reason behind this slowness is explain in depth in our original post about TPC-C. Thankfully there’s some good news, the new format is way faster:
[ 1s ] thds: 2 tps: 19.96 qps: 724.52 (r/w/o: 330.32/352.28/41.91) lat (ms,95%): 170.48 err/s 0.00 reconn/s: 0.00
[ 2s ] thds: 2 tps: 26.01 qps: 771.24 (r/w/o: 356.11/361.11/54.02) lat (ms,95%): 164.45 err/s 1.00 reconn/s: 0.00
[ 3s ] thds: 2 tps: 32.97 qps: 788.26 (r/w/o: 351.67/368.65/67.94) lat (ms,95%): 170.48 err/s 1.00 reconn/s: 0.00
[ 4s ] thds: 2 tps: 24.02 qps: 759.70 (r/w/o: 339.31/368.34/52.05) lat (ms,95%): 176.73 err/s 2.00 reconn/s: 0.00
[ 5s ] thds: 2 tps: 22.00 qps: 628.03 (r/w/o: 296.01/282.01/50.00) lat (ms,95%): 314.45 err/s 4.00 reconn/s: 0.00
[ 6s ] thds: 2 tps: 29.00 qps: 835.97 (r/w/o: 373.99/399.98/62.00) lat (ms,95%): 158.63 err/s 2.00 reconn/s: 0.00
[ 7s ] thds: 2 tps: 29.00 qps: 842.08 (r/w/o: 385.04/399.04/58.01) lat (ms,95%): 164.45 err/s 0.00 reconn/s: 0.00
[ 8s ] thds: 2 tps: 23.00 qps: 777.95 (r/w/o: 356.98/371.98/49.00) lat (ms,95%): 173.58 err/s 2.00 reconn/s: 0.00
[ 9s ] thds: 2 tps: 27.00 qps: 725.00 (r/w/o: 331.00/339.00/55.00) lat (ms,95%): 153.02 err/s 0.00 reconn/s: 0.00
[ 10s ] thds: 2 tps: 21.00 qps: 786.04 (r/w/o: 361.02/379.02/46.00) lat (ms,95%): 161.51 err/s 3.00 reconn/s: 0.00
SQL statistics:
queries performed:
read: 3520
write: 3661
other: 538
total: 7719
transactions: 256 (25.19 per sec.)
queries: 7719 (759.48 per sec.)
ignored errors: 15 (1.48 per sec.)
reconnects: 0 (0.00 per sec.)Much better! We designed the new storage engine specifically for transactional workloads. We don’t want our users to choose between the version control features of Dolt and the speed of MySQL. We want to have both! As you can see, we’re still about 9x slower than MySQL on TPC-C, but we’ve made major gains in the past year. By comparison, we’re only 3x slower on our Sysbench metrics when averaging the results of all tests. The contrast in these results shows the difference between Sysbench and TPC-C. The more realistic workload of TPC-C is finding performance bottlenecks that don’t exist in our micro-benchmarks.
Digging Deeper#
To get a sense of where these bottlenecks exist, let’s inspect latency distribution of the queries in the benchmark. We’ve grouped these queries into four categories: point selects, writes, commits, and joins. Inserts, updates and deletes are largely equivalent to the storage engine, so we combine them into a single category here.
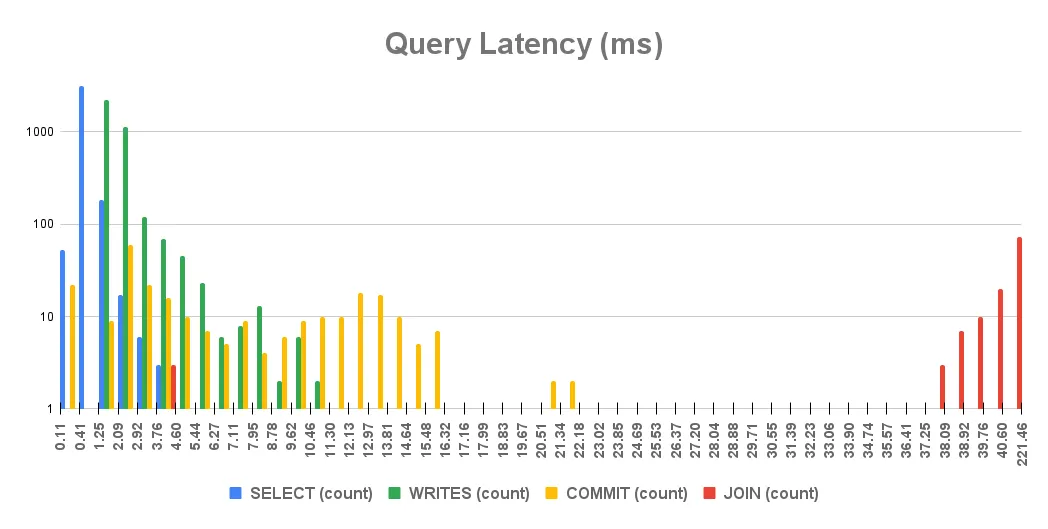
Points selects and writes are the most common query types and also the fastest. Writes are slightly slower than point selects and also have a somewhat wider distribution of latencies. The slowest point selects take around 4 ms while the slowest writes take up to 11 ms. The next most common query is commit which closes each transaction. This query is naturally slower as it is responsible for atomically writing transaction data to persistent storage. In Dolt’s transaction model concurrent transactions perform a merge operation when committing. This additional work is partially responsible for latency of commits.
The slowest query type, by far, are joins. The latency distribution of joins is nearly disjoint from the other queries.
The right side of the chart has been truncated for clarity; the mean latency of join queries, 41 ms, is just barely in
frame. TPC-C runs two types of join queries, let’s inspect the queries themselves and see what’s going on. We can use
the MySQL’s explain syntax to analyze the query plan that Dolt is using:
> explain SELECT c_discount, c_last, c_credit, w_tax FROM customer1, warehouse1
WHERE w_id = 1 AND c_w_id = w_id AND c_d_id = 1 AND c_id = 1019;
+-------------------------------------------------------------------------------------------------+
| plan |
+-------------------------------------------------------------------------------------------------+
| Project |
| ├─ columns: [customer1.c_discount, customer1.c_last, customer1.c_credit, warehouse1.w_tax] |
| └─ IndexedJoin(customer1.c_w_id = warehouse1.w_id) |
| ├─ IndexedTableAccess(warehouse1) |
| │ ├─ index: [warehouse1.w_id] |
| │ ├─ filters: [{[1, 1]}] |
| │ └─ columns: [w_id w_tax] |
| └─ Filter((customer1.c_d_id = 1) AND (customer1.c_id = 1019)) |
| └─ IndexedTableAccess(customer1) |
| ├─ index: [customer1.c_w_id,customer1.c_d_id,customer1.c_id] |
| └─ columns: [c_id c_d_id c_w_id c_last c_credit c_discount] |
+-------------------------------------------------------------------------------------------------+> explain SELECT COUNT(DISTINCT (s_i_id)) FROM order_line1, stock1
WHERE ol_w_id = 1 AND ol_d_id = 4 AND ol_o_id < 3010 AND ol_o_id >= 2990 AND s_w_id= 1 AND s_i_id=ol_i_id AND s_quantity < 18
+--------------------------------------------------------------------------------------------------------+
| plan |
+--------------------------------------------------------------------------------------------------------+
| GroupBy |
| ├─ SelectedExprs(COUNTDISTINCT([stock1.s_i_id])) |
| ├─ Grouping() |
| └─ IndexedJoin(stock1.s_i_id = order_line1.ol_i_id) |
| ├─ IndexedTableAccess(order_line1) |
| │ ├─ index: [order_line1.ol_w_id,order_line1.ol_d_id,order_line1.ol_o_id,order_line1.ol_number] |
| │ ├─ filters: [{[1, 1], [4, 4], [2990, 3010), [NULL, ∞)}] |
| │ └─ columns: [ol_o_id ol_d_id ol_w_id ol_i_id] |
| └─ Filter((stock1.s_w_id = 1) AND (stock1.s_quantity < 18)) |
| └─ IndexedTableAccess(stock1) |
| ├─ index: [stock1.s_i_id] |
| └─ columns: [s_i_id s_w_id s_quantity] |
+--------------------------------------------------------------------------------------------------------+
Looking at the query plan, we can see that these queries are being executed as indexed joins. Dolt’s analyzer has detected
that the WHERE clause of each query can be converted into an implicit indexed join. A year ago these queries were being
executed as expensive cross-joins. Unfortunately, indexed-joins are necessary but not sufficient for optimal query plans.
In both query plans, a Filter node sits above the second IndexedTableAccess rather than inside of it. Ideally these
filters would be converted into index range lookups. Instead, the entire index is being scanned, accessing much more
data than is necessary and dramatically increases the latency of these joins. Improved query planning is a major focus
of Dolt development and we expect to see improvements on these queries. Stay tuned!
Looking Forward#
Performance will always be a major focus for Dolt. Because we’ve modeled our interface after it, MySQL will always be our yardstick when evaluating Dolt’s performance. We’ve got a long way to go, but we’re quickly making progress. As we improve, we’ll continue to add new workloads to our benchmarking suite. TPC-C provides unique challenges for us and gives us a standardized way to compare Dolt to other databases. Scaling our transactional throughput will be a major development push for us in the near future. If you’re interested in learning more about Dolt or want to discuss your use-case, we’d love to chat. Join us on our Discord!