
Dolt is a MySQL-compatible version-controlled database. It’s the only SQL database with branches that you can diff,
merge and sync. Performance has been a major focus of Dolt development over the past year, and we’ve made substantial
progress on that front. When we first measured Dolt head-to-head with MySQL,
our average query was 12 times greater than MySQL’s. Our most recent metric on this benchmark
(Dolt release v0.40.20) is down to 4.7x! Our long-term goal for
performance is to reach parity with MySQL in any dimension we can measure. Since the 0.40.20 release, we’ve made some
updates to our benchmarks to better reflect real-world Dolt performance in our public metrics. Today’s post is about the
tricky business of benchmarking databases.
Sysbench Standard#
Dolt originated as a data-sharing tool, “Git for Data”. In the beginning, SQL was simply a convenient, standard API to access data through. As we grew and better understood our users, it became clear that what they really wanted was a version-controlled database. With this shift in focus came a shift in priorities: Dolt needed to be fast and dependable. We quickly decided on Sysbench as our default benchmarking utility.
Sysbench was created by members of the MySQL development team as a way to test basic transactional database queries.
The standard set of Sysbench benchmarks includes operations such as points selects, point mutations, and simple transactional
workflows. Here’s our progress on Sysbench’s oltp_point_select benchmark:
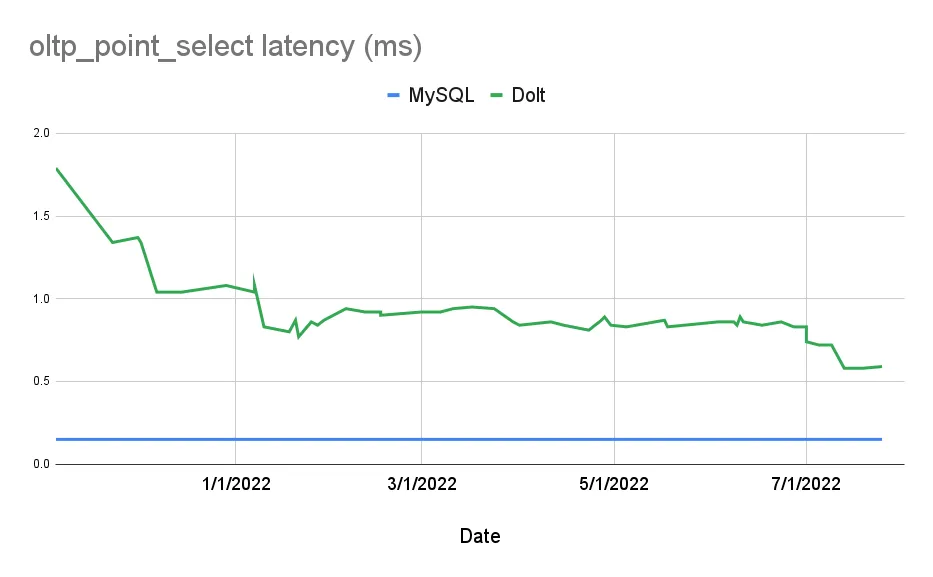
Our Sysbench metrics don’t capture every facet of database performance: the benchmarks are single threaded and the test database is small enough to fit in memory. In this way, Sysbench is closer to a microbenchmark when compared to other standard database benchmarks, but this simplicity is ideal for Dolt as we optimize its core access patterns.
Measuring all the Things#
Initially our Sysbench benchmarks only included the standard suite published with the tool. Notably absent from that set was any benchmark that performed a “scan” operation: queries that iterate over large ranges of an index. This makes sense in an OLTP context where SQL query engines go to great lengths to minimize the amount of data that a query must access. However, our early investigations into performance revealed especially slow performance for Dolt table scans. We made the decision in early 2021 to expand our benchmark set to include three new scan-based benchmarks:
table_scaniterates over every row in the primary key index of a table.index_scaniterates over a secondary index and does an indirect lookup into the primary index.covering_index_scaniterates over a secondary index and returns rows directly (does not perform an indirect lookup).
Including these benchmarks better represents how Dolt will perform relative to MySQL. Table and index scans may not be common access patterns in traditional OLTP use cases, but they are relatively common workflows for Dolt users.
Our benchmarks remained largely unchanged over 2021 until this addition of two new benchmarks this year:
groupby_scantests aggregation performance in Dolt withCOUNT(),MAX(), andAVERAGE()functions.index_join_scantests an indexed join on a primary key index.
The rationale for these additions was again to better characterize Dolt’s performance in real-world use cases. Development on Dolt continued to improve its performance. We needed to both characterize that improvement and ensure that improvements to one benchmark wouldn’t cause regressions in another.
Durability in Data Stores#
The next set of changes to our benchmarks came on the write-path. We’ve long believed that Dolt would perform relatively better on the read path compared to other databases. The core of Dolt’s storage engine is a copy-on-write index structure called a Prolly-Tree. Prolly Trees are the foundation of Dolt’s version-control features, but they are also more expensive to construct than traditional indexes.
As Dolt’s performance continued to improve over the last year, we saw an unexpected trend where writes were becoming
cheaper faster than reads. Our investigation into these results lead us to the conclusion that our benchmarks of write
queries weren’t a true comparison against MySQL. For MySQL, and databases in general, the most expensive operation for
write queries is persisting new data to durable storage. In order to ensure full durability, MySQL must make an
fsync() call on index files to guarantee that data has been durably written.
In the absence of an fsync(), the operating system will hold the data in a kernel-space memory buffer and flush the
data at a later time. Database writes held by the operating system are safe from application crashes, but flushing data
to disk is necessary for full ACID compliance.
Dolt’s persistence layer does not currently support flushing writes. This means our write-path benchmarks were not
making a fair comparison against MySQL. To correct this error, we reconfigured MySQL to stop flushing writes to disk on
every transaction (innodb_flush_log_at_trx_commit = 2).
Naturally, MySQL got faster on writes, and comparatively we’re twice as slow.
We plan on supporting ACID transactions in the future, but for now we can at least compare apples-to-apples.
Back to Basic (Types)#
The latest change to our benchmarks is a revision of the original additions we made to Sysbench. The three scan benchmarks,
table_scan, index_scan, and covering_index_scan, were created using a custom table schema:
CREATE TABLE sbtest1 (
id INT NOT NULL,
tiny_int_col TINYINT NOT NULL,
unsigned_tiny_int_col TINYINT UNSIGNED NOT NULL,
small_int_col SMALLINT NOT NULL,
unsigned_small_int_col SMALLINT UNSIGNED NOT NULL,
medium_int_col MEDIUMINT NOT NULL,
unsigned_medium_int_col MEDIUMINT UNSIGNED NOT NULL,
int_col INT NOT NULL,
unsigned_int_col INT UNSIGNED NOT NULL,
big_int_col BIGINT NOT NULL,
unsigned_big_int_col BIGINT UNSIGNED NOT NULL,
decimal_col DECIMAL NOT NULL,
float_col FLOAT NOT NULL,
double_col DOUBLE NOT NULL,
bit_col BIT NOT NULL,
char_col CHAR NOT NULL,
var_char_col VARCHAR(64) NOT NULL,
tiny_text_col TINYTEXT NOT NULL,
text_col TEXT NOT NULL,
medium_text_col MEDIUMTEXT NOT NULL,
long_text_col LONGTEXT NOT NULL,
enum_col ENUM('val0', 'val1', 'val2') NOT NULL,
set_col SET('val0', 'val1', 'val2') NOT NULL,
date_col DATE NOT NULL,
time_col TIME NOT NULL,
datetime_col DATETIME NOT NULL,
timestamp_col TIMESTAMP NOT NULL,
year_col YEAR NOT NULL,
PRIMARY KEY(id),
INDEX (big_int_col)
);The 28 columns in the table included every storage type that Dolt supported at the time. An early bottleneck we found when working on Dolt performance was deserialization in the storage layer. In order to better measure this bottleneck, we needed a benchmark that included every serialized type.
Our most recent benchmarking change is to remove TEXT types from this benchmark. In both MySQL and Dolt, TEXT types
are stored out-of-band and referenced by a pointer from the primary key index. Scanning tables that include TEXT means that
fetching each row necessitates an additional disk lookup to fetch the TEXT data. While its important to optimize this
operation, it doesn’t fit the mold of the core access patterns we’re interested in measuring. These benchmarking changes
took effect in the most recent release 0.40.21. In these more realistic metrics, Dolt is
comparatively slower that MySQL
for scan operations, and index_scan in particular.
Looking Forward#
Benchmarking is a central part of the performance work we do to improve Dolt. As Dolt has gotten faster, we have gained
a better understanding of what metrics we care about and how to measure them more accurately. Our benchmarks have grown
over time to better characterize real-world use cases for Dolt. To some extent, these changes have complicated the story
over Dolt’s performance gains. However, it’s clear from core Sysbench metrics like oltp_point_select that we’ve made
dramatic progress since we started.
Benchmarking databases is notoriously complicated. Industry-wide standards like TPC-C have
attempted to level the playing field and make it easier to make direct comparisons between databases. We plan to publish
TPC-C results in the near future to complement our suite of Sysbench tests. Additionally, we been developing a
new storage engine for Dolt that will come with some major
performance improvements. Stay tuned for its beta release later this month! If you’re interested in learning more about
benchmarking databases, or if you want to know more about Dolt, join us on Discord!