
Dolt is a SQL database that you can clone, fork, branch, merge, push and pull like a git repository. Its storage engine is built from the ground up to make these operations possible, but over the wire it speaks MySQL, and should be a drop-in replacement for any application that uses MySQL. When we benchmark Dolt, we typically compare its performance to MySQL’s for this reason.
For the simple benchmarks we’ve run so far, we are about 8x slower than MySQL, summarized by the table below.
| Read Tests | Dolt | MySQL | Multiple |
|---|---|---|---|
| covering_index_scan | 10.46 | 1.37 | 8.0 |
| index_scan | 144.97 | 35.59 | 4.0 |
| oltp_point_select | 1.86 | 0.15 | 12.0 |
| oltp_read_only | 33.72 | 2.76 | 12.0 |
| select_random_points | 2.97 | 0.29 | 10.0 |
| select_random_ranges | 3.82 | 0.31 | 12.0 |
| table_scan | 155.8 | 35.59 | 4.0 |
| mean | 8.86 |
| Write Tests | Dolt | MySQL | Multiple |
|---|---|---|---|
| bulk_insert | 0.001 | 0.001 | 1.0 |
| oltp_delete | 3.13 | 0.14 | 22.0 |
| oltp_insert | 8.9 | 2.97 | 3.0 |
| oltp_read_write | 59.99 | 6.79 | 9.0 |
| oltp_update_index | 10.27 | 3.13 | 3.0 |
| oltp_update_non_index | 7.56 | 3.07 | 2.0 |
| oltp_write_only | 29.72 | 4.33 | 7.0 |
| mean | 7.0 |
| Overall Mean Multiple | 7.79 |
|---|
We’re not satisfied with this result, and are committed to being no more than 2x slower than MySQL in the next year. We have multiple work streams underway that we think will get us there, most significantly by rewriting the storage format itself.
But all of these benchmarks have a problem: they’re too simple. Database benchmarking is a notoriously tricky business, and while the benchmarks above do a good job comparing raw throughput for simple read and write operations, these workloads don’t resemble many that are found in real applications.
Luckily, there is an industry standard for that.
TPC-C#
TPC is a bundle of database benchmarks meant to simulate real world applications and measure what real applications care about. There have been many revisions to the benchmark over the years, and the current gold standard is called TPC-C. It attempts to simulate an ordering system with many concurrent users:
TPC-C simulates a complete computing environment where a population of users executes transactions against a database. The benchmark is centered around the principal activities (transactions) of an order-entry environment. These transactions include entering and delivering orders, recording payments, checking the status of orders, and monitoring the level of stock at the warehouses.
TPC-C involves a mix of five concurrent transactions of different types and complexity either executed on-line or queued for deferred execution. It does so by exercising a breadth of system components associated with such environments, which are characterized by:
- The simultaneous execution of multiple transaction types that span a breadth of complexity
- On-line and deferred transaction execution modes
- Multiple on-line terminal sessions
- Moderate system and application execution time
- Significant disk input/output
- Transaction integrity (ACID properties)
- Non-uniform distribution of data access through primary and secondary keys
- Databases consisting of many tables with a wide variety of sizes, attributes, and relationships
- Contention on data access and update
Since we recently released transaction support in Dolt, we decided that TPC-C, with its focus on concurrent throughput, would be the standard we would compare ourselves against to compare Dolt’s real-world performance against MySQL’s, and got to work setting up a test bench.
Concessions for Dolt#
Because TPC is licensed, we settled on a “TPCC-like” benchmark published by Percona Labs which uses the popular sysbench framework to collect its results. But we quickly ran into issues when applying it to Dolt:
- Massive Scale. By default, TPC-C generates dozens of tables with millions of rows. Just the preparation phase took overnight to run, and gave us a database of hundreds of GB.
- Unsupported features. The benchmark uses features that Dolt
doesn’t support yet, most notably row-level locking with
SELECT FOR UPDATE - Slow queries. Dolt’s analyzer isn’t yet smart enough to properly apply indexes for every query exactly as written, which meant the benchmark was spending its entire execution time running one badly optimized join query, reducing measured throughput to zero.
So I set out to fix each of these problems by forking the original benchmark and tweaking it in various ways.
For scale, I needed additional knobs to control how many tables and data got generated. The benchmark has a datamodel that looks something like this:
- 100 warehouses
- 10 districts per warehouse
- 3,000 customers per district
- 100,000 items
- 3,000 orders
- 100,000 stock entries
- N copies of all of the above tables to simulate sharding
The benchmark only allowed tuning 2 of these parameters, but I needed much finer-grained control to understand how the performance scaled with database size. So I added additional tuning parameters for the missing scale factors.
These changes let me get the benchmark down to a small enough size that I was able to quickly iterate on it. When I did so under many threads, I quickly noticed that many runs were failing because of duplicate key violations, because the benchmark uses row-level locking, which Dolt doesn’t yet support. So I had to fix that:
d_next_o_id, d_tax = con:query_row(([[SELECT d_next_o_id, d_tax
FROM district%d
WHERE d_w_id = %d
AND d_id = %d FOR UPDATE]]):
format(table_num, w_id, d_id))
-- Dolt doesn't support `for update` yet, so we need to fuzz this identifier, sorry
d_next_o_id = d_next_o_id + sysbench.rand.uniform(1,10000)Finally, several of the joins were much too slow to give useful results, because Dolt doesn’t yet understand how to turn an implicit join into an indexed join. So queries like this:
SELECT c_discount, c_last, c_credit, w_tax
INTO :c_discount, :c_last, :c_credit, :w_tax
FROM customer, warehouse
WHERE w_id = :w_id
AND c_w_id = w_id
AND c_d_id = :d_id
AND c_id = :c_id;Had to be manually translated into explicit joins, like this:
SELECT c_discount, c_last, c_credit, w_tax
FROM customer join warehouse on c_w_id = w_id
WHERE w_id = :w_id
AND c_d_id = :d_id
AND c_id = :c_idInitial benchmark results#
After getting all of these problems out of the way, I was finally able to run a scaled-down version of the benchmark on both Dolt and MySQL for an apples-to-apples comparison. Unfortunately, the results on this real-world-like benchmark are not nearly as good as on the simpler ones.
mysql:
queries performed:
read: 71431
write: 74303
other: 11424
total: 157158
transactions: 5637 (562.53 per sec.)
queries: 157158 (15683.23 per sec.)
dolt:
queries performed:
read: 1239
write: 1278
other: 174
total: 2691
transactions: 87 (7.84 per sec.)
queries: 2691 (242.54 per sec.)| Metric | Dolt | MySQL | Multiple |
|---|---|---|---|
| read queries | 1239 | 71431 | 57 |
| write queries | 1278 | 74303 | 58 |
| queries / second | 15683.23 | 242.54 | 64 |
| transactions / second | 7.84 | 562.53 | 71 |
This is much worse relative performance than our simple benchmarks had demonstrated. It’s also much worse, relative to MySQL, than the incredibly complex queries run by our most demanding customer, researchers sequencing cancer genomes. We promised them no worse than a factor of 20x slower than MySQL, and have so far been able to meet it for every one of their queries.
Getting better#
Improving our performance on this benchmark will be a major part of our work for the next year and beyond, with the ultimate goal of being no worse than 2x slower than MySQL. There are several areas that we know we need to improve to get there.
Join index analysis#
Several of the joins used in this benchmark don’t get indexes properly applied in our analyzer yet, for dumb reasons such as an extra predicate that doesn’t match an index exactly. Join index analysis is one of our most intensive areas of focus for improvement, since it can make such a huge difference in performance.
Storage efficiency#
Dolt is built on top of Noms, and while that decision got us to market a lot faster, we’ve reached the stage of product maturity where we’re starting to see issues. Our runtime profiling indicates that we spend a great deal of time in our storage layer just parsing the values out of their on-disk byte representation and into in-memory values. This is due in large part to the way noms stores its data, especially type info. Noms is a much more general-purpose store than we need to implement Dolt, and many of the technical decisions required to be general purpose end up slowing down performance for the row storage we built on top of it. So we’re in the middle of a project to rewrite the row storage format to remove the features we don’t need for Dolt, and make it as performant for our row storage as we know how.
Bad chunking#
When first running this benchmark on Dolt, I measured how transaction throughput varied with the size of the tables on disk, and was surprised to discover a direct linear relationship: the larger the table, the worse the throughput.
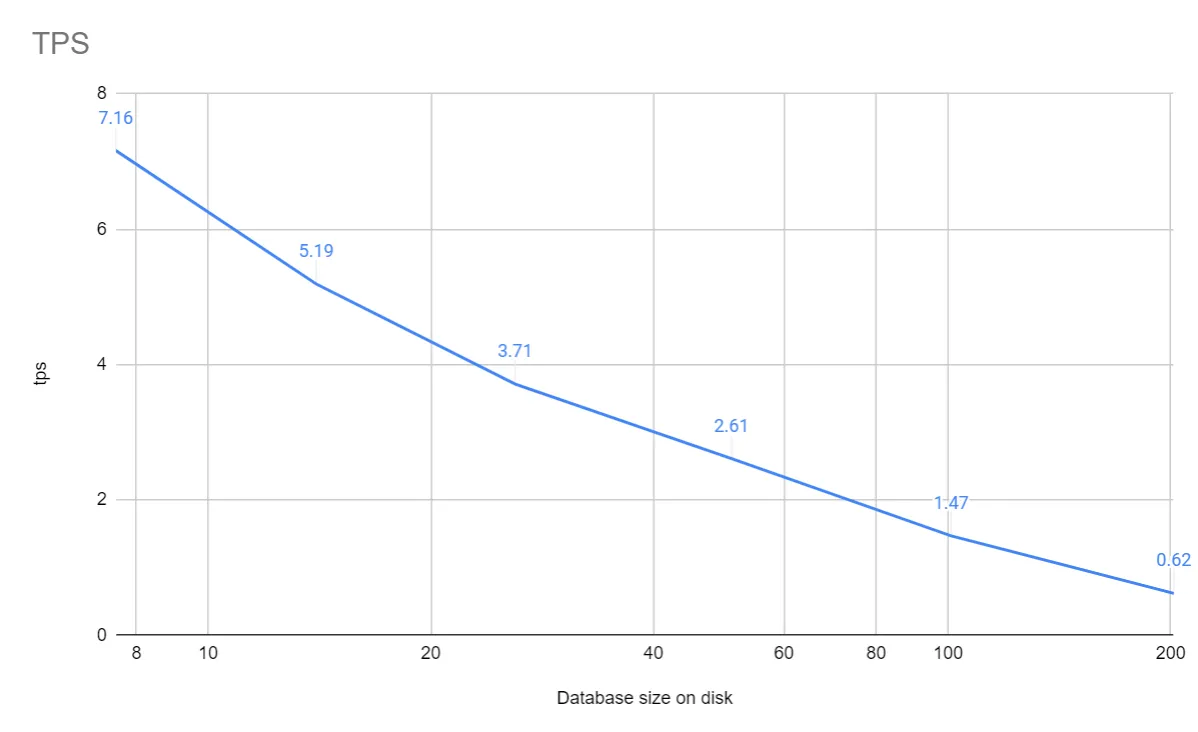
This was surprising because the data is stored in a form of B-tree, which should give logarithmic performance as the table grows. So where did the linear factor come from?
This question derailed most of our senior engineering staff for a few days debating and experimenting with multiple theories. In the end, the culprit was in a relatively obscure part of the codebase, the chunker. The chunk is the unit of data that Dolt writes to disk, and various heuristics are supposed to keep the chunk size to under 4k. But for this benchmark, a combination of the synthetic nature of the data and bugs in the implementation of a fast compression estimation algorithm led to a very large chunk, one that contained nearly all of the data in one commonly used index. So for every update or insert into a particular table, instead of writing log(N) 4K chunk files, we had to write one massive file (several MB in the best case).
We’ve got this bug partially fixed with improvements to the chunker algorithm to limit the size of a chunk more effectively, but the compression estimation bug (which can be tricked into telling us that the bytes we’re going to write to disk will take far less space than they actually do) is harder to fix, and is triggered by this benchmark. Fixing the chunking bug means a breaking change, so we have to do so very deliberately with a plan for migrating customers.
Conclusion#
This work is the latest effort in our ongoing mission to measure and improve performance against MySQL, and the closest we have yet to a real-world benchmark (other than what our customers tell us). Getting better on it will be a lot of work, and we’re just getting started.
Like the article? Have questions about Dolt? Come join us on Discord to say hi to our engineering team and discuss your use case.