
Dolt is a version controlled SQL
database — a
database where users and their applications can branch, merge, push, pull and
clone the value of their database. It works on a similar model to git, where
commits referring to a snapshot of a value for the database are created on
branches and each commit can have one or more parent commits.
Storing all historical revisions of the database allows for some really neat
workflows, including analogs for things like git blame. You can answer the
question “When did this cell in this table get this value and what else changed
in the same commit.”
Because databases are somewhat different from source code repositories in how they get updated, we recently released some changes to how Dolt stores commit parents. These changes allow Dolt to more efficiently calculate common ancestors when performing a merge and to more efficiently push and pull missing chunks when performing operations against a remote with a deep divergent history. This blog post examines some of the differences in the use case we see and what we’ve implemented so far to improve things.
Source Control vs. Databases#
As we started to focus more and more on the OLTP use case for Dolt, we quickly
noticed that Dolt commit graphs could reasonably become very deep and, in a lot
of cases, would be largely linear. In contrast to an SCM, where changes are
often made by humans and even automated systems operate at relatively low
throughput, a database can realize many orders of magnitude more changes in the
same period of time. For example, a database processing less than 12
transactions per second will create 1 million commits a day; and 12 TPS is
low throughput for a database in an OLTP context. In contrast, the
linux repository has about 1,000,000
commits after 20 years of development, and Google’s google3 repository was
reported in
2016
to have ~35 million commits.1
When we were running the menus bounty, we were firmly in the data collaboration use case, not an OLTP use case, but we still had commit histories of 100,000 commits after just a few weeks. We also had tens of thousands of pull requests open at a time, whose merge status needed to be updated every time the destination branch received a push.
These observations, combined with our operational experiences during the
menus bounty got us
thinking about how to improve the performance of certain types of commit graph
walks. In particular, we want to have credible performance for fetch/push/pull
on very deep histories and for calculating merge status and merge roots for
very deep histories. We recently released some changes to how Dolt stores
commits that improve the performance of both of these things.
A Model For Commits#
A Dolt commit is conceptually very simple. We can store a content-addressed serialized struct in the database that looks like:
type Hash [20]byte
type DatabaseValue ...
type CommitMeta struct {
Author string
Committer string
Date time.Time
Message string
}
type Commit struct {
Parents []Hash
Meta CommitMeta
Value DatabaseValue
}Each commit has the addresses of its parent commits in its commit struct. As
explained in my blog post about how Dolt performs
merges, in order to merge two commits together
dolt performs a depth-first walk of the Parents field of the commits to find
the nearest common ancestor. In the case of a very deep history, this can
require a very large number of serial round trips to storage to get each Commit
struct before the walk knows what it is going to need next.
In the same way, as explained in my blog post about push/pull, a big performance win for push and pull can be batching the chunks we know we need to fetch. But in the menus bounty use case, for example, once the remote had diverged by 50,000 commits from a local clone of it, fetching could take a very long time not only because there was a lot of new data to fetch, but also because the algorithm made lots of serial round trips to the remote without being able to fan out and batch very much.2
With this in mind, we implemented a change to the commit struct to materialize an ancestor closure at the time we write the commit.
Materializing Ancestor Closures#
Finding a common ancestor between two commits and fetching or pushing to a remote both do a breadth-first walk of commit DAG. We observed that we have a database with cheap point edits, and especially cheap appends, on content-addressed Map data structures. Not only that, but this Map data structure underlies all table and index data we store in Dolt, and we have every intention of making those kinds of edits cheaper, in terms of CPU, memory, and storage overhead, in the future.
We can leverage this data structure to materialize the commit closure of a commit’s ancestors at commit time. Concretely, we can write a prolly tree value when we write a commit, and the value of the prolly tree can be a map where there is a key for every ancestor of the current commit. The value for the entries can be the corresponding keys for that commit’s parents. It looks like this:
type Ancestor struct {
Height int
CommitHash Hash
}
type Commit struct {
Parents []Hash
Ancestors Map[Ancestor,List[Ancestor]]
Meta CommitMeta
Value DatabaseValue
}with each commit. Every ancestor of the commit is a key in the map, and the keys
are ordered by their commit “height”. A commit with 0 parents has a height of
0, a commit with 1 or more parents has a height of max(height(parents)) + 1.
Now a breadth first traversal of a commit’s ancestors can proceed as a simple
reverse linear scan of the keys of the Ancestors map. Finding a common
ancestor for two commits is just a linear scan back from each of their
Ancestors maps until we hit a commit that they have in common. And putting
all the commits reachable from a commit in a compact format quickly reachable
from the commit itself lets our naive push/pull algorithm fan out and find the
missing chunks between a remote and a local clone much faster.
Software engineering is all about tradeoffs and this is a classic space/time tradeoff being made. Concretely, to materialize this map requires a few things in Dolt:
-
For a non-merge commit, we take the value of the map in our parent commit and we append our parent itself to that map. This is an
O(lg_b n)operation, wherebis the average fanout for this map in the prolly tree andnis the size of our commit closure. Our current storage engine has a fanout of ~110 for the Ancestors map entries, which gives us a tree height of 3 on a one million element commit closure and a tree height of 5 on a ten billion element commit closure. -
For a merge commit, we have to merge the commit closures of all of the parents in order to form their intersection. Similar to SCM systems, we expect that most of the commit closures which are being merged will share a large common prefix. Their unique histories will be represented in the later portions of their ancestor closure. When that is the case, we can use the structural sharing present in the two prolly tree values to efficiently diff them and compute the resulting union that way.
In both cases, we estimate that the amount of work we need to do to maintain this closure, in both CPU time and disk storage overhead, it likely to be small relative to the amount of work necessary to carry out the user’s actual operation. For example, in the case that the commit represents a SQL transaction that updated a single row’s value, we had to update the table data prolly tree with that row update. In many cases, even single row updates result in multiple updates to prolly trees in the database value, because they touch things like indexed columns. And many SQL commits update more than one row, of course.
In the same way, if two branches have widely divergent commit histories and are now being merged, it’s reasonable to expect that there will be work to do proportional to the size of their commit histories, and that the performance of the merge will not be heavily impacted by merging the Ancestors maps as well.
There are definitely degenerate cases where neither of these assumptions are
true. A very long history of empty commits which do not change the database
value will dominate CPU on commit creation and disk storage on just storing
these materialized Ancestors. Two long divergent branches where each branch
works on an independent set of tables (with no foreign-key references between
them) will merge trivially for the database value, but will still have to
materialize a correct Ancestors map. But for now, we are happy with the
tradeoff because we see increased performance for the use cases we actually
have.
But Is It Faster?#
The whole point of materializing commit ancestors is to make push/pull and find common ancestor faster. So it’s worth measuring it and seeing if it was worth it.
For the push/pull use case, we tested fetch on the menus
repository. The menus
repository is a repository that’s about 60GB in size and has 109,203 commits.
About half the commits in the repository are merge commits.
We cloned the repository and rewrote our clone to include the commit ancestors map in the commits. After pushing our clone to a remote, we truncated our local clones of both repositories to about half-way through the commit history and garbage collected the local repositories. The resulting sizes were ~30GB and we had 57,436 commits left in our local clones. That means we needed to fetch 51,767 commits from the remote server and about 30GB of data. The fetch went from taking 47 minutes 23 seconds to taking 14 minute 21 seconds.
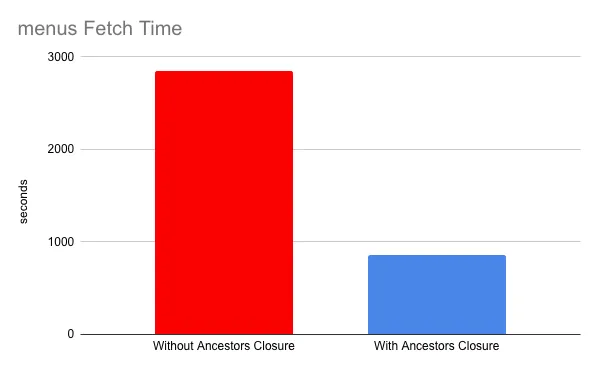
This was from an EC2 instance in north america accessing an S3 bucket in a
separate region in north america; the RTT was about 45ms. With a small RTT the
difference might have been smaller, but with a larger RTT (for example, a
user in europe running this fetch) the difference would have been even
larger.
For the find common ancestor use case, we constructed a completely synthetic benchmark. We made a repository that had two branches, each with 99,000 unique linear commits, and a common ancestor as the parent of the start of their linear chains. Then we simply ran dolt’s find common ancestor algorithm against the two branch heads and collected statistics about how long it took. This got over 5 times faster.
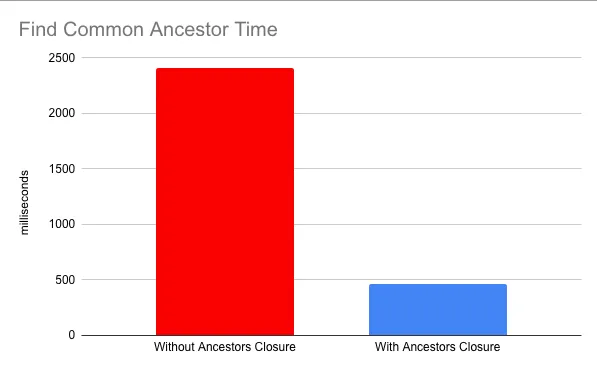
These tests were run with fast local storage but having the materialized commit closure still made things a lot faster.
Conclusion#
This is a near at hand change that materially improved performance for the use cases we were targeting. We’re decently happy with it, but we also know this can’t be the end of our explorations and innovations in this area. Write amplification and storage amplification on point edits in prolly trees, including appends in the Ancestors prolly tree, is something we’re actively working on in Dolt, because the overhead associated with these common types of changes is simply too high right now. We’re excited about what the future holds for Dolt on the OLTP front and to continue to expand its feature set and performance profile to support more and more use cases.
Footnotes#
-
We can be confident that the throughput against
google3is quite a bit higher now than in 2016, but the point still stands. An estimate from open source commit messages might put it at ~400 million commits and maybe between 3 and 5 TPS, which is quite impressive. ↩ -
It is perhaps worth noting that Dolt’s current approach to remotes is somewhat different from Git’s. Dolt remotes are purely storage interfaces and the client is responsible for computing the deltas of what is missing and fetching the data with RPCs. ↩