
Dolt is a MySQL-compatible database with branch, merge and diff. DoltHub is a place on the internet to host, share and query Dolt databases.
If you’re just hearing about the menus bounty, here is menus launch blog. If you’re new to data bounties, I’ll point you to Tim’s Introducing Data Bounties blog.
This blog is an update on our menus bounty that launched on July 7th. We launched this bounty with a rule that each submission contain only one restaurant. Within a day of launch, we had over 800 pull requests (thus, over 800 restaurants submitted). At the time this blog is posted, three weeks after launch, we have over 40,000 pull requests. DoltHub was not prepared.
Background
Before I get into how we broke DoltHub, I’ll first explain why we chose the acceptance criteria that we did. In previous bounties, we had been overwhelmed by the number of rows changed, added or deleted in PR submissions. This is partially the fault of our internal bounty review tools, which are still in their infancy. In the past, we’ve relied on the web diff to review submissions. When the submissions are huge, we tend to review a subset of the rows, after which we provide feedback or approve and merge the submission. On these large submissions, feedback is often necessary.
When it came to the menus bounty, it seemed logical to restrict submissions to one restaurant. The motivation here was to:
1) Improve the review process#
PR diffs on the web are more human readable when a couple dozen, or few hundred rows, are added. This helps the reviewer on the DoltHub team to visualize diffs quickly without having to clone user databases or inspect rows with custom queries.
2) Motivate cleaner submissions#
To receive cleaner submissions, we hoped that limiting participants would inspire better web scrapers and import logic that handle restaurants individually. In the past we have received huge submissions that contained a lot of errors, whether it be from web scraper logic, tangled Dolt commit graphs or inaccurate, suboptimal sources.
How the menus bounty broke DoltHub#
Limiting submissions may have been a good thing in regards to our latter hope, that we would receive better pull requests. I have had minimal feedback for users only regarding some invalid characters that were scraped. Otherwise submissions have been spot on. That did not, however, limit the incoming quantity of pull requests. A few of the contributors figured out how to hit our GraphQL end point to create pull requests by inspecting the web developer console. Note that our GraphQL layer is not a publicly maintained or documented service. But props to our contributors for doing some reverse engineering. We’ve now found ourselves in the middle of a massive DoltHub stress test.
Problem #1: Pull list page broken#
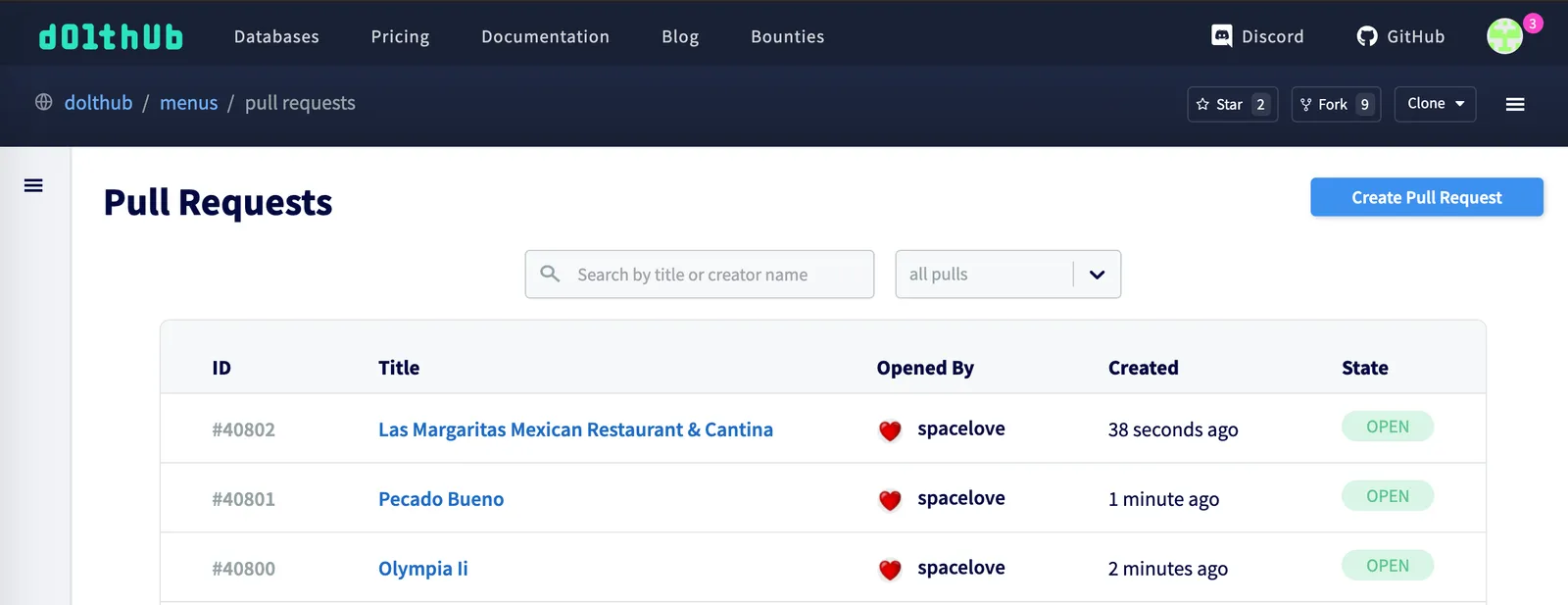
Our pull request lists have infinite scroll on the front end, which previously attempted to render every paginated list on page load. This was causing long timeouts and also rendered the page useless without a search or filter, which we also lacked.
Solution: Remove auto fetching of pull request lists. Add search and filter.#
Instead of on page load, we now fetch paginated pull request lists when the user initiates infinite scroll. This brought the number of GraphQL requests down from many thousand, to twenty at a time.
Once the page was loading, a few features were added to narrow down the list. There is now a search bar at the top of the pull requests page where you can search by title or author. Next to search you’ll find a drop down to filter pull requests by open, closed or merged state.
Problem #2: Pull request states not updating#
Pull request states were not properly updating as we merged pull requests into master from the Dolt command line. Before this bounty, we closed pull requests on a best effort basis, only occasionally timing out. But when hundreds of PR’s were merged into master and pushed, the timeouts became a problem. Most contributors checked out every branch from the same point on master, early in the bounty when we had only two commits. They then commit once to that branch, push it up, and create a pull request. As the master commit graph grew, the graph walk necessary to compute merge state was increasingly long.
Solution: Update pull requests in reverse order#
To know if a pull request has been merged on dolt push, we walk the commit graph looking for a common ancestor between the PR head commit and the tip of master. If we find the common ancestor, we know that pull request’s commits have been found in master, thus we can close it as Merged. When master is thousands of commits ahead of a PR branch, it takes time to find to find the common ancestor (if it exists). This approach was updating pull states after many hours, or not all, and the time between each update increased with every commit to master.
To more efficiently perform updates, we now process pull request states in reverse order. We also added caching to the commit graph walk for walking commits for pull requests. Pull request states are updating within about ten minutes.
Problem #3: Bounty scoreboard calculation timing out#
The bounty scoreboard calculation also took a hit. The build tasks were caught in an endless queue of waiting for tasks ahead to complete, and further increasing timeouts when the previous task hadn’t yet completed.
Solution: Optimize the scoreboard build tasks queue#
The scoreboard build tasks now process independently for each merge commit. Each task checks what work is left to be done and completes it, rather than waiting for builds ahead of it. With this change, the scoreboard is updating again, usually within a minute.
Next steps#
We are currently working to improve dolt fetch by downloading chunk files in batches, amongst other optimizations that will roll out soon. Also on the road map is improving data review tools and adding pull request diff support to the CLI. We like bounties because they provide free databases to the public. But we’ve also learned that bounties help us find Dolt and DoltHub’s rough edges, then fix them.
It’s been an exciting couple of weeks of full stack development to make the menus bounty viable. If you broke DoltHub with us, thank you! DoltHub is better for it. If you have any questions or ideas, you can find us on Discord.