Data Merge is Different

Dolt is the first SQL database that branches, diffs, and merges data the way Git version controls text. We expected versioning data to be different than versioning code. But as the first database with structural sharing at the storage layer, Dolt is in a unique position to discover how deep the rabbit hole goes.
It has been 3 years + 4 days since Aaron wrote our first merge blog. In the meantime, our customers have been putting data merge through its paces. This blog is an update of how we have evolved Git's three-way merge for data. We talk specifically about (1) schema changes, (2) referential integrity, and (3) workload imbalances that affect performance.
This blog is mainly a design overview. Future articles will detail performance deep dives for some of the extreme workloads I mention here.
Background
Merging is a way to reconcile historical changes between two divergent historical branches. This is true for tradition version control systems (VCS) like Git and for databases using Dolt.
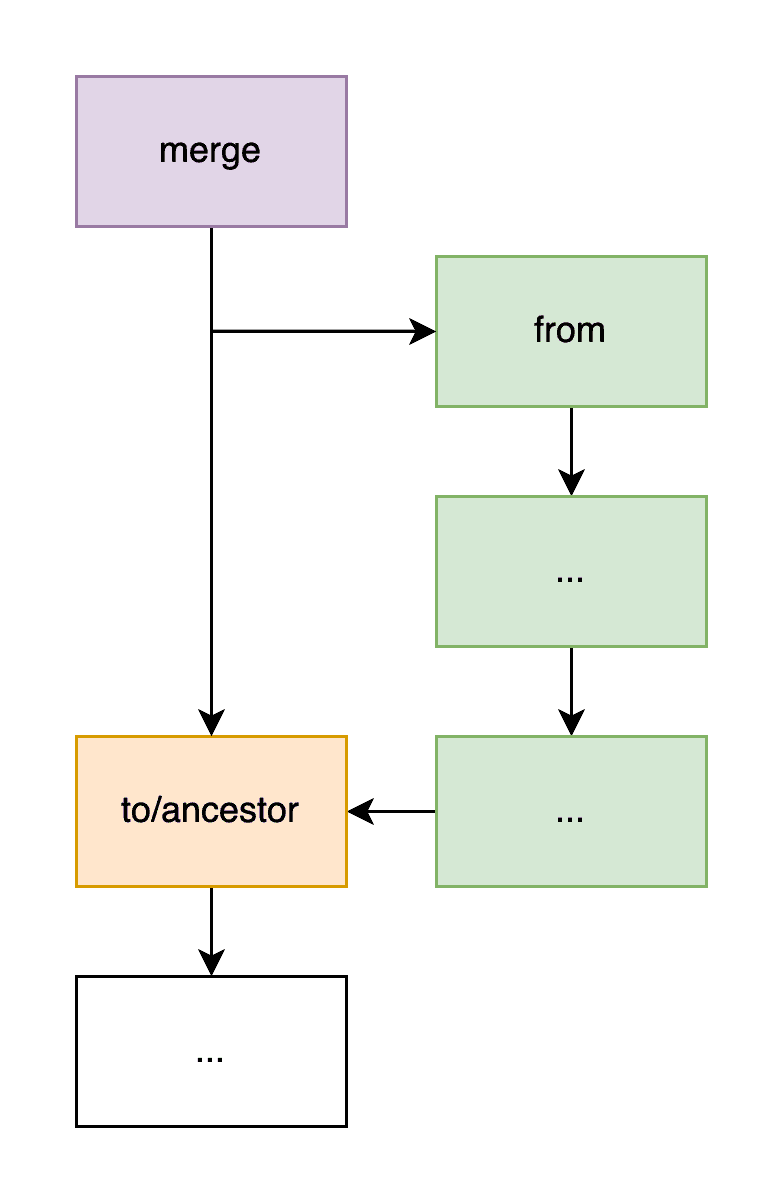
First, a bit of background terminology. We will use the to commit to
refer to the HEAD of the branch that will be extended by a merge commit.
The to branch is the active branch and implicit. The from commit is
usually the HEAD of a branch that contains the remote changes we will
apply on top of to. The from commit is the main argument to call
dolt_diff('from'). Lastly, the ancestor commit is the most recent
common commit shared by to and from (refer
here
for how ancestor discovery has changed over time).
The simplest merge is a "fast-forward" that avoids performing any work.
Here the ancestor and to branches are the same. The merge result
has the same state as the from branch (technically this is a "no-ff"
merge because we are creating a new commit, not just assuming from).
The more interesting "three-way diff" merge we have adopted from version control systems is summarized in the image below:
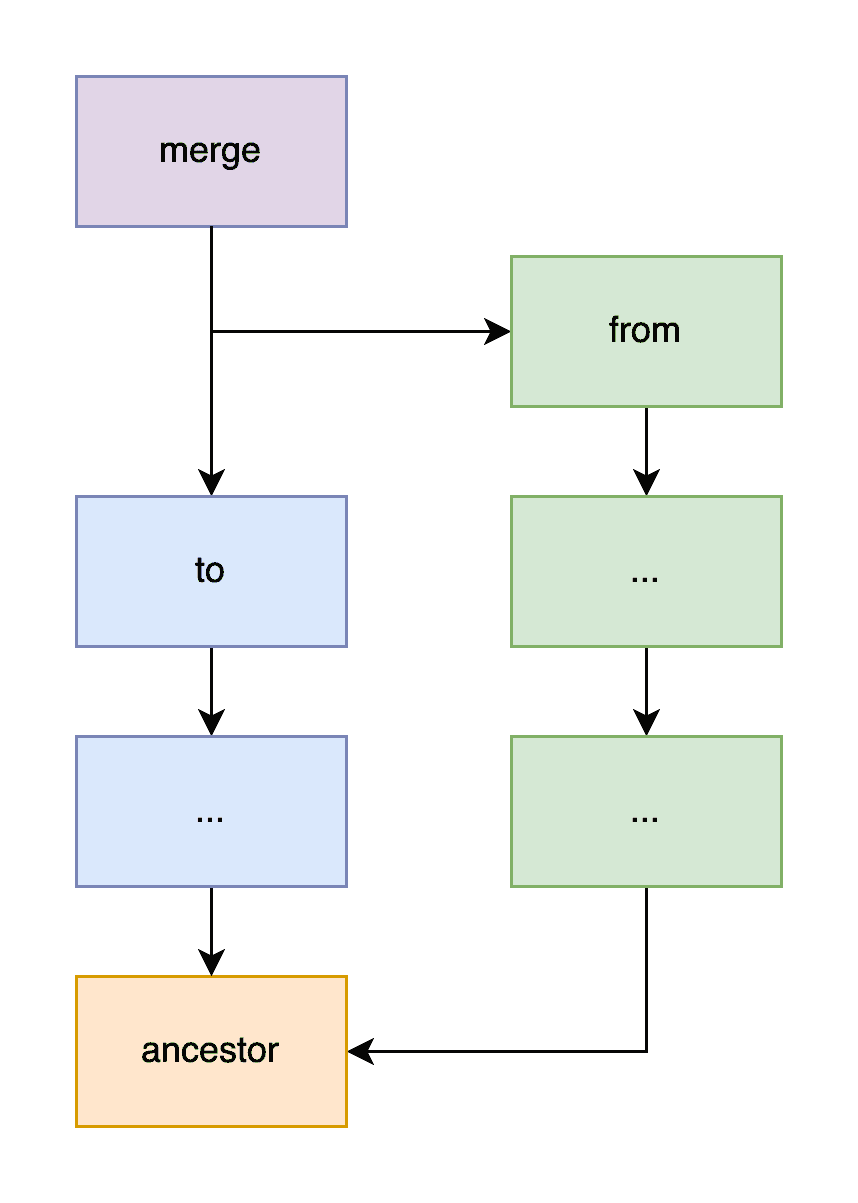
We want to apply the changes in diff(ancestor, from) to to,
deduplicated by common changes already present in diff(ancestor, to).
In other words, we are interested in the the changes between
ancestor and from that are not already present in to.
As a quick refresher, the complexity of generating diffs between two
commits is proportional to the size of the diff. This blog on
structural
sharing
explains how we side-step table size during diffs. This makes three-way
diff appealing, because a merge will only be as complex as
diff(ancestor, from) + diff(ancestor, to).
The Real World
Merge is subject to edge cases that traditional text source control is not. We will touch on schema merges, referential integrity, and some data workloads that three-way merge was not designed to support.
Data Merge Is Not Enough
Tables accumulate schema changes over time. Dolt in particular attracts users that make aggressive schema changes. Column adds, deletes, and modifications are common. It can be even more difficult when two branches create different indexes, check constraints, and foreign key references. In many cases, we need to enter a novel merge phase to resolve structural conflicts before continuing to data merge.
To give one example, consider an ancestor commit with a simple table:
create table pigeons (
name varchar(64),
origin varchar(64),
cost int
);
call dolt_add(pigeons);
call dolt_commit('-m', 'create pigeons table');On the first branch we will insert some data:
call dolt_checkout('-b', 'adds');
insert into pigeons values
('Tippler', 'UK', 30),
('Jacobin', 'India', 100),
('Gola', 'India', 1000);Lets say we want to change the cost column type
before doing a merge:
alter table pigeons modify cost float;
call dolt_add('pigeons');
call dolt_commit('add pigeons');Next, a teammate adds some pigeons to a second
branch. They accidentally chose a conflicting varchar type for cost:
call dolt_branch('checks', 'main');
call dolt_checkout('adds2');
alter table pigeons modify cost varchar(32);
insert into pigeons values
('Lucerne Gold Collar', 'Switzerland', 'unknown');
call dolt_add('pigeons');
call dolt_commit('add more pigeons');We can detect and auto-merge some types of schema changes (for example, adding a new value to an enum type), but conflicting type changes in both branches are not auto-mergeable.
We can detect and auto-merge some types of schema changes. But
conflicting type changes in both branches are not auto-mergeable. It is
not clear whether cost should be float or varchar.
This complicates merge by adding a new merge phase designed to catch correctness errors before attempting data merge. A human needs to decide the target outcome and manually resolve the schema incompatibility.
Consistency Is Key
Data modelling is the art of encoding real world systems as tables and data relationships. Relational models divide data between tables, and connect them back with foreign key constraints, check constraints, and uniqueness constraints that track the (consistency) properties of the real system. To top it off, we usually add secondary indexes that duplicate data and need to track changes in source rows. These SQL relationships are arbitrary graphs that are both undirectional and cyclic.
To give a simple example of how this makes data merge harder, we will focus on a check constraint example. Below we make another two branches. One will have data:
call dolt_branch('data', 'main');
call dolt_checkout('data');
insert into pigeons values
('Tippler', 'UK', 30),
('Jacobin', 'India', 100),
('Gola', 'India', 1000);
call dolt_add('pigeons');
call dolt_commit('-m', 'add pigeons table and data');And the other will add a check constraint:
call dolt_branch('checks', 'main');
call dolt_checkout('data');
alter table pigeons add check constraint (cost > 0 and cost < 500);
call dolt_commit('-am', 'add checks');Consider merging checks into data:
call dolt_checkout('data');
call dolt_merge('checks');The standard three-way diff of a text merge filters for novel values in
the from commit to apply to the to commit. Which is also what the
first several versions of Dolt's merge did.
But consider what happens in the case above if we only ever see
unique diff(ancestor, from) edits. We will fail to verify the check
constraint on all of the new data in diff(ancestor, to)! We need to
see changes in from to apply to to, and we need to see changes in
to to validate the new check constraint.
Foreign key and unique index also require specific sets of information for verifying consistency. In the general case, we need to do several passes over the data: one to create the merged database, and a second to verify constraints.
The latest version of merge generates a much more granular three-way diff of every change in both ancestor diffs. We took the opportunity to reorganize the merge pipeline into a series of consumers fed by the new three-way differ. Each consumer is responsible for one piece of logic, like updating a secondary index, verifying a check constraint, or accumulating merge statistics. All of this additional complexity is new to data merge, and designed to maximize validation thoroughness. And as a bonus, a three-way diff lets us calculate Pull Request diff count estimates on DoltHub without performing a full merge, which was not possible with the original merge machinery.
Imbalanced Workloads
Schema and constraint violations add overhead to data merge. We have adapted by making merge more complicated and thorough. The downside of a more granular merge is that compounding complexity creates downstream scaling bottlenecks. We will outline some of those problems here, leaving performance deep dives to later blogs.
Constraint Violation Blowup
We mentioned a few ways of creating constraint violations above. Every violation in a Dolt merge is recorded in a system table on disk to make it easier for users to review and resolve failed merges.
Unfortunately, the ease of automating data updates has made it easier to
create merges with 10's of millions of conflicts. Writing that many
conflicts to disk is expensive and can cause merge to hang. In the
short term, we have been using diff -stat to understand and fix
conflicts prior to merge. Resolving the data conflicts is usually fast
and then clears the way for merge. Our lesson from these edge
cases is that merge conflicts are most useful when summarized and
available for generating, but not materialized on disk. In the future, a
third merge stage in-between schema merge and data merge can help users
work through pre-resolving violation heavy merges.
Foreign Key Page Swapping
Merges with many foreign keys end up performing many index lookups. To give a quick overview of the problem, consider foreign key checking 10 rows in a 100-row table. If every 10 rows of the table constitute a page on disk, and our 10 foreign key lookups are evenly distributed, we will not read 10% of the table (one page once), we will read 100% of the table (each page once). In practice, pages often have more rows and an unordered foreign key check might read the lookup table 10-100 times. Each foreign key constraint stacks the runtime complexity.
The complexity of this page swapping was not something text merge prepared us for. Our short term response has been to prefer foreign key lookup indexes whose key orderings align with the arriving diff edits. As a result, we will only read each page in the lookup table once.
But the undirected nature of these constraint checking usually means that only half of foreign key lookups will be ordered. In these cases, we try to batch constraint checks in memory to reduce the frequency of table reads from ~100x to ~10x in practice. In the long term, we will probably implement merge strategies that offer O(n) worst-case time complexity (where n is the table size). This strategy would be bad for small merges, where we are currently O(k) (where k is the diff size). But O(n) merge would help considerably for merges where referential constraint checking scales at O(k^2).
Imbalanced Merges
An interesting example Jason is
currently working on considers a diff(ancestor, from) with a few rows,
and a diff(ancestor, to) with ~100 million rows. In other words, we
are trying to merge a few rows from a feature branch 100M rows behind
to.
From a user standpoint this should be instant. Merge should be
proportional to the diff size of the rows we're adding from from. But
what if we added a check constraint in from? Like in the pigeon example
above, verifying referential integrity requires looking at the 100
million row diff(ancestor, to) diff.
We still need this edge case to be fast. You will have to tune in next time to hear more about this edge case.
Summary
We have not perfected data merge yet. But we have made merge proportional to change size for a wide variety of customer workloads. We will continue to tease out edge cases and improve merge user experience, correctness, and performance the same way we have the last 3 years through the next few.
If you have any questions about Dolt, databases, or Golang performance reach out to us on Twitter, Discord, and GitHub!