
This is our annual update on how our customers are using Dolt, the world’s first and only SQL database that you can branch and merge, fork and clone, push and pull just like a git repository.
Last year’s update included a lot more speculative use cases because we had fewer customers deploying Dolt in production. The one before that was more speculative still, because we hadn’t found our product market fit yet. This year’s update will focus on how our production customers are using Dolt today, and how Dolt’s unique version control features solve their domain problems.
Online v. Offline Dolt#
Today, our customers are using Dolt in two distinct ways:
- Online, as an OLTP database to back an application.
- Offline, as a way to version datasets.
For each of these primary use cases, we’ll discuss how real customers have deployed Dolt in production to solve their problems and enable unique functionality for their applications.
Online case studies#
Most of our paying customers are using Dolt as an OLTP database to back an application. Dolt fills the same niche as MySQL or Postgres in this role, but with the added capability of version control features such as branching and merging.

About half of our customers run their own Dolt server instance, and the other half pay us to run it for them via our hosted offering. They access Dolt’s version control features primarily via stored procedures and system tables, but use the command line to administer their databases as well.
Nautobot: a CMS for network configuration#

Nautobot is a content management system (CMS) for network configurations. It uses database tables to store customers’ data on routers, NAT tables, and other configuration elements that network professionals need to manage their network deployments. Their web GUI to manage these elements looks like this.
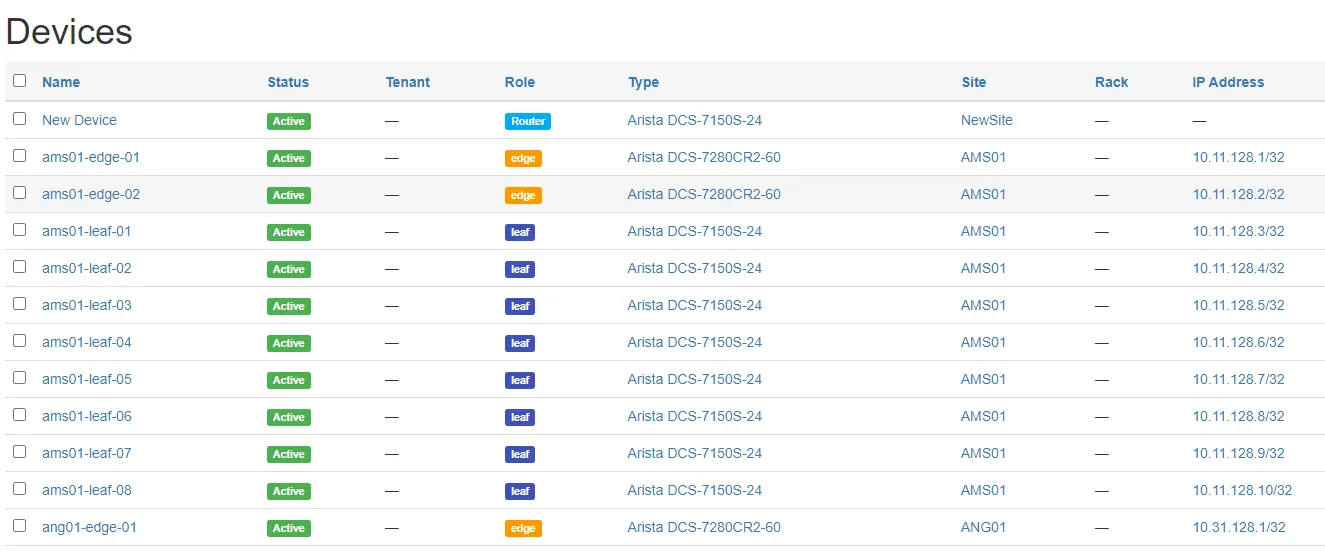
They integrated with Dolt in order to give their customers version control over these configurations. The advantages of this setup should be self-evident to anyone who uses version control for their source code.
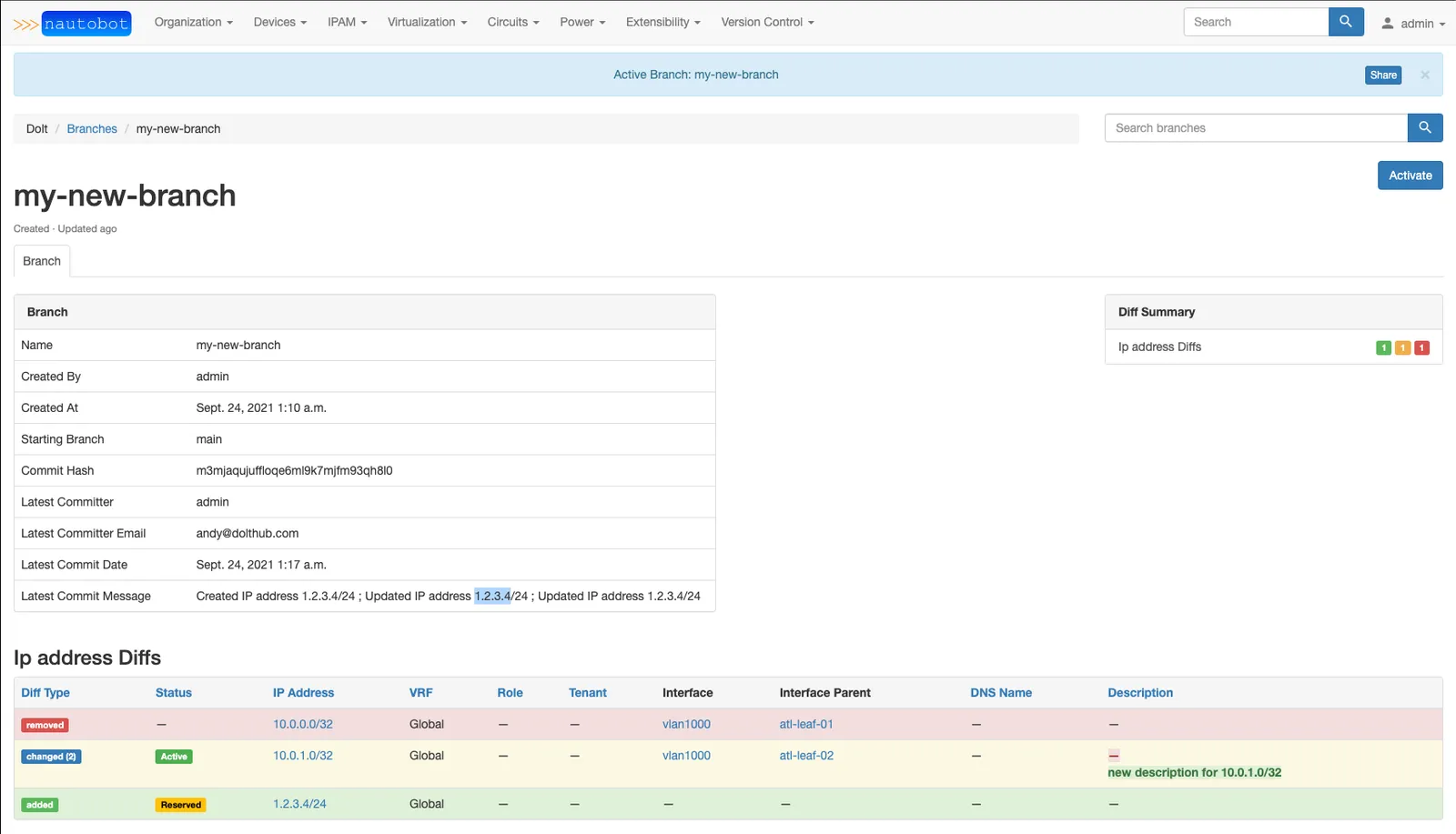
Customers can see diffs between two revisions of a configuration:
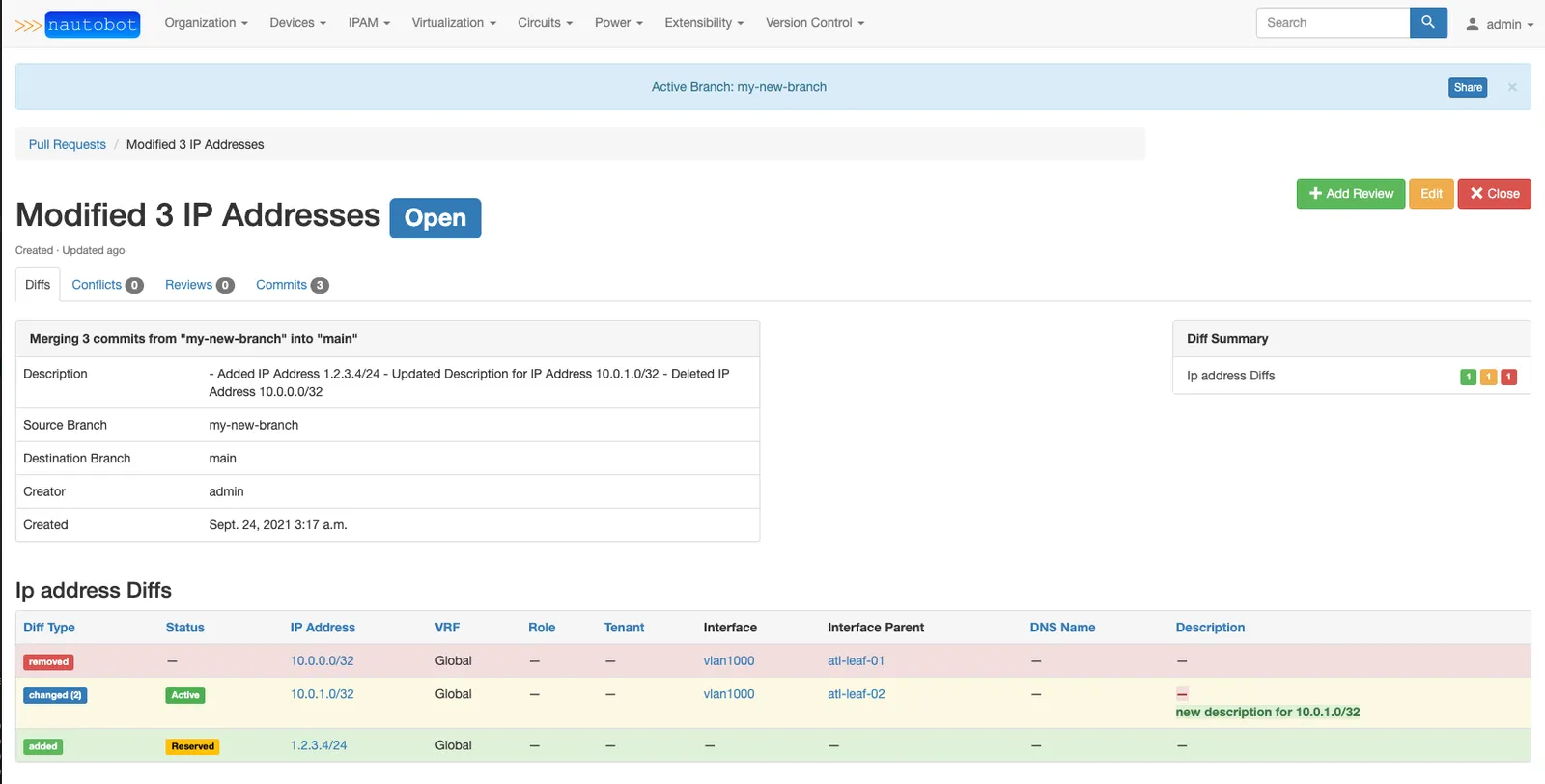
They implemented a pull request workflow to allow changes to network configurations to pass through manual human review:
And of course, Dolt’s diff and merge capabilities allowed them to implement one-click rollbacks for bad changes.
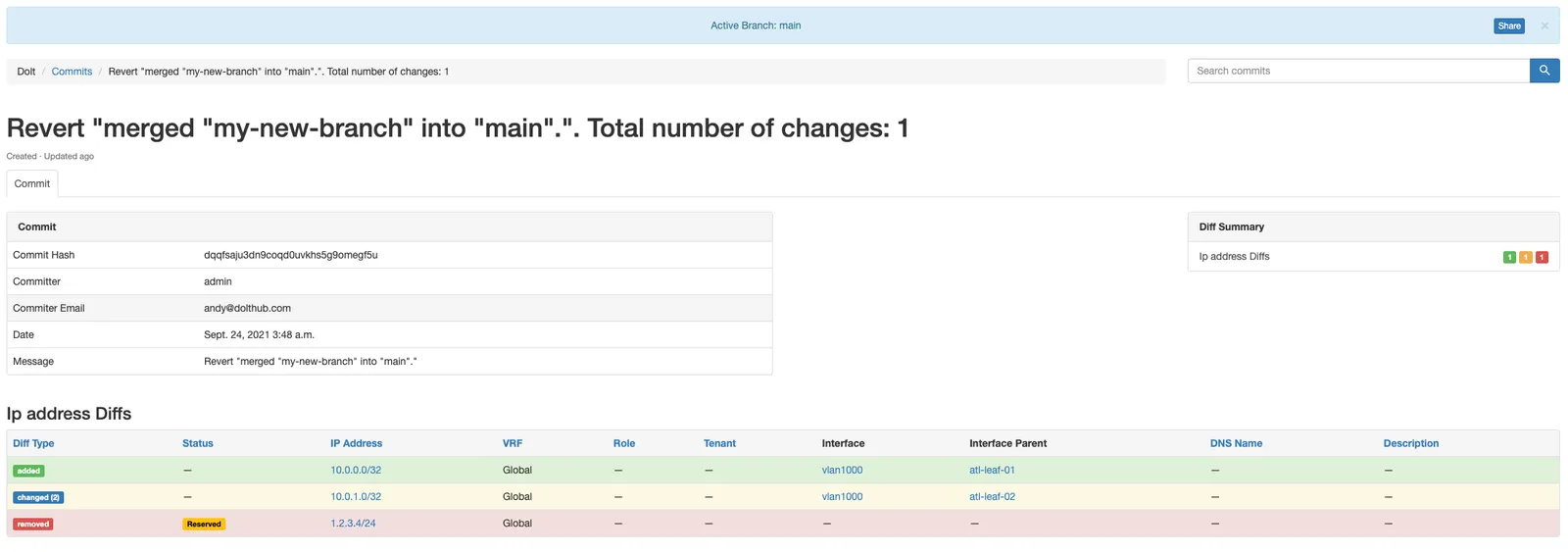
You can read more about Nautobot’s integration with Dolt in our blog here.
Turbine: worldwide data collaboration on cancer genomes#

Turbine builds virtual cancer cells and uses AI to train their behavior to match biology. Simulating how these virtual cells react to different methods of intervention allows the company to deliver value and drive efficiency throughout the drug development pipeline. One of such virtual cell’s underlying database consists of dozens of tables, containing gigabytes of biological data points. Turbine needs to keep track of different versions of virtual cells so they can reproduce simulation results and improve their model.
Turbine builds its simulations on top of a huge collection of biological data containing cell lines, mutations, drug effects and the connections between all of these. This complex data is continuously extended with the addition of newly acquired measurements, information about new proteins, or simply, the calibration of the parameters describing the behavior of the system.
The data is altered in multiple ways: new data can be imported, AI algorithms might fine tune the parameters that influence the model behavior, and even biologists may manually alter the network. This work is distributed among many teams, who might work on different projects.
Here are some examples of the types of projects being executed in parallel by research teams:
- Extend the model requiring change to the schema itself.
- Expand the network with new proteins .
- Calibrate the model parameters by automatically fine-tuning parameters with AI scripts based on new laboratory results.
All of this change should preserve the system’s integrity at all times, allowing each team to proceed independently, so different stable versions should be available simultaneously. Below is a visualization of their commit graph they provided us, demonstrating how they use the branches to support multiple active projects and developments at the same time.
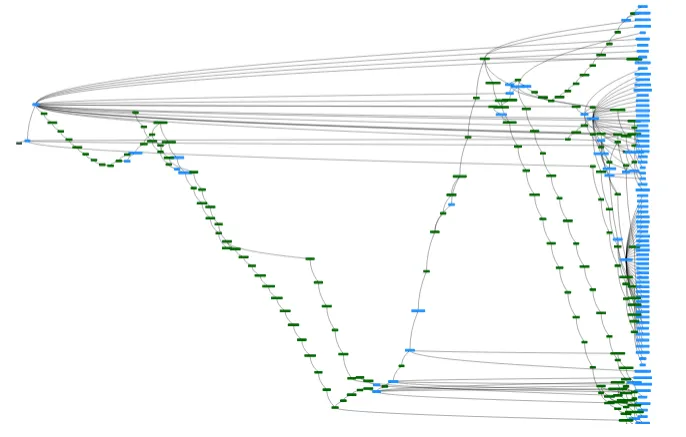
Before migrating to Dolt’s distributed branch and merge technology, all of this work was done in a MongoDB instance. MongoDB’s flexibility was a great solution for rapid prototyping, but it didn’t provide the stability and integrity that Turbine needed: data consistency and real, git-like versioning and branching. Users used to change documents that were used by other teams, and the lack of foreign keys caused integrity issues; all of which was identified much later, when biologists started to interpret simulation outputs.
Dolt was a perfect fit for the above requirements. Its versioning capabilities - which let you query any version of the data at any point in its history - allows Turbine’s teams and their AI algorithms to effectively work together on a shared biological model.
Game development: version asset data along with source code#
In modern game development, writing code is often a minority of the work. A much bigger part of the job is what’s referred to as asset creation, which means filling the game world with entities like characters, quests, enemies, dialog, etc. These assets and their metadata are sometimes built into the game binary directly, or sometimes loaded at runtime. For some games, it’s appropriate to store asset data in database tables, like this example:
CREATE TABLE `reward_drops` (
`enemy_id` int NOT NULL,
`item_id` int NOT NULL,
`chance` float NOT NULL,
PRIMARY KEY (`enemy_id`)
);Two game companies that we know of have integrated Dolt into their development workflow. They built asset management GUIs on top of Dolt that includes branch and merge workflows, similar to the Nautobot application. This lets them branch and merge their assets just like their source code, so that developers can try out their changes to the game, roll back to previous revisions, and work on different parts of the game without stomping each other.
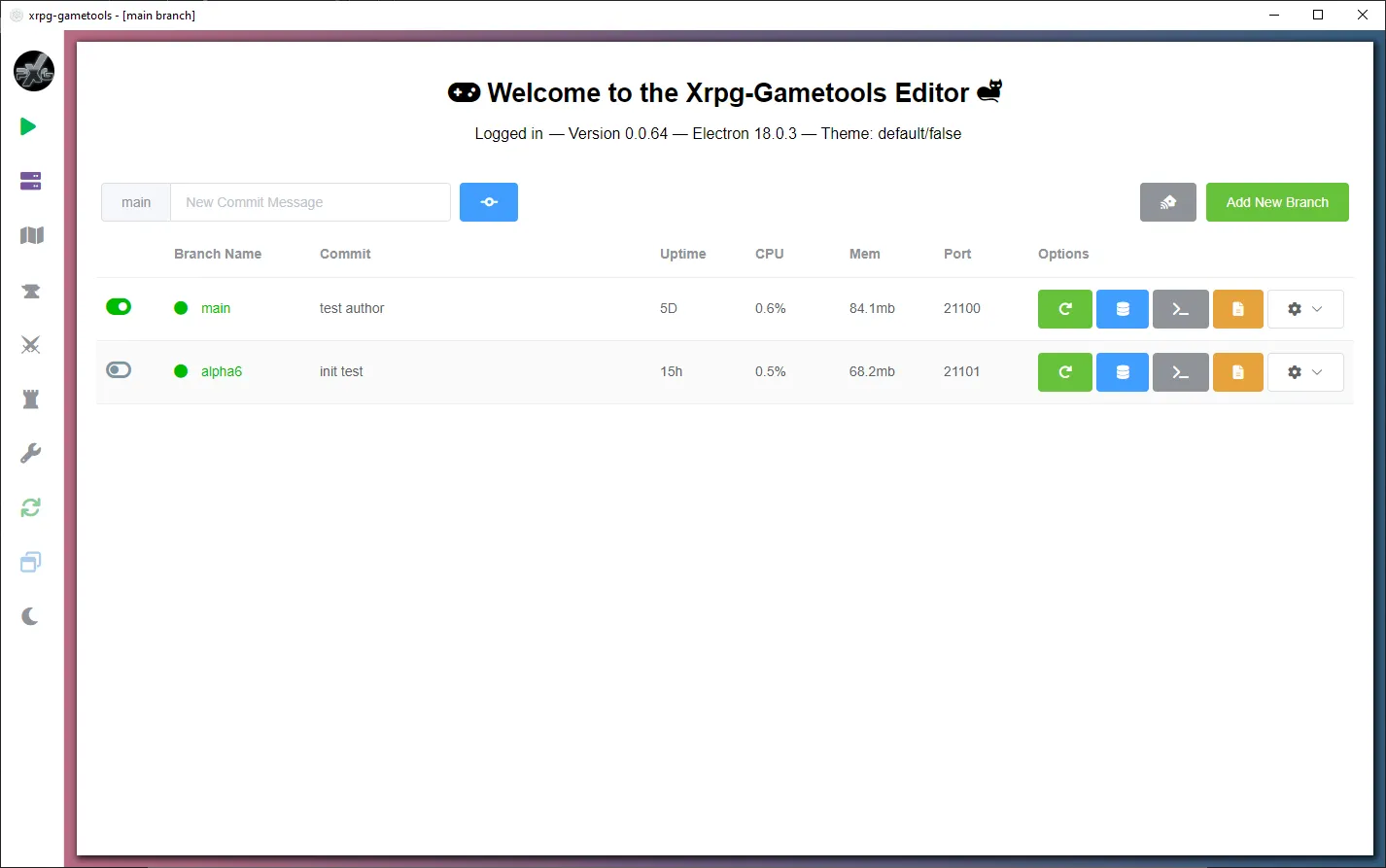
You can read more about Aether Story’s use of Dolt for development in their blog here.
In addition to the two game companies that have told us they’re building on top of Dolt, there are also several public databases on DoltHub that appear to be storing game data, uploaded by people who have never talked to us. This makes us think game development will end up being a popular use case for Dolt.
Other online use cases#
Not all of our customers are comfortable sharing details of their work. Here are some other notable use cases being built on top of Dolt by other customers building OLTP applications.
- Environment staging. Customers run a branch or clone for their development and staging environments, and deploy changes to the production environment in batches via merges.
- Customer partitioning. Customers establish a branch for each of their customers, which has the effect of segregating each customer’s data entirely. Schema changes to the application are merged into each customer branch, but customer branches are never merged into one another. This arrangement makes it simple to move each customer to its own physical host as needed for performance and operational isolation.
- Rollback and recovery. When mistakes happen, customers either
back them out via
DOLT_REVERT(), or just roll back the entire database to an earlier state withDOLT_RESET(). Unlike in other databases, these operations are instantaneous because the entire database history is locally available. - Personal database replicas. Customers clone their production or staging database to their local machine for development purposes, so they can experiment on real data without the possibility of causing an operational issue.
We’re excited to share more screenshots of our customers’ applications as they become ready, and we’ll update this showcase over time with the coolest examples.
Offline case studies#
A separate class of customers are using Dolt to store and version data, but aren’t using those datasets to back an application. Rather, they’re using such data as the input to a data processing pipeline, or to share for direct human consumption via statistical analysis tools like R. We call these offline use cases. Dolt takes the place of CSV or JSON storage in this role.
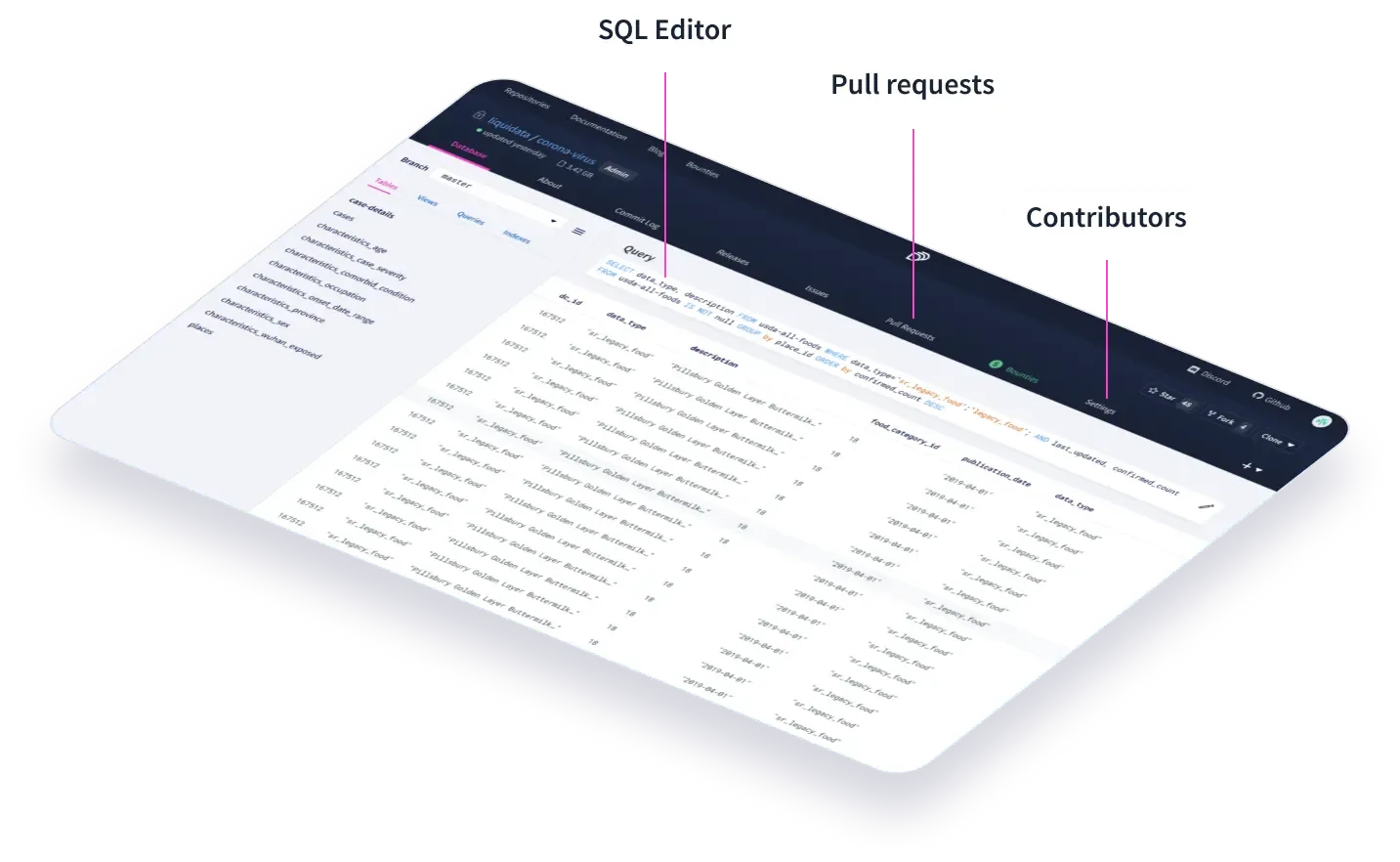
These customers typically are heavy users of DoltHub or DoltLab, which they use to share their datasets between team members and manage updating the main branches. Unlike our OLTP customers, our offline customers make heavy use of the DoltHub web interface to make changes to their data, and also spend more time managing their databases with the CLI, which copies git exactly.

DoltHub and DoltLab have the same feature sets but different provisioning and security models. DoltLab is effectively DoltHub in a box that you run yourself in your own data center. DoltHub is the zero-setup option for customers comfortable hosting their data on the public internet, where DoltLab is for security-sensitive customers who want DoltHub functionality but aren’t comfortable letting their internal data transit the public internet.
Aktify: versioned data ingestion for machine learning#

Aktify is a conversational AI company. They use machine learning to create virtual agents for their customers, capable of accurately responding to support chats and emails based on relatively limited training data from each customer.
Before adopting Dolt, data scientists would take data entered by analysts on Google Sheets and use it to create ad hoc models.
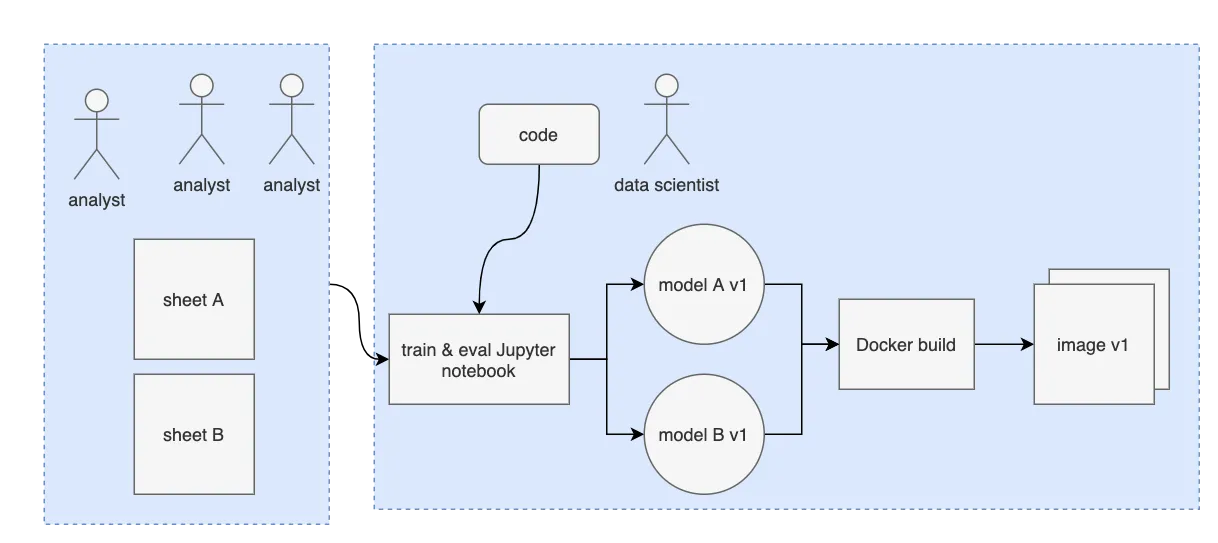
This worked OK when there were only a handful of customers, but as their business grew they began to experience problems and delays associated with being unable to keep track of their data ingestion processes and accurately reproduce existing models. They integrated with Dolt to version these data ingestion artifacts.

This lets them examine the difference between the data used to generate any two models, as well as roll back to a previous model if they discover mistakes in a particular batch of data that impacts model results.
You can read more about Aktify’s integration with Dolt in our blog here.
Data science reproducibility with R#
Noam Ross is a Principal
Scientist at EcoHealth Alliance
and a leader in the R data science community. He’s been working on
{doltr}, an R client for Dolt that gives data scientists access to
Dolt’s version control capabilities. This enables data scientists to
reliably reproduce their work and understand how their input data is
changing over time.
![]()
We talked with Noam at a meeting of the New York Open Statistical Programming Meetup, where he demonstrated how to use Dolt with R to add reproducibility to data science. Check out a video recording of the talk below.
Collaborative data set collection#
For over a year DoltHub has been running data bounties to pay volunteers to build public datasets. We do this to demonstrate how Dolt enables collaboration on data collection and editing, and we open source all the data collected. We’ve given out over $100,000 in prize money to dozens of participants so far, and we run at least one new bounty every month.

DoltHub’s pull request and fork features power the bounty process. Each volunteer gets their own fork of the bounty database, makes their edits locally using whatever tool they want (SQL workbenches, CSV import, etc.), then opens a pull request back to the central database. Our bounty administrator reviews each PR and decides what gets merged in.

These bounties have generated some really interesting data, which our bounty administrator Alec analyzes to produce cool visualizations like the ones above. The images above come from his analysis of our housing prices bounty, which you can read more about here.
New use cases wanted#
Our customers keep inventing new and interesting ways to make use of Dolt, and we’ll add new entries to this showcase over time.
Have your own idea for how to use the world’s first version controlled SQL database? Get started by installing Dolt today, or come join us on Discord to talk to our engineering team and meet other customers. We’re waiting to hear from you.