
Dolt is a version controlled database. How would one use such a thing?
- Do you gather data from a bunch of sources?
- Is data quality an issue?
- Do you detect defects at ingestion or do defects manifest downstream as production errors?
- How long does it take to debug and correct an error in ingested data? Can you examine differences?
- Can you instantly roll back?
- How do you implement human review?
With Dolt, you get all the convenience of Git-style source code control in your database, for both data and schema. We think a primary use case is to organize and simplify the data ingestion path, letting your data analysts and data scientists spend more time building models and less time cleaning data.
This is exactly what we did for customer chat data at Aktify. Aktify needed a solution to manage their ever-growing portfolio of customer data they use to build conversational artificial intelligence models, a rapidly growing field of Natural Language Processing (NLP). In just under three months, Aktify organized their data ingestion and model building process with Dolt, reducing load on their data analysts and setting them up for their next stage of growth.
Aktify has Next Level NLP#

Aktify creates virtual agents for your customers. These virtual agents chat, email, and text on your behalf, driving outstanding results. Aktify’s magic is in their NLP. Aktify has an unparalleled corpus of interactions between humans and customers. They use this to train a best of breed model of agent/customer interactions. Aktify leverages the power of transfer learning to adapt their model to your use case with your limited data. As you feed Aktify more data their model learns and gets better for your customers.
Aktify had no problem attracting new customers because of their results. This created the “good problem” of having to ingest a lot of customer data and keep it clean. This is where Dolt came in.
The Transformation#
Before#
Like any scrappy start up Aktify started with a simple process. Analysts entered customer data via Google Sheets. The lone data scientist processed the data in an ad hoc manner to produce models. This worked when the team was only managing a few customers but as the company grew, the process became unwieldy. This slowed down the team and made it hard to deliver for new customers.
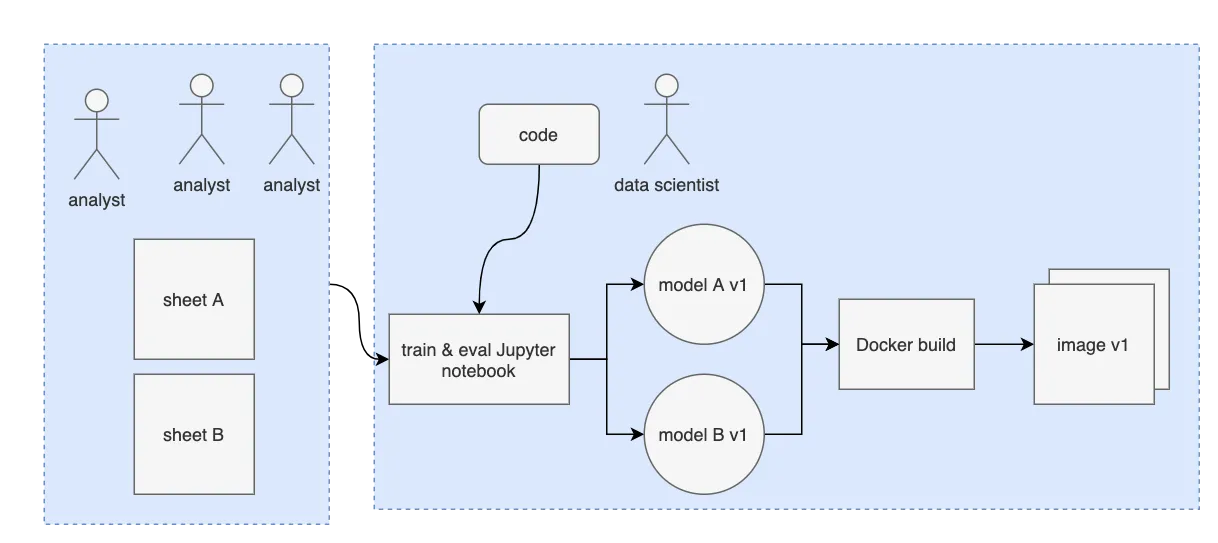
After#
Aktify found Dolt and was intrigued by its versioning capabilities. Could a versioned database help Aktify scale their data ingestion process? After consulting with us, Aktify chose a solution that leveraged Dolt, GitHub Actions, and MLFlow to organize their workflow, setting them up for future growth.
Aktify inserted Dolt in between it’s analysts Google Sheets and their Machine Learning pipeline using GitHub Actions to keep it all in sync. Aktify used MLFlow to automate their Machine Learning model building process and deployment.

Why Dolt for Aktify?#
Dolt and Natural Language Processing (NLP) are a natural fit. A version controlled relational database provides a number of practical benefits to NLP practitioners.
Compatibility#
Dolt is MySQL compatible. Any tool that can connect to MySQL can connect to Dolt. This makes it easy to slot Dolt into your existing data infrastructure. In Aktify’s case, analysts were happy ingesting and modifying data using Google Sheets. Dolt with a little help from GitHub Actions was able to add structure and process to this workflow without changing the interface analysts were used to. Using Dolt allowed Aktify to keep tools and processes that work while adding additional features.
Schemas#
Schemas are not a Dolt specific feature but a feature of all relational databases. Data in the Machine Learning space is usually loosely structured, stored in CSVs or JSON. Schemas provide more information about the form and function of the data being stored, allowing for stricter constraints on data being used. Stricter constraints improve data quality by detecting bad data before it makes it into the database. Text data used in NLP fits naturally in a relational database model unlike image and video data common in other Machine Learning verticals. Schemas improve data quality.
At Aktify, the schema is modeled to not allow a certain class of emoji characters that often appear in texts into the system resulting in guaranteed data quality downstream of ingestion.
Instant Rollbacks#
If an analyst discovers an error in a previous import, the analyst can instantaneously to rollback to any previous state. Accidentally committed data that has an error in it? No problem. Just issue a dolt reset --hard. If you want to go back even further, identify the commit of the database version you’d like and run dolt reset --hard <commit>. Dolt stores the full history of your database in an easily accessible form going back to database inception.
In Aktify’s case, analysts often accidentally delete sheets. In the past, this would have resulted in costly downtime as the analyst rebuilt or recovered the data. In the new Dolt powered system, this was a non event.
Differences#
In the above case, you may also want to debug what happened. Examining differences (ie. diffs) between various imports often makes the problem obvious. Did someone delete some important data? Does the formatting of new data not match with what you expect? These types of issues are easy to identify from looking at the diffs.
For Aktify, we gave the analysts the ability to read their diffs into Google Sheets as a new sheet so they could debug issues in their tool of choice. This allowed new analysts to have their data reviewed by more senior analysts in a Pull Request style workflow. This reduced data errors from new analysts and allowed them to onboard more quickly.
Lineage#
Dolt has a log of every cell in your database so you can see who changed what when. This feature gives Aktify insight into how a customer database is changing over time. Is the customer sending frequent data updates? Is it a lot of data or a little per update? These insights allow Aktify to build a deeper customer relationship based on data and improve performance of their models.
Automation#
Dolt lays the groundwork for process automation in Aktify’s whole Machine Learning pipeline. Dolt integrated seamlessly with MLFlow. Aktify went from a hand driven process by data scientists to a production grade Machine Learning pipeline increasing the number of models trained per day from dozens to hundreds.
Is Dolt right for your NLP Use Case?#
Are you running a NLP Machine Learning pipeline? Do the process improvements Aktify captured by adopting Dolt sound interesting? Dolt can help you too. Hit up brianf@dolthub.com and he’ll schedule some time for you to talk about your use case with our CEO. Or, if you’d like to hang out in a more informal setting, stop by our Discord and let’s chat.