
Here at DoltHub, we develop Dolt, the first SQL database with Git’s version-control capabilities: you can branch, merge, clone, and reset your tables just like Git does with your files. It’s Git, for Data!
But of course in order to do any of that, your database needs to actually have data inside it. A database is no good unless you import data into it. That’s why in addition to being able to import SQL dumps, we also have the highly-configurable dolt table import CLI command, which supports loading data into Dolt from a variety of standard formats, such as CSV and JSON files.
Recently, when we were talking about how Dolt supports vector indexes, we walked through how to import data sets from HuggingFace. In that example, the files we used were in the Apache Parquet format. This is the standard format used by HuggingFace for datasets: if you upload other formats, they’ll actually convert your files into Parquet as a standard option for users to download.
In that same blog post, I talked about how Dolt currently only has partial support for Parquet. It can import some schemas but not others, although we’re prepared to improve support if a user indicates that they need it: we take user requests very seriously and rely user feedback in order to determine what features to focus on.
This all begs the questions: what makes Parquet more challenging to support than other data formats? And why does HuggingFace prefer it?
The short answer is because…
Parquet is a column-oriented format#
You may see the terms row-oriented and column-oriented thrown around. They refer to how structured data is actually stored on disk. If you’re already familiar with these terms, feel free to skip this section.
Most common data serialization formats are row-oriented. This means that if you’re serializing a collection of records, the format stores each record in sequence.
Take this hypothetical table, cataloging a hobby shop’s inventory of trading cards for sale:
| Name | Condition | Price | Quantity |
|---|---|---|---|
| Blue Lotus | Near Mint | $8000 | 9 |
| Angelic Tutor | Lightly Played | $42 | 7 |
| Wrath of Dog | Damaged | $650 | 4 |
You could choose to store this as a CSV (comma separated values) file:
Name,Condition,Price,Quantity
"Blue Lotus","Near Mint",8000,9
"Angelic Tutor","Lightly Played",42,7
"Wrath of Dog","Damaged",650,4Or as a JSON file:
[
{
"Name": "Blue Lotus",
"Condition": "Near Mint",
"Price": 8000,
"Quantity": 9
},
{
"Name": "Angelic Tutor",
"Condition": "Lightly Played",
"Price": 42,
"Quantity": 7
},
{
"Name": "Wrath of Dog",
"Condition": "Damaged",
"Price": 650,
"Quantity": 4
}
]Note how in both of these examples, all of the data for an individual record gets stored together. You get all of the data for “Blue Lotus”, followed by all of the data for “Angelic Tutor”, and so on. This is what it means to be row-oriented.
Dolt also uses a row-oriented data format internally. This makes it easy to efficiently import data that is also row-oriented format: parse each record from the data source, insert that record into storage. Easy-peasy.
Being row-oriented has some clear benefits. It’s more human readable, for one. It also means that if you want to look up an entire record, you only need to read a single section of the file, and likewise inserting or updating a record only requires modifying a single section of the file. For these reasons, row-oriented data stores are commonly used for Online transaction processing (OLTP).
Row-oriented data is great when you’re reading or writing entire records, since each record is stored in one place. However, this comes with a trade-off: operations that only care about a small number of columns still now require multiple reads, spread out across the data. Imagine we want to count the total number of cards for sale. If this was a SQL database we might write:
SELECT SUM(quantity) FROM inventory;In order to evaluate this query, we would need to read the quantity field from every record: this essentially requires reading the entire dataset, even though we only care about a single column.
It also means that operations like adding or dropping columns requires rewriting every single record, which can be expensive. And it means that when you’re designing your data schema, you need to be thoughtful about what columns you want your data to have, because changing them later will be costly.
And this is where column-oriented formats enter the picture. Imagine if we laid out the data like this instead:
{
"Name": ["Blue Lotus", "Angelic Tutor", "Wrath of Dog"],
"Condition": [ "Near Mint", "Lightly Played", "Damaged"],
"Price": [ 8000, 42, 650],
"Quantity": [ 9, 7, 2]
}This is an example of a column-oriented data layout: we’ve broken up the records and organized them into columns, where each column contains all the values for a single record field.
In this format, it’s very easy to get all of the values for a single column. The previous example of summing every “quantity” field can be done simply and efficiently. For reasons like this, column-oriented data stores are commonly used for Online analytical processing (OLAP). And there’s other benefits to grouping data by column too: for instance, grouping similar types of data together means it’s usually more compressible.
Given this, it makes sense why HuggingFace would go for a column-oriented format as their standard: HuggingFace stores datasets used for machine learning models. This is a clear OLAP use case. Records in these datasets are rarely added or modified, but being able to efficiently run analysis queries on them is essential.
At its core, this is how column-oriented formats like Parquet work: a Parquet file stores every value for Column A, followed by every value for Column B, and so on.[1]
However, while columnar data makes some previously hard tasks easy, it also makes some previously easy tasks hard. It’s now more difficult to correlate values across columns, and recreating a single record requires accessing multiple locations in the data.
It’s also a problem for processes that expect their data to be row-oriented.
What makes Parquet challenging for Dolt?#
As previously mentioned, Dolt’s storage format is row-oriented. In order to import data from a column-oriented format like Parquet, Dolt needs to reassemble the original records. Converting between row-oriented formats and column-oriented formats isn’t cheap or easy, because it inherently requires collating data that was previously in disparate parts of the original format.
When Dolt imports a Parquet file, it loads the entire file into memory before it can add any rows to the table. This isn’t a hard requirement: a smarter approach would be to stream data from each column section in parallel. But no matter what, importing column-oriented data into a row-oriented database is going to be slower and more complicated than importing row-oriented data into a row-oriented database. But this can’t be the whole story, because while this explains why Dolt importing Parquet files might be slower, it doesn’t explain why some Parquet files are unsupported.
To understand that, we need to look at a more complicated use case: optional, repeated, and composite fields.
Optional and Repeated Data#
In the previous example, every field in our record type appeared exactly once in every record. But most data exchange formats recognize three different types of data:
- Required - every record contains every required field exactly once
- Optional - every record contains every optional field at most once, but may not contain it at all.
- Repeated - a repeated field may be contained possibly many times in a single record.
Let’s tweak our example to include an optional field (a note left for the shopkeeper) and a repeated field (a list of codes indicating which print runs of the card are in stock):
[
{
"name": "Blue Lotus",
"condition": "Near Mint",
"price": 8000,
"quantity": 9,
"edition_code": "1ED",
"edition_code": "BLB",
},
{
"name": "Angelic Tutor",
"condition": "Lightly Played",
"price": 42,
"quantity": 7,
"edition_code": "ISD",
"notes": "do not sell without manager approval"
},
{
"name": "Wrath of Dog",
"condition": "Damaged",
"price": 650,
"quantity": 4,
"edition_code": "RTR"
}
]Storing optional or repeated fields in a row-oriented layout is trivial: once you’ve loaded a row, it’s very easy to determine whether fields are repeated or missing.
But storing optional repeated fields in a column-oriented layout is substantially harder. Suppose we tried to list each value in sequence, like we did before:
{
"name": ["Blue Lotus", "Angelic Tutor", "Wrath of Dog"],
"condition": [ "Near Mint", "Lightly Played", "Damaged"],
"price": [ 8000, 42, 650],
"quantity": [ 9, 7, 2],
"notes": ["do not sell without manager approval"],
"editions": ["1ED", "BLB", "ISD", "RTR"]
}See the problem? Since there’s no longer a one-to-one correspondence between records and column values, it’s no longer possible to know which values for each field correspond with each other, which also means there’s no longer possible to reconstruct the original values.
But that’s just the tip of the iceberg. The real problems happen when you combine this with composite data.
Composite Data#
Composite data is simply a data field containing sub-fields, like a struct in many programming languages. Without composite data, a record is nothing more than a set of simple fields. With composite data, a record becomes more like a tree, with simple types only appearing at the leaves. This will be familiar to anyone who’s used JSON:
[
{
"name": "Blue Lotus",
"inventory": {
"condition": "Near Mint",
"price": 8000,
"quantity": 9,
}
},
{
"name": "Angelic Tutor",
"inventory": {
"condition": "Lightly Played",
"price": 42,
"quantity": 7,
}
},
{
"name": "Wrath of Dog",
"inventory": {
"condition": "Damaged",
"price": 650,
"quantity": 4,
}
}
]On its own, composite data doesn’t add any additional challenges. We can still easily represent this in a columnar fashion by creating a column for each leaf field:
{
"name": ["Blue Lotus", "Angelic Tutor", "Wrath of Dog"],
"inventory.condition": [ "Near Mint", "Lightly Played", "Damaged"],
"inventory.price": [ 8000, 42, 650],
"inventory.quantity": [ 9, 7, 2],
}But when you’ve also got repeated and optional fields, composite data compounds your problems. Suppose this same shop has a table of customer data. Customer’s may have an account, and an account may have a phone number:
[
{
"name": "Nick Tobey",
"account": {
"email": "nick@dolt.com",
"phone": "902-876-5309",
},
},
{
// Zach has no account. Poor Zach.
"name": "Zach Musgrave",
},
{
"name": "Tim Sehn",
"account": {
"email": "tim@dolt.com",
},
},
]Try and put this data in a columnar form, and not only will it be impossible to match up phone numbers with users, it’s not going to be possible to distinguish between a user with no account, and a user with an account but no phone number.
For column-oriented data formats to correctly store this, something extra is required.
How Parquet actually stores data#
Parquet uses a technique called “Repetition and Definition levels”. This technique was originally created at Google for use in Dremel, and you can read their original paper here. The relevant part is the section titled “Nested Columnar Storage”.
The core idea is this: if you store all values of a (possibly-optional, possibly-repeated) column consecutively, you lose the ability to reconstruct the original records because you no longer have information about the shape of the original data. But if this shape data is stored separately, it can be recombined with the value data in order to regenerate the data.
This “shape data” takes the form of two additional data streams: the “repetition level” stream and the “definition level” stream.
Consider a schema with nested repeated fields (Using here a protobuf inspired Interface-Definition language):
message r {
repeated group a {
repeated int b;
}
}When we read a new value from a stream of column data for the nested field a.b, there’s actually three different possibilities. This value could belong to:
- The previous
afield. - A new
afield in the previous record. - A new record.
If all you have is the stream of column data, these are all indistinguishable. But knowing which of these three cases is true is all you need to rebuild the original record.
Thus, for each value in the column stream, Parquet stores a corresponding “repetition level”, which is a simple number indicating how many levels of nested fields are being repeated. 0 for a new record, 1 for a single level of repetition, and so on.
So suppose the original records looked like this:
[
{
"a": {
"b": 1,
"b": 2,
},
"a": {
"b": 3
}
},
{
"a": {
"b": 4,
"b": 5,
},
},
]If we wanted to store this as column-oriented data, we would store both the a.b field, along with it’s associated repetition levels:
{
"a.b": [1, 2, 3, 4, 5],
"r(a.b)": [0, 2, 1, 0, 2],
}- For the value (1), no fields are being repeated, so the r-level is 0.
- For the value (2), the innermost (second) field is being repeated, so the r-level is 2.
- For the value (3), we’re introducing a repeated value of
ato an existing record, but this isn’t a duplicateb, so the r-level is 1. - For the value (4), we’ve begun a new top-level record. There’s no repetition at all here, so the r-level is once again 0.
- For the value (5), we’re once again repeating the innermost field, so the r-level is 2 again.
However, this doesn’t let us resolve all ambiguity. It turns out that there’s another dataset that produces this exact same set of both leaf values and r-levels. In fact, there are infinitely many. I encourage you to think about it for a moment and try and find one on your own.
Here’s one:
[
{},
{
"a": {
"b": 1,
"b": 2,
},
"a": {},
"a": {
"b": 3
}
},
{
"a": {}
}
{
"a": {
"b": 4,
"b": 5,
},
},
]Since these additional a fields don’t contain any leaf fields, they have no impact on either the streams of columnar data or the corresponding r-levels. If we want to be able to reconstruct them, one more piece of information is needed.
This extra bit of info is “definition levels”, or “d-levels”. The rule for d-levels is: every time a value is missing from the dataset, record a NULL for the column, and record the number of nested fields that were defined as the corresponding d-level. When a leaf value is present, we always record the maximum possible d-level for that value.
So for the immediately preceding example with the empty objects, the full combination of column data, r-levels, and d-levels would look like this:
{
"a.b": [NULL, 1, 2, NULL, 3, NULL, 4, 5],
"r(a.b)": [ 0, 0, 2, 1, 1, 1, 0, 2],
"d(a.b)": [ 0, 2, 2, 1, 3, 1, 3, 3],
}Like the r-levels, the d-levels have a small range of possible values and are extremely compressible. These two additional data streams provide all the data needed to uniquely reconstruct the original dataset.
And More#
Repetition and Definition levels are the core feature that powers Parquet, but there’s more to the format. Correctly parsing Parquet files also requires understanding how Parquet files:
- Embed table schemas
- Break columns down into pages.
- Store additional file metadata
- Support compression and encryption.
And more. The official spec has this helpful illustration laying out a high-level view of the file layout:
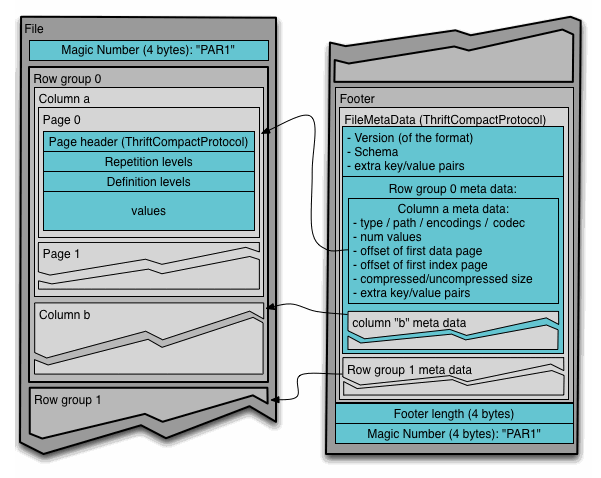
Parquet is a rich file format with many configuration options, and is designed for different use cases from Dolt and makes different trade-offs. Achieving 100% compatibility with Parquet files would be a significant endeavor.
So for now, we focus on supporting things that we know our users actually need. Right now Dolt can import Parquet files that contain repeated and optional fields, but not multiple nested levels of such fields. Dolt can import schemas with array columns, but not multi-dimensional arrays. If a user comes to us with an unsupported Parquet file that they want to import into Dolt, we’ll make adding that support a priority. But until then, we’ll focus on things that we know deliver value to our users, like improved query performance, more efficient storage, Postgres compatibility.
If you’re a Dolt user or have aspirations of becoming a Dolt user, we want to hear from you so we can understand what we should be prioritizing. Join our Discord server, and let us know what you want to see us do next!