
The latest version of Dolt includes lots of work to better parallelize, pipeline and schedule network requests when we fetch new commits from certain types of Dolt remotes. In some benchmarks, under some network conditions, pulls are almost 25x faster. In this blog post, I talk about how dolt fetch works, some of the changes we made to improve performance, and our plans for the future for even better performance.
Overview#
Dolt is a MySQL-compatible SQL database that supports Git-like functionality, including branch, diff and merge. It supports Dolt remotes, which can be cloned, fetched and pulled, and to which updates can be pushed. DoltHub supports a number of different types of remotes, such as file:// and aws://. By far the most common type of remote is a gRPC service that exposes an interface so that a Dolt client can communicate with it as a remote database. This service interface is used to communicate with DoltHub remotes, as well as for exposing a remotes interface on a running sql-server and internally to implement Dolt’s cluster replication.
Traditionally the code that Dolt uses to pull from a remote has been simple and functional, but it’s been prone to a number of bottlenecks that can impact its performance, especially in particular network conditions. Let’s take a look at what it takes to fetch new content from a Dolt remote and how previous versions of Dolt accomplished pulling the content. Then we can discuss some of the improvements that have just landed in Dolt 1.36.0.
Fetching New Content#
As a simplification, you can think of a Dolt database as a set of branches, each pointing to a Dolt commit. The Dolt commits themselves have zero or more parent commits, forming a chain back to the initial commit for the database. Each commit holds some metadata, like author, message, and timestamp, as well as a database root value. In turn, the root value has content-addressed information about the schema of the database at that commit, what tables exist, and, stored in Prolly-trees, the contents of those tables at that commit. All of these data structures are deterministically serialized into variable-length chunks that can refer to each other, and built up in a Merkle-DAG.
Whether a Dolt database is inside a local Dolt directory on your own computer or it’s a Dolt remote that you push and pull from, it has the same contents and structure. That means that a Dolt remote has its list of branch heads, pointing to commits, each with their root values and parents, etc. When you do a dolt fetch or a dolt pull, Dolt reaches out to the remote database to determine what are the current branch heads for the requested content. Then, the fetch operation needs to copy all of the data referenced by those branch heads into your local database. Pulls can be, and often are, incremental updates—the local database already has a copy of most of the data referenced by the remote branch, and Dolt only needs to fetch what is missing.
This is a classic Merkle-DAG walk to fetch and commit the missing content from the remote database into the local database. We start with a set of commit hashes which we would like to pull into the local database and we run the following loop:
HashesToFetch := InitialHashesToFetch
while len(HashesToFetch) > 0 {
HashesToFetch = FilterAlreadyPresentHashes(DestDB, HashesToFetch)
NewChunks := FetchAllChunks(SourceDB, HashesToFetch)
StageForCommit(DestDB, NewChunks)
HashesToFetch = GetAllReferences(NewChunks)
}
Commit(DestDB)At the end we have added all the missing content to DestDB, without needing to pull any data which was already present.
In Dolt, the component which performs this operation in the context of fetch, pull, push, standby replication and shallow clone is called the Puller. For many years, the Puller has operated largely in the above fashion. In particular, it would operate on one batch of need-to-fetch hashes at a time, without much pipelining between the various steps. A simplified UML sequence diagram for pulling looks something like this:
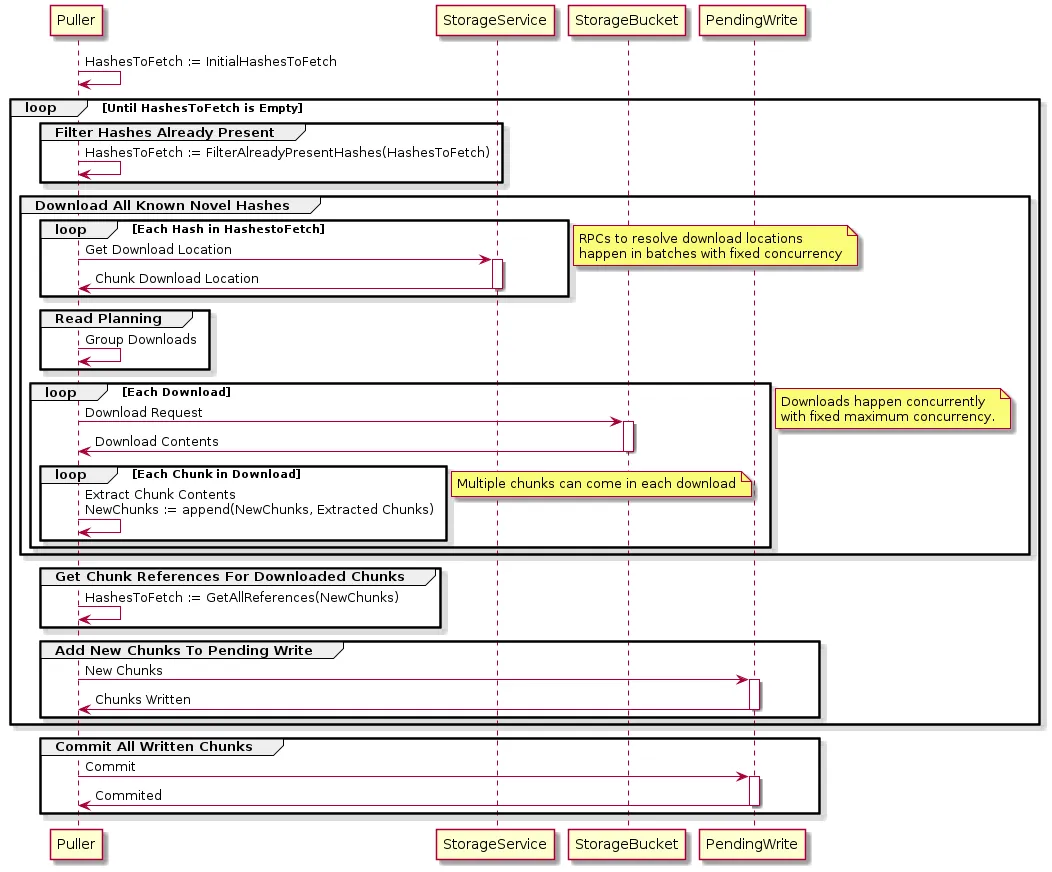
In reality, because HashesToFetch can be arbitrarily large, the Puller cannot operate on all of the HashesToFetch at once—it would batch them up into fixed size batches and operate on each batch serially, one at a time. As seen in the diagram above, the operation corresponding to FetchAllChunks(SourceDB, HashesToFetch), involves communicating with the remote server to determine where the remote chunks can be downloaded from, and then, after a read planning step which coalesces adjacent and near-adjacent download requests into a single request, it would make parallel download requests for all the remote byte ranges we needed.
This meant the Puller was subject to a sort of cascading waterfall behavior where a big batch of chunk addresses to download was assembled, all of those addresses were converted to read locations, all of those read locations were converted to download requests, and all of those download requests were executed. At each step, the Puller would have to wait for the slowest operation to complete before it could go on to the next step or the next iteration of the loop. If there was a late straggler in a batch, throughput could really suffer.
One way to reliably have a late straggler in a batch is to have a batch which gets coalesced into very uneven read requests. A batch might be 2^16 hashes to download, maybe corresponding to about 128MB of content to download. If a lot of that data is the novel leaves of a particular table, and they appear contiguously in a remote table file, then one of the coalesced downloads might be one large 116MB remote range, and the other downloads will be little byte ranges for the remaining chunks spread out across remote table files. If the internet connection Dolt is pulling across has relatively high aggregate throughput but relatively low single-connection throughput, you can end up in a situation where all of the small fetches complete very quickly but the large fetch takes a much longer time.
When I run some dolt fetch commands on my home internet, for example, I see network utilization graphs that look like this:
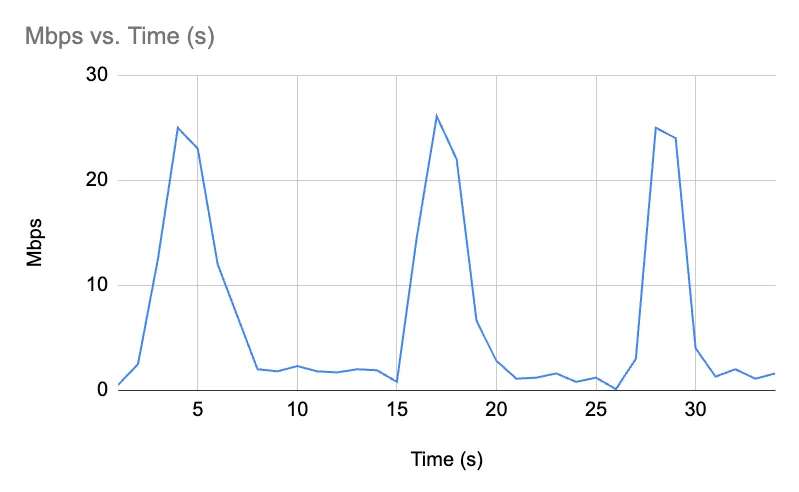
Which is simply not great for optimal throughput utilization or maximum performance at all.
Making fetch Faster#
We could attack the late straggler problem a number of ways. Dolt’s Puller already had retries and the ability to hedge requests when they were slower than other requests in their batch. But asymmetric large download sizes were not aggressively normalized across a batch, partly because many internet connections do not exhibit the kind of extreme throughput disparity between concurrent and single connection throughput, and partly because large download batches are faster if you can do multiple concurrently.
Overall, we would prefer to keep large(-ish) coalesced download ranges but to get rid of the cascading waterfall chokepoints that repeatedly stall progress to a trickle and then burst new work out all at once again.
The solution was to build a pipelined chunk fetching interface, which could receive a continuous stream of chunk addresses to fetch, and could deliver those chunks to a consumer whenever they were available. Settling on an interface that was somewhat inspired by grpc Client-side streaming, we made the Puller use the following interface for fetching new chunks:
type ChunkFetcher interface {
Get(ctx context.Context, hashes hash.HashSet) error
CloseSend() error
Recv(context.Context) (CompressedChunk, error)
Close() error
}The Puller now makes repeated calls to Get() and from a separate goroutine it makes calls to Recv(), processing the contents of the fetched chunks by finding all the addresses of chunks they referenced and by adding them to the table files which were to be committed as part of this fetch. In turn, this interface is easy to implement without pipelining, simply by serially batch getting each incoming hashes hash.HashSet, and delivering all of the returned chunks through Recv() before accepting a new set of hashes to fetch.
However, if an implementation wants to, a ChunkFetcher implementation is now free to pipeline and parallelize the resolution of the addresses to download ranges and the parallelization and scheduling of the downloads themselves. For remotes like DoltHub and dolt sql-server, which use our gRPC service interface, we built one of these ChunkFetcher implementations which tries its best to keep the data flowing in such a way that:
-
Newly downloaded chunks are more immediately converted to download locations.
-
Newly discovered download locations are more immediately coalesced into possible downloads.
-
Coalesced download ranges are more immediately dispatched to available download workers, when parallelism and throughput limits allow for it.
Performance Results#
But, is it faster? In some cases it’s much faster, and in some cases just a bit. Here are some experiments I ran comparing the new Puller against dolt v1.35.13.
This first set compares the performance from our office WiFi, in Santa Monica, CA, talking to a DoltHub remote whose servers and storage bucket are in AWS us-west-2, in Oregon. The office WiFi is generally pretty fast, and is not terribly subject to the slow-single-connection issue mentioned earlier. We run four different against different databases:
-
A
dolt fetchof the entire dolthub/SHAQ database, which is about 502MB of data. -
A
dolt fetchof the entire post-no-preference/options database, which is about 3.6GB of data. -
A
dolt clone --depth 1of dolthub/SHAQ, which is about 68MB of data. -
A
dolt clone --depth 1of dolthub/us-businesses, which is about 1.7GB of data.
Each download is run multiple times and we provide box plots for the various observed times.
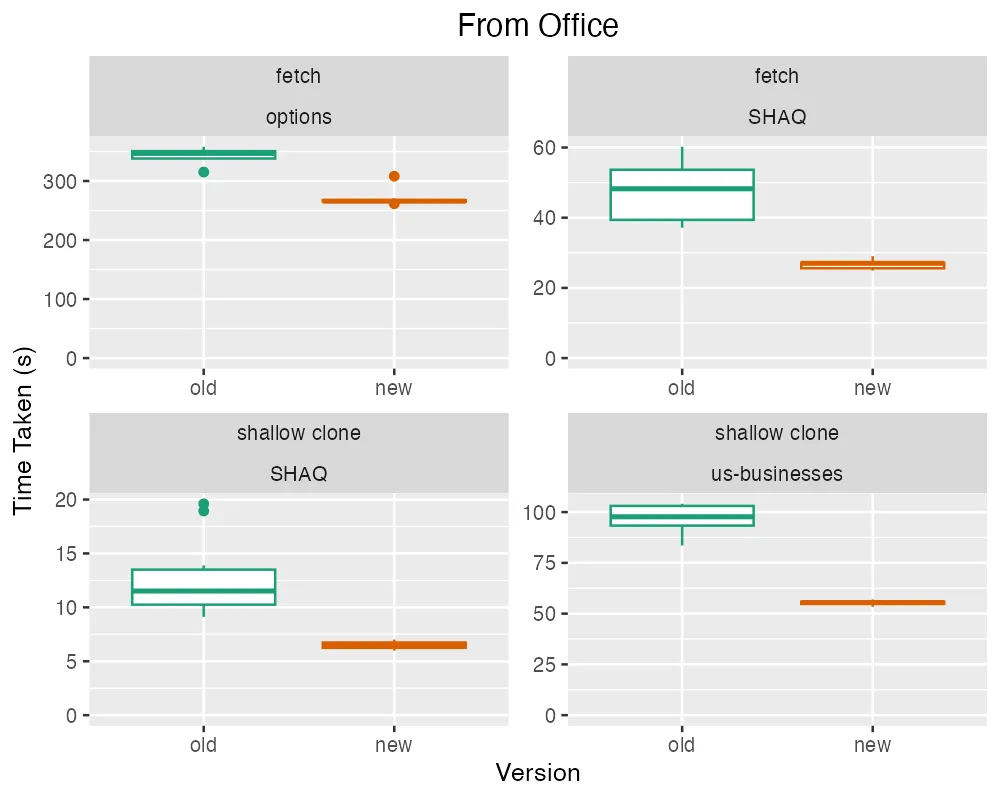
As can be seen, the new puller is somewhat faster for a number of the cases. It also exhibits much less variance.
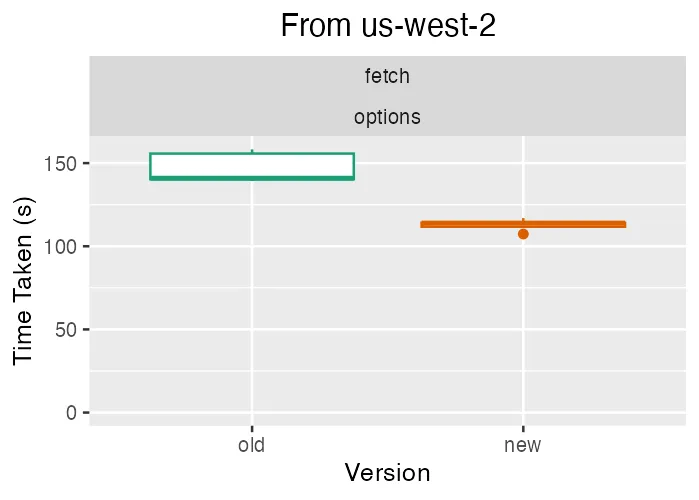
To test different network conditions, we also ran a full fetch of the options database from an EC2 host in us-west-2. This host has a very fast connection to the DoltHub servers and storage bucket.
And finally, some timing taken from my home WiFi, which for some reason has high throughput in general but has low throughput on a single connection download from our chunks storage bucket in S3.
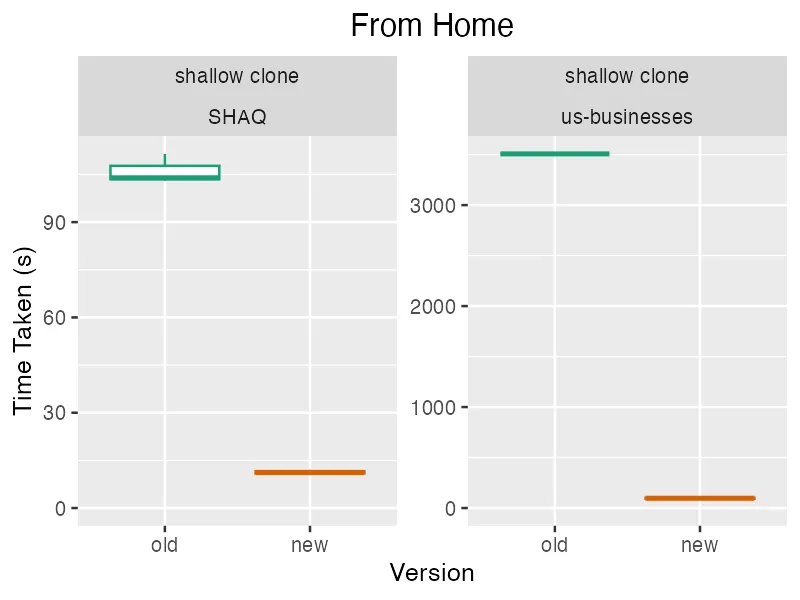
As you can see, my home internet was very antagonistic to the old Puller.
Tradeoffs and Future Work#
There are some known tradeoffs in the current implementation of the new Puller. As currently launched, the new Puller is more CPU intensive than the old Puller. It incrementally maintains read records for pending fetches in sorted order and maintains their coalesced batches in a heap to arrange that the next best download can be quickly selected when a download thread becomes available. This is more expensive than the previous operating mode of sorting a batch at a time and processing it fully before moving on to something else.
We’ve also observed that the new Puller can unnecessarily fetch duplicate data more often than the old Puller. Data can be downloaded during a fetch multiple times when read planning coalesces two reads that are not directly adjacent. If that read request gets dispatched but then a request to fetch the skipped bytes comes in later, then Dolt will end up re-downloading the previously “skipped” bytes. Because the new Puller is more aggressively dispatching download requests without seeing as much batched context when making its decisions, this happens more often with it.
For future work, we would love to improve I/O scheduling even more. We can still do a lot of things better, such as prioritizing fetching of chunks that are higher up in the Merkle-tree, so that the Puller can see more chunk addresses earlier and get larger ranges to download. We still have work to do on adaptive download concurrency and adaptive throughput throttling as well. And we could add adaptive tuning of maximum download sizes and read planning coalesce limits based on estimates of our bandwidth and round trip time to the storage server. While benchmarking and measuring the behavior of the Puller, some inefficiencies were discovered in our streaming RPCs for implementing the remote service interface — we would like to eventually further improve bandwidth utilization and CPU efficiency for some of the RPCs.
I’ve had a great time working on this for last few weeks, and I’m confident there are still a compelling performance improvements we will be able to deliver for dolt fetch in the future. If you have a use case that requires better dolt fetch performance, or you just want to talk network request scheduling, merkle-dag replication or gRPC streaming client performance, don’t hesitate to drop by our Discord.