
Users of Git, in particular hosted Git services like GitHub, are very familiar with the ability to send their changes to another location using the push operation. Dolt, as the spawn of Git and MySQL, has supported the ability to push to DoltHub.com for a long time, as it is critical for the data sharing use case. When we built our Dolt SQL Server, we held off on supporting the ability push to a running instance. This is no longer the case with release 1.30.0 As our final gift to our users in 2023, we’ve added the ability to use dolt push to get your changes into a Dolt SQL Server!
What we’ll cover today:
- How to Push to a Dolt SQL Server
- The Dolt Push Protocol
- The Responsibility of Power. Yay!

Pushing to a Dolt SQL Server#
Install the latest version of Dolt.
It is important that you have the correct version of Dolt installed to use this feature. Server and Client changes in version 1.30.0 are required. This applies both the destination server and the agent pushing - which could be another server or the
dolt pushcommand. Execution ofdolt versionwill tell you what version you have installed.
We’ll start a standard sql-server, with the addition of the --remotesapi-port argument. In an empty directory, start the server:
$ mkdir data; cd data;
$ dolt sql-server --remotesapi-port 50051Leave that running in one terminal. In another terminal, you’ll use the sql command to create a database, put some data in it, and commit it:
$ cd data
$ dolt sql
# Welcome to the DoltSQL shell.
# Statements must be terminated with ';'.
# "exit" or "quit" (or Ctrl-D) to exit.
>In the prompt you can use this sql to create a commit. What is in the commit doesn’t matter, you just need a commit that the client can fetch.
create database mydb;
use mydb;
create table tbl (i int primary key);
insert into tbl values (42);
call dolt_commit("-Am", "Create the tbl Table");Now in a separate directory, you can clone from the running server with the following command:
$ mkdir data_clone; cd data_clone;
$ DOLT_REMOTE_PASSWORD= dolt clone --user root http://localhost:50051/mydbThis will create the mydb directory, which you can cd into and run all the dolt
commands you like. This is your local copy. Let’s insert some rows, then commit:
$ dolt sql -q "insert into tbl values (23)"
Query OK, 1 row affected (0.00 sec)
$ dolt commit -a -m "Added my own row"
commit 1s3im5hhmsn13ibt050q0ifhrglj519n (HEAD -> main)
Author: macneale <neil@dolthub.com>
Date: Thu Dec 28 14:14:14 -0800 2023
Added my own rowAnd now for the big event! Pushing your change back to the server:
$ DOLT_REMOTE_PASSWORD= dolt push origin --user root HEAD:my_new_branch
- Uploading...
To http://localhost:50051/mydb
* [new branch] HEAD -> my_new_branchThere is now a new branch on the server which contains the row with 23 that you created in your personal copy. I’ll leave that as an exercise for the reader to verify.
It’s worth calling out that you can use a Hosted Dolt Instance for your server as well. Be sure to enable the remote API when creating your server.

Pushing like Git#
Dolt uses the same semantics as Git in terms of how to create, update, and delete branches from remote servers. For that matter, Dolt pushing to DoltHub has always followed these patterns.
We’ll dive into that in a moment, but first I’d like to call out the elephant in the room: What’s with DOLE_REMOTE_PASSWORD and the --user options? Similar to dolt pull, dolt push is interacting with a remote service which has its own set of users, and the way we specify the user and password are with these. The example above uses the root user with an empty password, but a real world usage would have actual values. If you are going to be using this operation frequently, it’s probably a good idea to set the environment variable with an export:
$ export DOLT_REMOTE_PASSWORD=<real password>The rest of the examples below will assume that you have the environment variable set for your password. If you want to use a local SQL Server which pushes to another server, dolt sql-server will use the DOLT_REMOTE_PASSWORD when it attempts to connect to another server. The dolt_push() stored procedure allows the --user flag as well. The important piece to remember is that whatever process will serve as the client requires the environment variable to be set.
With that out of the way, lets push!
Updating a branch is the most common, and in the simplest case, you will have a tracking branch based on how you created the branch. If you just cloned the database, the default branch will be setup to push to the right location.
$ dolt push --user rootPushes to existing branches require the your changes are fast-forward changes relative to what you are pushing to. This is almost always what you want if you are working on that branch with other people. Anyone who uses GitHub is familiar with an error which looks like this:
$ dolt push --user root
- Uploading...To http://localhost:50051/mydb
! [rejected] main -> main (non-fast-forward)
error: failed to push some refs to 'http://localhost:50051/mydb'
hint: Updates were rejected because the tip of your current branch is behind
hint: its remote counterpart. Integrate the remote changes (e.g.
hint: 'dolt pull ...') before pushing again.What this is telling you is that there are changes which would be lost if your attempted push has completed. In Dolt SQL Server, this includes not only changes which have been committed on the remote server, but also changes made by SQL sessions on the server which haven’t been committed yet.
The other option to integrating remote changes is the --force flag. Similar to Git, a wise developer can know that the changes being “lost” are ok the throw away, or your changes incorporate them in some more nuanced way. Dolt SQL Server has the additional complication that you can have changes on a branch that haven’t been committed. There is no equivalent in Git, or GitHub, because a remote can’t have a dirty workspace.
If you are really confident that you can override this protection, you can use --force:
$ dolt push --user root --forceCreating branches, similar to our example above, is done by pushing to a branch that doesn’t currently exist with a refspec. HEAD:new_branch will create the branch new_branch on the remote with the HEAD commit.
$ dolt push --user root HEAD:new_branchFinally, deleting branches is done in the same way as Git, but specifying a refspec with an empty left argument:
$ dolt push --user root :branch_to_deleteThe branch being deleted must not have uncommitted changes, similar to the update case. If the client wants to obliterate whatever changes are in flight, they can specify the --force option to bypass the safety check.
As you can tell, the --force option should be used with care. We haven’t fully discussed the permission requirements yet, but given the strength of this capability we’ve opted to require than anyone who can push must be a Super User. Let’s get into the why.
The Dolt Push Protocol#
DoltHub has a fairly low level data transfer protocol which has been happily serving us for a long time. This protocol is very tightly coupled to Dolt on disk storage format. It’s not an API which is meant for general use, but it’s open source so you are free to go take a look.
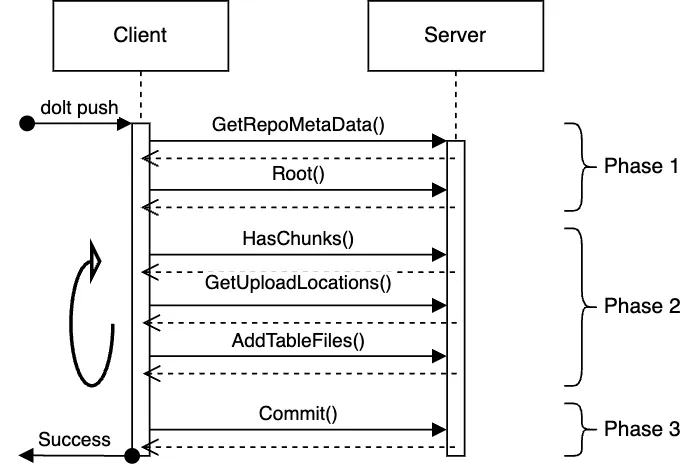
The protocol is all stateless call and response RPCs, and it breaks down into three phases:
- Phase 1: Client gets high level metadata and the root reference map, which we’ll discuss more below.
- Phase 2: Client inspects the Server state and what content it contains then follows up with uploads which get the data the client needs onto the server. There can be any number of calls in this sequence. This loop continues until the client is satisfied that the server has all information required for the write.
- Phase 3: The client calls
Commitwhich is an optimistic lock to update the root.
The terminal where you are running your server will contain log messages for each RPC call, so you can create additional changes and push them if you want to see the action in the logs.
The Root object is inspired by the named references approach of Git. Immutable information such as commits and their data are stored with a content addressed identifier, and we use strings which look like paths as domain specific names to those identifiers. An example:
{
"refs/heads/main": "3kg3b8lm42sui24357a87ciktuv9804l",
"refs/heads/newbr": "3kg3b8lm42sui24357a87ciktuv9804l",
"workingSets/heads/main": "m08r00sjrhqi5jhlh46t2b0nv86k7pnl",
"workingSets/heads/newbr": "h1u1788ior95jner5c4ovhvnri9g5pts"
}Here, we have two branches, main and newbr, and they both refer to the same object ID. For that particular type of reference, the objects are commits, which contain the author id, parents and other information you would expect to be in a Dolt commit. The workingSets references are for objects tracking information which hasn’t been committed yet. When you dolt diff to see what you’ve changed, Dolt is looking at the contents of the workingSet. You can see there is a working set for each branch, and they have different IDs.
In phase 1 of the protocol, the client gets the current root from the server, which is simply the reference names and their values as listed above. The client uses Phases 2 to not only upload data and commits of interest, but also to upload a new Root object which has the state that the client would like to update the server to. That Root object is content addressed like everything else.
In the final step, Phase 3, the client sends the server the Root ID retrieved in Phase 1 and the new Root ID, then the server performs the atomic update as a compare and swap operation.
Protocol Ramifications#
The current protocol to push to a Dolt remote is a blunt, yet powerful, tool. With great power comes great responsibility. Since the Commit RPC will allow you to swap to a new Root object without any inspection, the client could conceivably put an entirely different database with no common history in place, maliciously alter data, delete tags, you name it.

The client side logic that is present in the dolt_push() stored procedure prevents regular users from doing damage to the entire database. Logic evaluation, such as pushes need to be fast-forwards, is all performed on the client. When pushing, the client looks not only at the target branch HEAD but also the workingSet/ reference in the Root object. It does this to ensure the push won’t stomp any changes that users on the server are making. In the event that you need to supply the --force option to dolt push, Client code will ensure that you aren’t changing unrelated branches. The client code we supply in the dolt_push() stored procedure is where the safe guarding of data is performed.
It should be clear that this operation is not safe from malicious use, and as a result we’ve opted to require any user who wants to execute the Commit RPC must be a Super User in the SQL Server Database. Our example used the root user that the server was running with, but you could also create a user and grant all access to them. The following will make user@host a Super User:
GRANT ALL PRIVILEGES ON mydb.* TO 'user'@'host' WITH GRANT OPTION;The other ramification of this protocol is that there is a potential for lost races for the pushing client. If there are write transactions committing against the server while a push is ongoing, those can conflict with the optimistic lock race on the Root object, even if they are against completely different branches. It may be impossible for the pushing client to successfully win an optimistic lock race – a pushing client’s round trip time to attempt to update the Root is longer than the transactions which are running in-memory within the sql-server, and there is no mechanism in place to allow the slower writer to ever win the race.
Where We Go From Here#
Requiring users to have Super User privileges to use this feature isn’t a great look, but it’s a place to start. Extending the protocol to allow the client to provide a more fine grained update will allow us to use branch permissions rather than depend on Super User access. It will also allow us to reduce the amount of race contention. This work isn’t currently scheduled, but if we get a few curious users we’ll go ahead and do it. So join us on Discord and let us know!
The other piece I haven’t called out is the use of the DOLT_REMOTE_PASSWORD environment variable used to authenticate to the remote server. This isn’t ideal for too many reasons to list. There are many ways to authenticate in general, and which mechanisms Dolt supports will depend a lot on what our users ask for. Send us issues if you have specific use cases you’d like us to support!