
In the mid-2000s SQL was having a rough time. NoSQL was all the rage. A chorus of senior engineers shouted:
“SQL doesn’t scale."
"Oracle…Microsoft…waaaaaah!
”DBAs are expensive and get in developer’s way"
"$10,000 per core for a <bleep> Oracle license!”
This outrage led to a new era of NoSQL databases, the most successful being Cassandra, MongoDB, and Amazon DynamoDB.
But SQL is back. First we got free, production-grade SQL in MySQL then Postgres. We also got horizontally scalable SQL in CoackroachDB. We got JSON support in SQL databases to compete with MongoDB. Even SQL made it’s way into DynamoDB. Moreover, we’re getting innovative new features in SQL databases like data version control in Dolt.
SQL can’t be killed because SQL is great. This blog explains SQL’s 50-year history and why it will be around for another 50 years at least.

NOTE: This blog leans heavily on the Online Transaction Processing (OLTP) use case for SQL but there is also the Online Analytics Processing (OLAP) and embedded SQL (ie. SQLite) use cases that carry the torch for SQL as well.
SQL: A 50-year History#
This highly abbreviated history is not meant to be exhaustive. It’s meant to hit the high notes of SQL’s 50 year journey and really highlight the struggle between developers and Oracle that has existed since the 1980s.
Invention#
I’m going off wikipedia here because I wasn’t alive. The good folks at IBM started working on SQL in 1973. The first commercial version was shipped in System/38 in 1979. This was quickly followed by SQL/DS in 1981 and IBM Db2 in 1983.
![]()
Oracle, then Relational Software, Inc., saw the promise of SQL and made a competing system, Oracle V2, released in 1979. The SQL war was on.
![]()
By 1986, the ANSI and ISO standard groups officially adopted the standard “Database Language SQL” language definition.
Popularity#
It’s fair to say that before the Internet, the SQL database was the computer’s “killer app”. Every company needed a SQL database to keep track of things that used to live on paper in filing cabinets. Through the 1980s and early 1990s, the transition from paper-based companies to electronic records-based companies was driven by the network connected SQL database. Every office worker got a computer on their desk and the software it ran connected to SQL databases.
The efficiencies this change drove were enormous. The SQL database providers could charge high prices because the savings companies reaped were so large. We’re saving $10M by adopting Oracle, it’s fine to pay Oracle $1M of that. As such, IBM and Oracle became very big companies.
The Standard#
SQL became the standard. As the internet really got going post-1995, websites needed to be backed by high scale SQL databases. Now, your software wasn’t just used by your company, it was used by the world. SQL databases were the way to handle this scale.
Oracle ended up winning the SQL database war in the 1990s. Oracle was just better software than IBM Db2 or Microsoft SQL Server. It could scale larger with fewer issues. All the well known early Internet giants, Amazon, Yahoo, Ebay, were Oracle shops.
“With great power comes great responsibility”. Oracle failed that test. Instead, Oracle said “Pay us all your money”. As an example, at Amazon in the early 2000s, the annual Oracle licensing fee was $50M per year. This was so outrageous, that the edict came from on high, no more Oracle!

Amazon announced it was Oracle free 15 years later. That’s the kind of spite you just love to see.
Free!#
As such, the world needed a free, open source SQL database. After being released publicly in 1996, MySQL eventually fit the bill. Though it started a bit janky, MySQL became a viable alternative to Oracle for many use cases once version 5 was released in 2005.
![]()
I was an early MySQL 5 adopter. You could run most applications on it. MySQL was not for high scale, high throughput workloads but most applications aren’t that.
NoSQL#
But MySQL gets acquired by Sun Microsystems in 2008 and Sun Microsystems gets acquired by, you guessed it, Oracle in 2010! Will we ever escape? Could Oracle’s stranglehold on SQL kill it altogether?
Moreover, SQL databases had not grown out of the primary/replica model of scaling. This model could support early internet application but by now practically everyone had the internet and these websites were serving even more traffic. New, horizontally scalable, eventually consistent databases were created for large scale use cases. First Apache Cassandra was released in 2010. Amazon DynamoDB was launched in 2012. Big, hot companies like Netflix were early proponents of this technology fueling the hype train.
Coming from another NoSQL angle was MongoDB, released in 2009. What if we got rid of tables altogether and just stuck JSON in the database? That was MongoDB and it made sense for the web where most of your data needed to be in JSON eventually anyway.

The Comeback#
For a while, if you were building an application you looked NoSQL first. But developers craved the simplicity and power of SQL. Tables and transactions are easy to understand. Could a SQL alternative to Oracle and MySQL emerge?
Enter PostgreSQL or as most people call it Postgres. Postgres had been around since the 1980s but it only started supporting SQL in 1995. Postgres really got going around 2015 with version 9 when replication was released. At that point it became a credible, open source database you could run in production. The best part was that Oracle was nowhere to be seen and couldn’t buy it. Postgres is supported by a non-profit organization, not a company. The world finally had Oracle free SQL. Postgres could work in the traditional primary/standby model of SQL databases, replacing Oracle or MySQL.
![]()
CockroachDB, launched in 2015, filled the horizontally scalable SQL niche. So, now you can have SQL and horizontal scaling. DynamoDB even started supporting SQL. The key NOoQL feature, horizontal scalability, was now available in SQL form.
Moreover, JSON types and functions got support in SQL. Postgres added JSON types in 9.2 circa 2012 and MySQL add JSON types in 5.7 circa 2015. This added MongoDB functionality to the SQL database. You could also mix tabular data with less structured JSON data to obtain the best of both worlds.
In 2019, Git-style version control was introduced to the SQL database with the release of Dolt. Innovation is happening again in SQL. What else is in the future of this 50 year old technology?
SQL is back! Most companies are building applications on SQL databases again. There is a place for NoSQL but SQL seems to be back to the default choice.
So, Why?#
As you can see, SQL has stood the test of time. It’s the gold standard. Why?
It’s easy to get started…#
People understand tables. You learn tables in elementary school math. If you’re into sports, you see standings and statistics in tables. Spreadsheets present a very accessible tabular data user interface. It’s not a big leap to SQL from this almost ubiquitous foundation.
Beyond understanding tables, SQL makes it easy to compose queries in a fairly natural language. SQL is much more accessible than even high level programming languages like Python. So, if your a programmer, you can easily grok SQL.
…And powerful if you need it.#
Hidden behind the simplicity of tables and queries are very powerful features. Joins allow for complex analytical queries. You can represent even the most complicated data as a hierarchy of tables. Transactions are a simple model to handle concurrency. If two writers update the same row, one of the writes fails and the other succeeds. SQL databases support hundreds of functions to craft powerful queries that can offload logic from your application to the database. This is not to mention advanced features: Views, Procedures, Triggers, Events, and Collations. SQL databases pack a lot of firepower.
The Standard#
There’s also power in SQL being the standard. There’s great SQL documentation from the database vendors themselves as well as third parties. SQL integrates well with other tools in the data ecosystem. There’s SQL workbenches, change data capture, Object Relational Mappers (ORMs), and much more. SQL has existed for so long that there is a tool for almost every job.
Data Quality#
Finally, an underrated aspect of SQL is that it includes powerful data quality control tools. In my opus on Data Quality Control, I presented the following model:
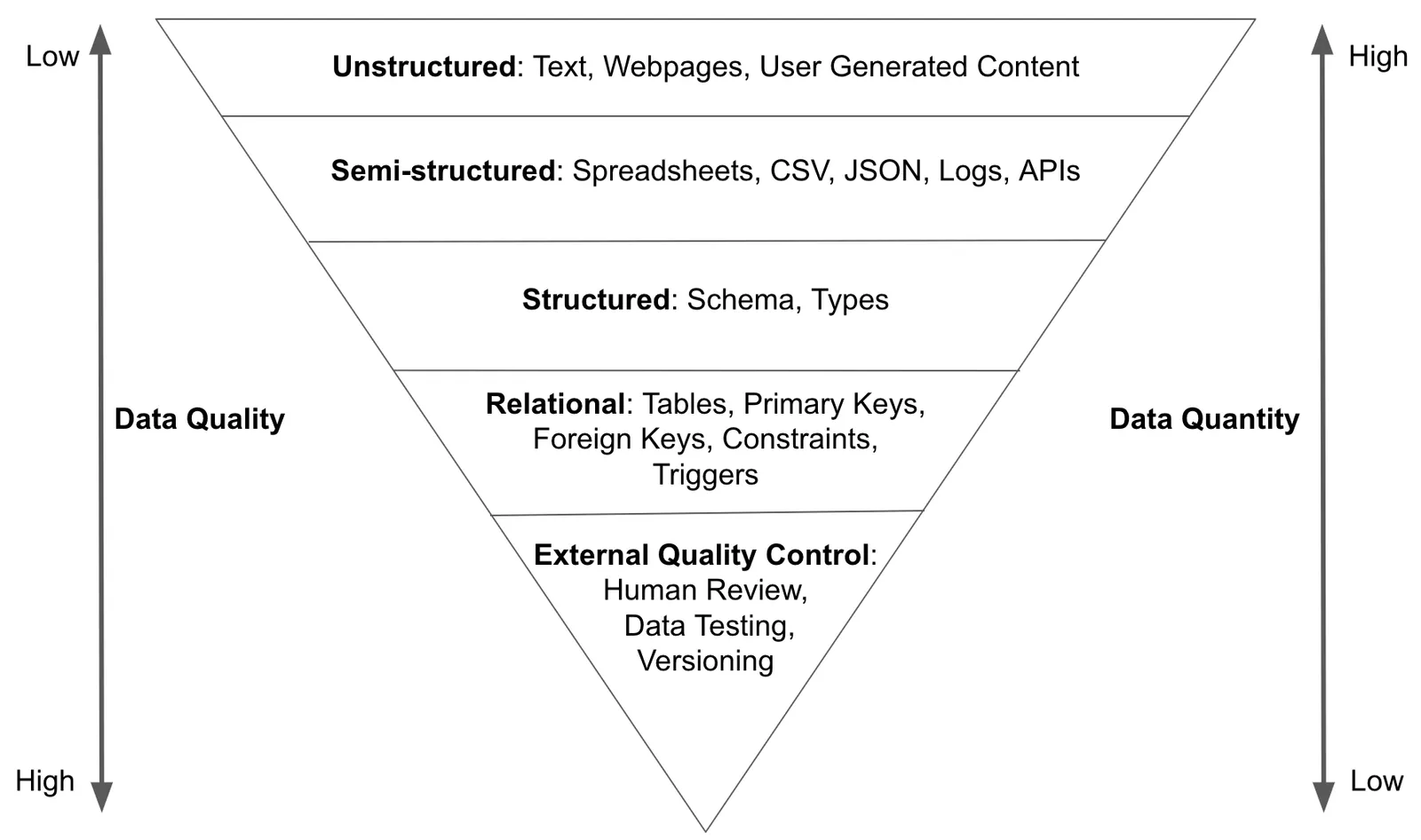
My point was that as you move down the inverted pyramid, additional constraints on the data, usually in the form of schema, produce higher quality data. SQL forces data quality on write.
Now, SQL has even better tools to ensure data quality now that version control exists in SQL. Pull requests on your SQL database changes? Yes, please.
Conclusion#
SQL has been around for 50 years and will likely last another 50. We’re finally out from under the yoke of Oracle. SQL is easy to understand and powerful. It is the standard. Want to discuss? Come by our Discord and let us know your SQL opinions.