
Here at DoltHub we just launched versioned MySQL replication. Dolt is a version controlled database and you can now replicate to Dolt from your production MySQL.
This new Dolt deployment mode has it competing in a new product category, Change Data Capture. This article will explain what Change Data Capture is, how it works, and why you would use it. Finally, the article will highlight the open source products in the space.
Dolt isn’t exactly Change Data Capture by its most specific definition, but it works similarly. And since using Dolt as a MySQL replica serves some of the same use cases normally associated with Change Data Capture, we thought a comparison would be helpful.
What is Change Data Capture?#
Change Data Capture is the process of “capturing” changes made to a database, turning those changes into events, and then having those events be used as inputs to one or many other systems. To explain this process, it helps to go back in time and explain the history of how web-based software applications evolved. Change Data Capture makes a lot more sense with this context.
In my Data Quality Control opus, I explained the evolution of the Modern data stack starting at the application. Pictured below, you have the standard service oriented architecture: a client, a service, and a database.
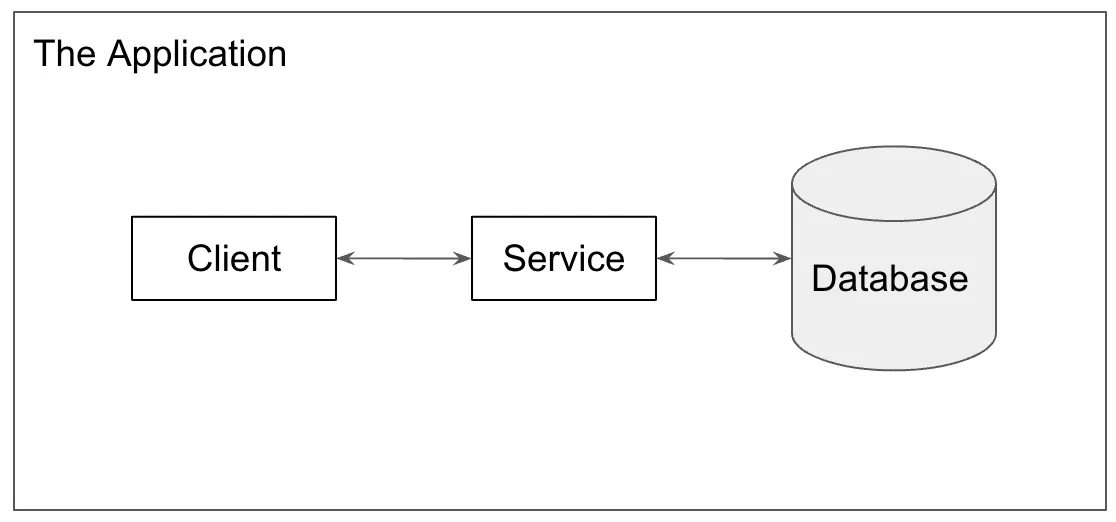
I note in the article:
This application is the source of value within your organization. It is what customers use. That also makes it the primary source of data in your organization.
I go on explaining the metrics email, client events, and how you end up with a data warehouse, culminating in a picture of the standard “modern data stack”. I highly recommend reading the article for a full picture of how we get here.
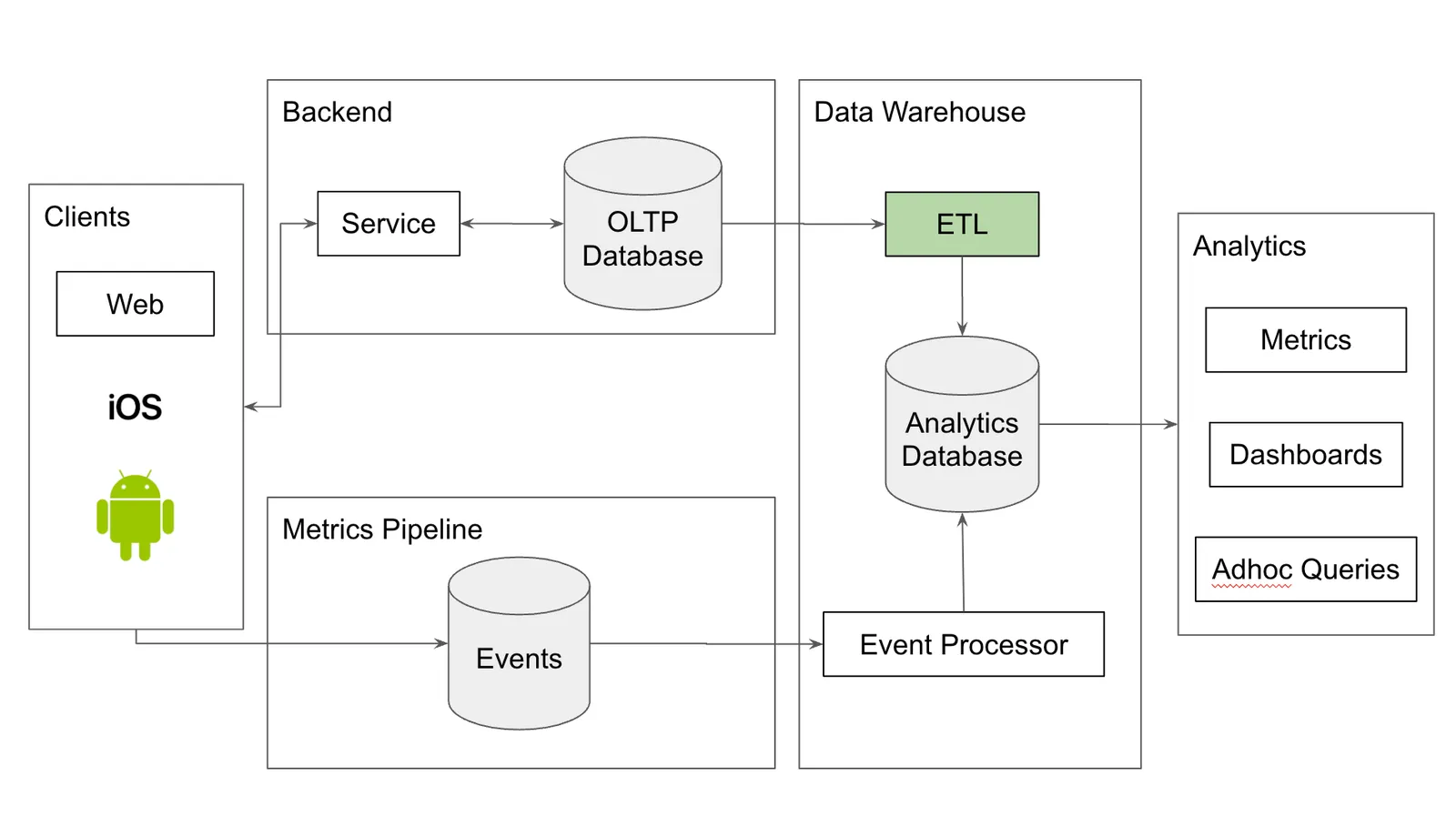
Change Data Capture is a specific instance of the ETL (Extract, Transform, Load) box. We are taking changes from our application’s production database and putting those changes into the data warehouse. Change Data Capture in this case has the added benefit of producing events, just like your client metrics, so you can model your data warehouse around events.
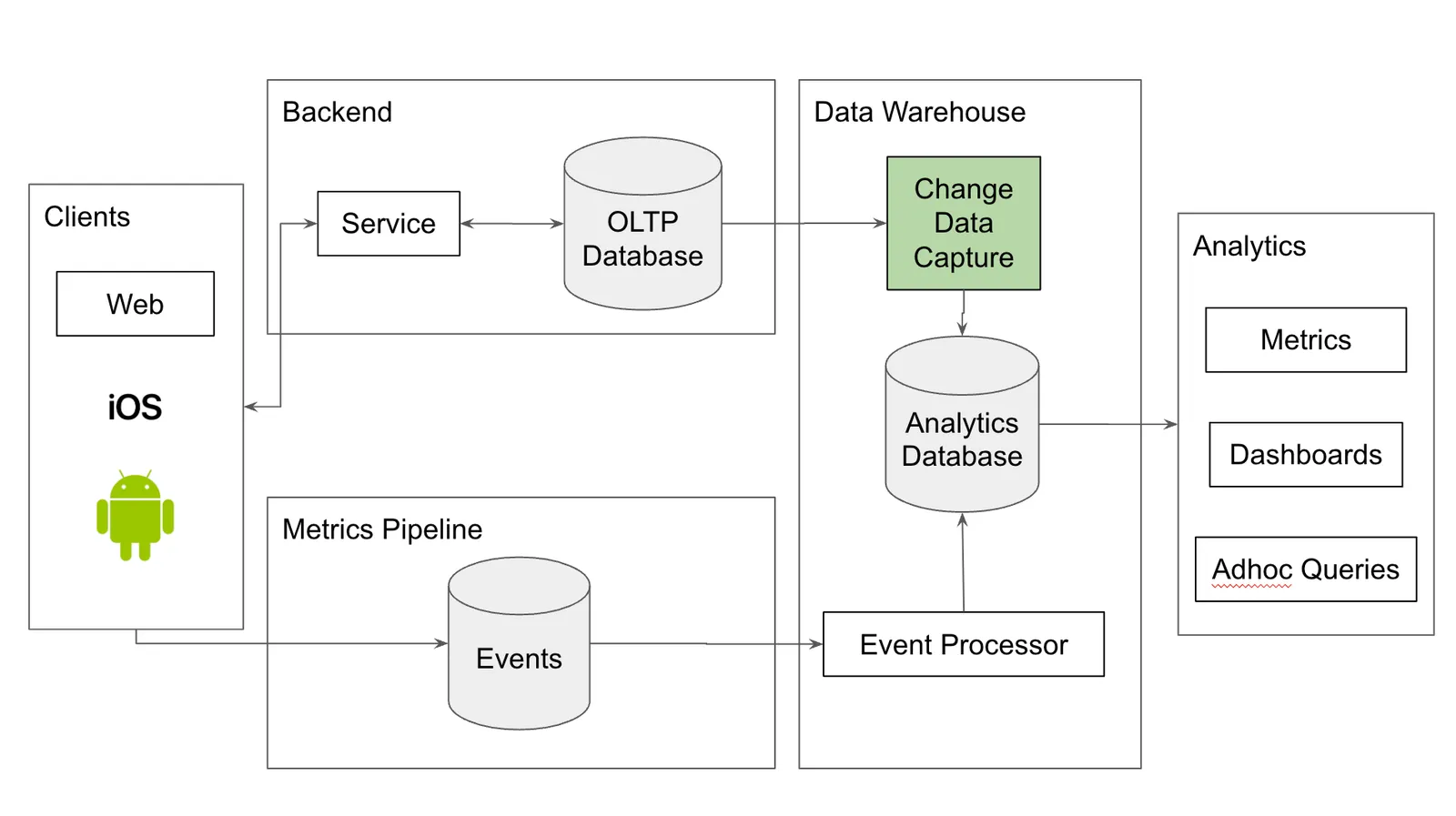
The easiest way to do ETL is to run queries on your production database, transform the data using SQL or code into the form you want, and then put the output of that process in the data warehouse. This may work for a while but eventually you will hit problems with this approach.
The first problem is the data stored in production may not be in the form you need for metrics. Your production database stores the state of the world as it looks right now. The place you are putting the data may need the history of the data, like say all accounts ever created. To get history, you must alter the schema of your production database. This is undesirable for a number of reasons. You need to make a cumbersome database schema change. Your schema is more complicated after the change. You now have a bigger production database that records history.
The second problem is scaling. ETL queries tend to get expensive very quickly especially if you make schema changes to record history. Think full table scans with multiple joins. Maybe you have a dedicated database replica that serves the ETL jobs to protect the production database from getting overloaded. That works for a while but eventually the queries just take too long too run. You need another answer.
In order to get around these problems you need a way to scalably capture changes made to production and produce an event stream of these changes for another system to consume. This is Change Data Capture. Moreover, once we solved those problems, we found other uses for that event stream outside of the data warehouse, making Change Data Capture a general tool.
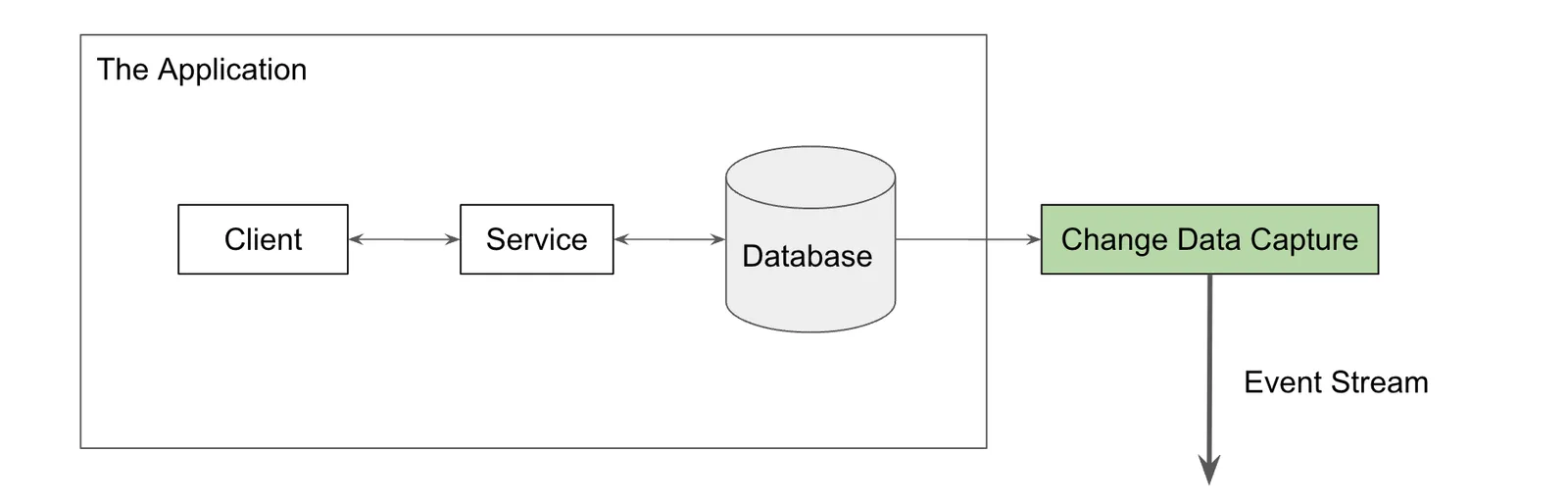
How does Change Data Capture Work?#
Deprecated Approaches#
In some highly ranked Change Data Capture articles, altering the schema of your production database to record a “last updated” column or create a trigger to maintain an “change” table and having a standard query-based ETL job consume these is considered Change Data Capture. Maybe historically this was the case? But the term Change Data Capture now implies not altering the production database schema to capture changes. We have better technology now!
Log Based#
Most modern production OLTP databases have code to create one or many replicas. Replicas are used for scaling and redundancy. The primary database produces a log of all write transactions to be consumed by replicas. In MySQL this is called the binlog and in Postgres this is called the wal (write ahead log).
Modern Change Data Capture systems also consume this log from your production database. The Change Data Capture system accesses the logs of your production database and produces a stream of change events that can be consumed by other systems, like your ETL job that puts data in your data warehouse.
Why do you need Change Data Capture?#
Analytics#
As we noted earlier, the reason Change Data Capture was invented was to efficiently get data into the data warehouse. The data warehouse is primarily used for analytics. How many customers signed up yesterday? What are the applications monthly active users? These are questions answered by the data warehouse.
Audit#
A more specific use case of analytics is audit. As noted earlier, the production database generally stores the state of the world now. What if Finance needs you to guarantee that the inputs to a number they are reporting hasn’t been altered. You need to produce a (hopefully empty) audit log of all the times the inputs to that number have changed. Change Data Capture can produce these audit logs.
Quality Assurance#
Now that you have a stream of what’s changing in your database, you can inspect that stream to make sure only things you want to change are changing. You can implement data quality control on the events being produced by Change Data Capture.
Search/Machine Learning#
The event stream produced by Change Data Capture has other uses. If you have search indexes that must remain in sync with source data, streaming updates to the index is a better pattern than rebuilding the whole index on a schedule. Similarly, streaming updates to your training data for Machine Learning models can be better than producing training sets on a schedule.
Lower Costs at High Scale#
Change Data Capture is just a more efficient way to get changes out of your production database. Often even if you’ve satisfied the above use cases in some other way, you’ll want to migrate to a Change Data Capture system to save time and money. Change Data Capture obviates the need for some expensive, long running queries on your production database.
Products#
Now, on to the Change Data Capture products. As usual, in the So You Want… articles, I focus on open source tools. If you’re in the market for closed source solutions, contact the sales teams of Fivetran, Talend, Striim, or Gathr.

Airbyte#
- Tagline
- Data integration platform for ELT pipelines from APIs, databases & files to warehouses & lakes
- Initial Release
- September 2020
- GitHub
- https://github.com/airbytehq/airbyte
Airbyte does Change Data Capture but it is more of a generic “data mover”. You configure a connector to a source like your production database. There is a pluggable workflow engine in the middle to do transformation. The workflow engine outputs data in a specific form to your destination connector. Change Data Capture happens if your configure it in the source connector.
The workflow engine uses DBT, a popular data transformation language that I wrote about in my Data Quality Control opus.
On the downside, I had a bit of trouble parsing through their documentation. There’s a lot of it which is good but it’s not particularly well organized. Airbyte is new and well funded. This company is doing great and I expect improvements in their documentation soon.
If you’re looking for a generic, pluggable solution ETL solution that also does Change Data Capture, give Airbyte a try.
Debezium#
- Tagline
- Change data capture for a variety of databases
- Initial Release
- March 2016
- GitHub
- https://github.com/debezium/debezium
Debezium, sponsored by RedHat, is the open source Change Data Capture specialist. In standard form you use the appropriate Debezium connector for your production database. The Debezium connector generates the same style event stream for every database. The event stream is stored in an Apache Kafka queue. Event consumers read off the Kafka queue.
Debezium also has a server mode and an embedded mode if you don’t want to run Kafka.
On the downside, if this is a downside, Debezium is very specific. Debezium does one thing very well. It turns your binlog or wal into an event stream. You’ll need to run other infrastructure if you go with Debezium.
Debezium is the open source Change Data Capture standard and it’s supported by the largest open source company in the world. If you are looking for a specific open source tool to solve Change Data Capture, Debezium is it.
Dolt#
- Tagline
- It's Git for Data
- Initial Release
- August 2019
- GitHub
- https://github.com/dolthub/dolt
Dolt is the world’s first version controlled SQL database. Dolt is MySQL flavored. Engineers have adopted Change Data Capture to get version control capabilities like audit and data quality control to their MySQL deployments. Maintaining a Dolt replica of your production MySQL instance may be a better way to get these features.
Using Dolt as a MySQL replica isn’t a Change Data Capture by the traditional definition. Dolt does not a produce an event stream. However, Dolt does consume the MySQL binlog. Dolt creates commits after every SQL transaction, allowing you to produce an event stream using SQL against the dolt_diff_<table> system tables. The diffs are persisted indefinitely allowing event consumers to “catch up” from any commit in the past.
The advantage of using Dolt over something like Airbyte or Debezium is that the Dolt replica has the same schema as your production database. In essence, a Dolt replica is production with additional features. It can even serve production traffic. This give you additional audit and quality guarantees that traditional Change Data Capture cannot. With traditional Change Data Capture solutions, you have to worry about bugs getting in the Change Data Capture process itself.
Obviously, we’re a little biased but we think Dolt is an interesting new tool for MySQL Change Data Capture. Want to discuss? Come talk to us on Discord.