
Dolt Binlog Replication Preview#
Today, we are excited to announce Dolt’s support for replicating from a MySQL binlog! This initial support allows a Dolt sql-server to configure a MySQL or MariaDB instance as its replication source, connect to it, and receive binlog events.
Binlog replication is a popular and battle-tested feature of MySQL that’s been around for over two decades. Replication was originally introduced in MySQL 3.23.15 waaaay back in May 2000. Since then, it’s evolved into an extremely powerful, stable, and widely used feature. It is frequently used for high availability, disaster recovery, and read scale out, as well as many other uses. MySQL estimates that the vast majority of production MySQL systems are using binlog replication for one or more of those goals!
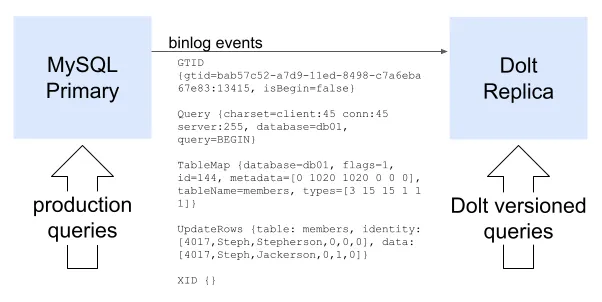
We’re excited about this new replication mode because it enables customers with an existing MySQL or MariaDB instance to easily add Dolt into their system, without adding risk to the production system. It’s also a nice addition to the two existing forms of replication that work between a Dolt primary and Dolt replicas (remote-based replication and direct-to-standby replication).
We still recommend running Dolt as your primary database to get the best experience and to get the most out of Dolt’s data versioning, diffing, branching, and merging features. However, we also understand that it’s kinda sorta a BIG deal to migrate your company’s database. We hope this feature provides an easy on ramp for people to try out Dolt in their environment and see if Dolt’s data versioning features can help them.
Let’s take a look at an example of setting up and using Dolt as a binlog replica…
Demo#
I’ve got a MySQL primary server that is running the prod environment for this demo. We could of course set this up with a non-production system to test, too, but it’s worth noting that the replication configuration process is safe to use on a running, production system. There’s also a simple load generator creating read/write traffic on that primary database. This demo will show how we can add a Dolt binlog replica to this system, and then how we can use Dolt’s data versioning features on the replica to analyze and even repair our data.
Validate the Source Server’s Settings#
The first thing we need to do is make sure our source server is configured with all the needed settings:
GTID_MODEandENFORCE_GTID_CONSISTENCYboth need to be set toON. These are not on by default in the standard MySQL 8.0 install, so it’s likely you will need to turn these on if you haven’t already. MySQL provides an excellent walkthrough for enabling these system variables.BINLOG_FORMATmust be set toROW, which is the default in MySQL 8.0.LOG_BINmust be set toON, which is the default in MySQL 8.0.SERVER_IDmust be set to any positive integer (so long as there is not a replica server using that same ID).
You can check your configuration by running the query below:
SHOW VARIABLES WHERE Variable_Name LIKE '%gtid_mode' OR Variable_Name LIKE '%enforce_gtid_consistency' OR Variable_Name LIKE '%binlog_format' OR Variable_Name LIKE 'log_bin' OR Variable_Name LIKE 'server_id';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| binlog_format | ROW |
| enforce_gtid_consistency | ON |
| gtid_mode | ON |
| log_bin | ON |
| server_id | 42 |
+--------------------------+-------+Good news everyone! Our MySQL primary server is already running with the binlog and GTID settings we need, so we’re ready to warm up our replica next.
Warm the Replica#
After we’ve validated that our source MySQL server has all the settings we need, we can move on to warming our replica. This step loads an initial schema and data set onto our replica and gets the replica into a state where it can consume binlog replication events to finish synchronization and then stay in sync with the primary.
First, we need to export our data from our MySQL source server using the mysqldump command. Make sure you specify all the databases you want to export as part of the --databases flag and note that the --single-transaction flag is key for making this safe to use on a production system taking traffic.
mysqldump -uroot --single-transaction --protocol TCP --port 54322 --databases db01 > mysql_dump.sqlAfter we copy that mysql_dump.sql file to our new Dolt replica, we start up the Dolt sql-server on the replica and load in our data. Note: make sure to load the dump into a running Dolt sql-server, and not just into dolt sql, since some in-memory system variables (e.g. GTID_PURGED) are set as part of loading the dump and those values will be needed to start replication at the correct point.
dolt sql-server -uroot --port 11223
mysql -uroot --protocol TCP --port 11223 < mysql_dump.sqlStart Replication#
All that’s left now is to configure our Dolt sql-server to connect to our MySQL primary and start replication:
SET @@GLOBAL.SERVER_ID=42;
CHANGE REPLICATION SOURCE TO SOURCE_HOST='localhost', SOURCE_USER='root', SOURCE_PASSWORD='super-secret-pword', SOURCE_PORT=3306;
START REPLICA;
SHOW REPLICA STATUS \GPresto! Our Dolt replica is aware of the last GTID included in the mysqldump, so it automatically syncs to the right position in the binlog event stream and starts applying the next updates.
Using Dolt Features#
Now that our Dolt replica has been running and receiving changes from our MySQL primary for a while, we’ll have some versioned history created on our Dolt replica. Even though our MySQL primary has no concept of Dolt commits, the Dolt replica will automatically create Dolt commits for each transaction it processes, giving us a commit history we can audit.
Let’s look at a couple ways we can use Dolt’s data versioning features…
Data Change Analysis#
In this first scenario, we’re going to analyze how our data has changed. This is a great use case for a replica, because you can safely execute longer running or expensive analytic queries on the replica, without worrying about impacting production.
For example, let’s say we want to better understand how our customers are using our app. In our app, each member can enable or disable various features; for example, a customer may want to opt out of our app’s new UI redesign and stick with the old UI. We can use Dolt’s built-in system tables, functions, and procedures to drill into how the data is changing.
Let’s say we want to understand which features are popular and which are not popular. We can query the dolt_diff_<tablename> system table to see how each individual Dolt commit changed the rows in our table. This system table exists for every user table in our database, and it shows us exactly how each row in a table changed at each Dolt commit. In the following query, we’re looking at three features and counting how many distinct users had each feature enabled, and then turned it off.
select
(select count(distinct to_pk) from dolt_diff_members where from_feature_a=1 and to_feature_a=0) as feature_a_attrition,
(select count(distinct to_pk) from dolt_diff_members where from_feature_b=1 and to_feature_b=0) as feature_b_attrition,
(select count(distinct to_pk) from dolt_diff_members where from_feature_c=1 and to_feature_c=0) as feature_b_attrition;
+---------------------+---------------------+---------------------+
| feature_a_attrition | feature_b_attrition | feature_b_attrition |
+---------------------+---------------------+---------------------+
| 24 | 90 | 1 |
+---------------------+---------------------+---------------------+Looking at those results… it looks like we have a problem with feature_b. Ninety customers tried it out and then turned it off! We could keep digging in deeper to see how long customers left it enabled, if any ever turned it back on, and who these customers are to follow up with them for feedback.
Data Recovery#
Uh oh! A bug in our data generator has deleted all the data in one of our tables! 🚨
select * from version_sets;
Empty set (0.00 sec)Fortunately, our Dolt replica has been diligently recording our data’s history, so we can search the Dolt commit history to find exactly when the data was deleted. We’re going to use the dolt_diff_<tablename> system table again, because it provides a nice view of exactly how our rows changed for every Dolt commit that affected the table. We’re using the diff_type field to filter to commits that deleted rows, and we’re doing a simple group by to count how many rows each commit deleted.
select to_commit, count(from_pk) from dolt_diff_version_sets where diff_type = 'removed' group by to_commit;
+----------------------------------+----------------+
| to_commit | count(from_pk) |
+----------------------------------+----------------+
| t11cec2ld53hsbtd5hldhas43j1d99dn | 601 |
+----------------------------------+----------------+The results show that only one commit deleted records, and it deleted 601 entries. Now that we know the commit hash, we can get our data back! If we were running Dolt as our primary database, this would be as simple as calling dolt_revert('t11cec2ld53hsbtd5hldhas43j1d99dn'). In this case though, we need to create a SQL patch that we can apply to our MySQL primary. We can do this easily on the command line with the dolt diff command by passing -r sql to specify that we want our results in a SQL patch format. We specify the commit that changed our data first, then use the ~ ancestor syntax to diff that first commit against the previous commit, essentially going backwards to revert the deletes.
dolt diff -r sql t11cec2ld53hsbtd5hldhas43j1d99dn t11cec2ld53hsbtd5hldhas43j1d99dn~ > patch.sqlFrom there, we can take that patch file and run it against our MySQL primary to get our data back:
mysql -uroot --protocol TCP --port 3306 db01 < patch.sqlAnd voila! Our data is restored! After we verify that our app is working correctly in production, we can use the replica to verify that the data was restored there, too. Simply querying the count for the rows in our table gives us a rough idea that things are back to normal, but we can use Dolt’s diff features to test much more deeply. To inspect and compare the data cell-by-cell, we can use the dolt_diff() table function to show that there are no differences to our table between the last revision before the data was deleted and the current revision:
select count(*) as count from version_sets;
+-------+
| count |
+-------+
| 601 |
+-------+
select * from dolt_diff('t11cec2ld53hsbtd5hldhas43j1d99dn~', 'HEAD', 'version_sets');
Empty set (0.00 sec)Current Limitations#
We’ve kept the scope lean to get out this first release of MySQL binlog replication for Dolt. That means there are a few notable limitations that we’ll be following up with shortly. If you want to try out Dolt’s support for binlog replication, but one of those is a blocker, just shoot us an issue on GitHub or drop by Discord and let us know. We prioritize our work based on what we hear our customers need, so your feedback would be greatly appreciated. 🙏
Summary#
We’re really excited about what customers can do with Dolt’s binlog replication support. We hope it’ll help more customers, more easily take advantage of Dolt’s data versioning features, without requiring a large upfront investment to fully migrate to a new database management system.
We’re looking for help testing out this new feature! If you run a MySQL or MariaDB server and have time to try this out, we’d love to hear how it goes. Cut us an issue on GitHub or drop by our Discord server and come chat with us. If you have questions, feedback, or hit any snags at all, we’d love to hear about it so we can improve documentation, squash bugs, and prioritize our roadmap.