
Data diff is a really crowded category with multiple interpretations and products. When you say “data diff”, what do you mean? What are your tool options for accomplishing data diff?
We here at DoltHub built the world’s first version controlled SQL database, Dolt. Dolt provides extremely fast, cell-based diff capabilities on schema and data. Fast diff provides the basis for other version control functionality like merge, lineage, and revert. We’re kind of data diff experts so let us take you on a guided tour of the space.

What is a Diff?#
“Diff” is short for difference. The word “diff” entered the software developer lexicon because of the eponymous unix tool, developed in the early 1970s, used to compute a line by line difference between two files. diff is still on my Mac.
$ cat file1
This
is
some
text
$ cat file2
This
is
other
text
$ diff file1 file2
3c3
< some
---
> other“Diff” is a computer program that produces a human-readable set of differences between two inputs. As inputs become very large, it can become computationally expensive to compute differences naively. It also becomes challenging to display differences in a human readable way.
What is data?#
But what about data? This is where things get a little more complicated.
If your data is stored in a flat text file, like is common in comma separated value (CSV) files, you can use traditional diff to calculate the line-based difference between the two files. If you have two CSVs and you would like to know which rows are different, traditional line-based diff may be able to do that for you. But what if you randomly sort the CSV? This is the same data but the differences will likely be the whole file. In order for line-based diff to produce the right results, data in CSVs must be sorted in the same way each time. The word “data” implies that order doesn’t matter when computing a diff.
Moreover, what if your CSV has 10,000 columns in each row? Even the line based difference of a sorted CSV may not help you figure out what is different, you might need a different tool.
With data you might have a schema: which values are allowed in which columns. You may want to know what changed in the schema between two versions of the data.
With all this in mind, when people refer to data diff they usually are referring to structured data stored in a computer program or database.
Data stored in objects#
Let’s start with data stored in objects in a computer program. Most computer languages have a library to produce a difference between data stored as objects. Here are some examples.
That’s not really why I wrote this article though. I was thinking about data stored in databases.
Data stored in a database#
But what about data stored in databases like MySQL, Postgres or SQLite? In databases, you may want to see the difference between the schema and/or the data.
Schema is often small and a line-based diff of two SHOW CREATE TABLE statements is often enough. Here’s an example of this approach from Dolt. It’s easy to read. Looks like column c1 was changed from int to float, column c3 was dropped and column c4 was added.
$ dolt diff
diff --dolt a/t b/t
--- a/t @ vicfc0a3gvda28fecv4l2ol9v89hd768
+++ b/t @ 1fikaq8vs45d1msjlmutg3vmirafef3b
CREATE TABLE `t` (
`pk` int NOT NULL,
- `c1` int,
+ `c1` float,
`c2` varchar(255),
- `c3` json,
+ `c4` int,
PRIMARY KEY (`pk`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_bin;Data is where things get tricky. Data is often very large, making it computationally expensive to compute differences between two versions. This is why, generally, this functionality is not available in core database offerings. Luckily, there are a number of tools that do data diff which we’ll cover in this article.
Data diffs take two forms both using keys to compute differences. The first is something that approximates a line-based diff.
$ dolt diff
diff --dolt a/t b/t
--- a/t @ 1ri5jdqdtlu6t4cujpat057b3mm7l8e1
+++ b/t @ pnm8s04g4kk952o3qhrtms6lcaknsucp
+---+----+-------+------+----+
| | pk | c1 | c2 | c4 |
+---+----+-------+------+----+
| < | 1 | 1.1 | bar | 1 |
| > | 1 | 3.14 | bar | 1 |
| - | 2 | 3.4 | zap | 2 |
| + | 3 | 5.678 | boom | 9 |
+---+----+-------+------+----+There is also a SQL patch oriented diff that can be used to apply the changes to another database with the same schema. Here is the SQL patch for the diff above.
$ dolt diff -r sql
UPDATE `t` SET `c1`=3.14 WHERE `pk`=1;
DELETE FROM `t` WHERE `pk`=2;
INSERT INTO `t` (`pk`,`c1`,`c2`,`c4`) VALUES (3,5.678,'boom',9);Why is data diff important?#
Now that you understand what data diff is, the question is why would you ever need it? I’ll focus on three key reasons to use data diff.
- Disaster Recovery
- Improved Data Quality
- Speed of Development
Disaster Recovery#
Let’s say someone accidentally deleted a few key records in your database. You could restore from a backup, which is often a time consuming operation. More importantly any additional writes after the backup was taken will also be destroyed. This ia a bad situation if you find yourself in it. You must find out which records were deleted and restore them. In this case, you can use a data diff tool to compute the differences between your backup copy and the current version to filter to a smaller set of records from which to consider restoring from. Data diff can shorten recovery time in this case.
Improved Data Quality#
Data is often ingested into a database in bulk, for example, from a backup or dump. It can be very useful to compute the differences between the old copy and the new copy when ingesting data to perform quality control on the differences. Expecting only a few records to change but millions changed? It’s time for some additional quality assurance before that data gets into production.
Speed of Development#
Often when developing complex queries or update jobs, you may not get updates right the first time. Data diff can speed up the process of building these queries or jobs because you can quickly see the output of your job in a human-readable way. Data diff makes database development faster, just like code diff for normal software development.
Products#
There are a number of products that provide data diff functionality. I picked the most popular ones and divided them into the implementation specific (ie. they only work for one type of database), implementation agnostic, and version controlled database categories.

Implementation Specific#
These database implementation specific products tend to be more community supported. If you are looking for a bespoke product for a specific database implementation check these out.
Postgres Compare (Postgres)#
- Tagline
- The schema and data comparison tool for PostgreSQLThe schema and data comparison tool for PostgreSQL
- Initial Release
- June 2016
- GitHub
- Not open source
Postgres Compare is not open source but there is a free trial. It seems to be maintained by a single maintainer, Neil Anderson, which is very cool. I went off Twitter account creation date for release date.
Postgres Compare creates diffs for schema and data and provides a graphical user interface (GUI). It’s unclear from the marketing documentation which diff algorithms are used. I’m not sure how fast or scalable it is. The product seems to have good reviews. If you are looking for a paid option tom diff two Postgres databases, check it out. Try it for free first, obviously.
DB Diff (MySQL)#
- Tagline
- Automated database schema and data diff tool
- Initial Release
- November 2020
- GitHub
- https://github.com/DBDiff/DBDiff
DB Diff is open source. There seems to be no supporting company but the project does accept sponsors.
DBDiff is a command line tool. The tool seems fairly configurable. The diffs it creates are in SQL patch form. It performs a linear scan so it’s going to get pretty slow for large databases. If you are looking for an open source option to diff two MySQL databases, give it a try.
SQLite Diff#
- Tagline
- Database Difference Utility
- Initial Release
- Could not determine
- GitHub
- https://github.com/sqlite/sqlite
SQLite Diff is included in the core SQLite distribution and documentation. SQLite is extremely popular boasting billions and billions of deployed copies. It’s great to see database diff supported as a first class tool in a popular database.
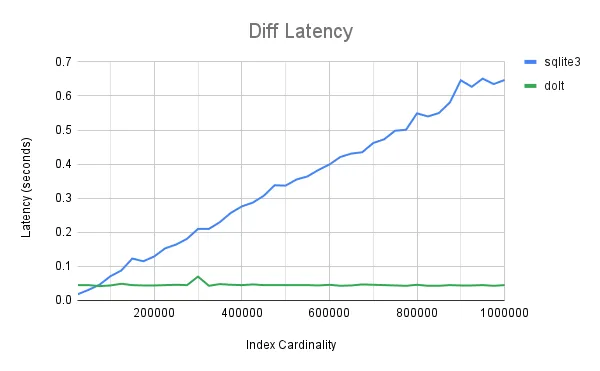
SQLite diff is a linear scan so it’s going to get pretty slow at scale. It works and we’ve tested it for performance. It is not really meant for schema diff. From the documentation it is “forgiving with respect to differing column definitions”. It’s mostly meant for data diff.
Redgate SQL Compare and Apex SQL Data Diff (SQL Server)#
There are multiple products to do data diff for SQL Server. Both products offer a compelling GIU and seem to have similar features. Neither product is open source so contact their sales team if you are interested.
Implementation Agnostic#
This is where the tools start to get interesting. These tools work with most database implementations. One is open source and the other two are proprietary.
Datafold Data Diff#
- Tagline
- Data Reliability Platform
- Initial Release
- June 2022
- GitHub
- https://github.com/datafold/data-diff
Datafold data-diff is brand new! The tool is open source. The company is well funded so I expect big things from them in the future.
Currently, Postgres, MySQL, and Snowflake are well supported with many other implementations partially supported. The supported list will surely grow over time.
data-diff uses a log(n) divide and conquer algorithm to compute differences. This algorithm leverages checksums and offsets to converge on the parts of the tables being compared that changes. data-diff works on the command line and has a very cool “verbose” and “interactive mode” to show you what’s it’s doing.
If you don’t want a GUI or a version controlled database, just data diffs of your current database, this is the tool I would recommend in the implementation agnostic space. It’s going to perform the best and is free and open source.
Datanamic and Altova Diffdog#
Datanamic and Altova Diffdog are not open source but offer a free trial. Both products seem really similar from my perspective. Both offer a GUI and CLI. Both support Oracle, SQL Server, Postgres, MySQL, and SQLite. It’s hard to tell much else from there marketing sites so contact their sales team if you are interested.
Version Controlled Databases#
Dolt#
- Tagline
- It's Git for Data
- Initial Release
- August 2019
- GitHub
- https://github.com/dolthub/dolt
Finally, we get to Dolt. Dolt is the world’s first version controlled SQL database. The core building block of version control is fast diff. Fast diff allows for other version control features like merge, revert, and cell-based lineage. Dolt diffs schema and data.
Unlike the other tools, to get data diff, you must export your data from your existing database and import it to Dolt. For this reason, most customers use Dolt as their primary database instead of another database like Postgres or MySQL. But if you do that, you get very fast diff.
If you’re looking for data diff as part of a bigger database version control feature set, check out Dolt. Questions, come hang out on our Discord.