
One of my favorite things about DoltHub is that users can navigate to any public database it hosts and run real time SQL queries against it. Where other open data sites only provide documentation about the data with a link to download ZIP or CSV files, DoltHub provides instant SQL access to the actual data. Here’s a quick example of when this feature is at its best:
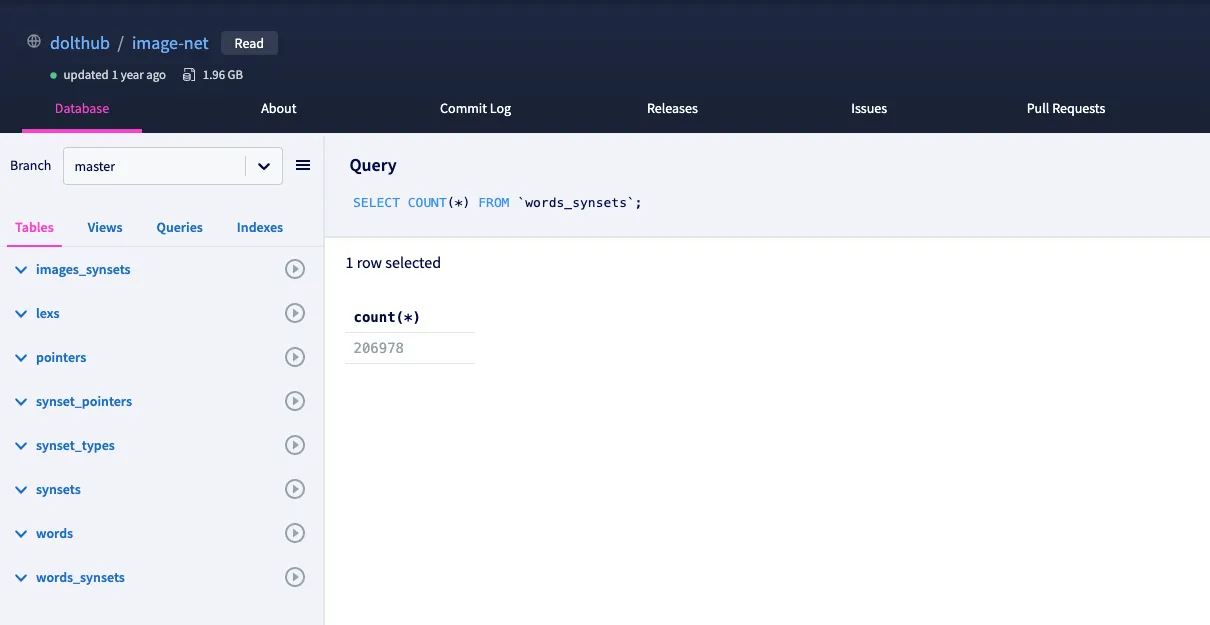
I’ve chosen a small database on DoltHub called dolthub/image-net which contains labeled images sourced from http://www.image-net.org. As you can see from the “Query” field above, I ran a COUNT(*) query on the words_synsets table which successfully returns the number of rows contained in the table. I didn’t need to download anything or set up an API, I simply browsed to the database page and ran the query.
Generally, we’ve seen that most web queries complete successfully for smaller DoltHub databases, about 1 GB in size or smaller. But with larger databases or more complex queries, it’s not uncommon to see this screen after waiting for your query results to return:
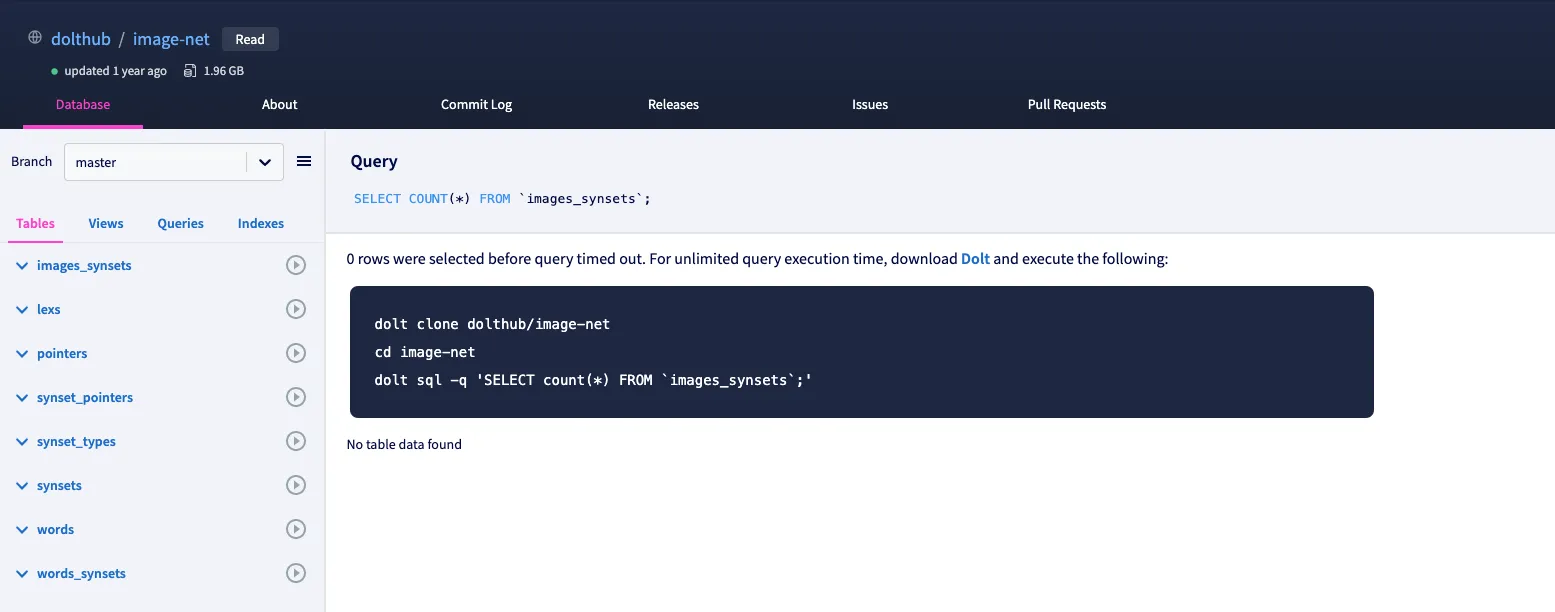
In the image above I ran a COUNT(*) query against a larger table, images_synsets, but this time the results were not returned since the request timed out before the query completed.
For most DoltHub users, this timeout may not be very impactful. As the message in the response states, a user can easily clone the database and run the query locally as a work-around. However, since the launch of Data Bounties on DoltHub earlier this year it’s becoming increasingly apparent to our team that both bounty participants and bounty administrators want to be able to do more with SQL on DoltHub without the additional cloning step.
As Dolt begins to mature as a SQL database and we continue to improve its read performance, the performance of DoltHub’s web queries will improve as well. And while we continue to make Dolt better and faster everyday, we’ve also turned our attention to finding quick optimization opportunities that we can address in the short term that will enable our users to do more, now.
We’ve been working hard to make the overall DoltHub experience a great one and as part of that work, we want to see the success rate of web queries improve. We would like to share one advancement we’ve made regarding DoltHub’s web queries that leverages a special type of compacted “table-file” we’re calling Dolt’s “manifest appendix.”
Below, I’ll provide a brief overview of Dolt’s storage implementation using “table-files”, explain how they’re referenced in Dolt’s “manifest,” and how adding a special table-file called an “appendix” is our first step of improving DoltHub’s web query performance.
Table-files
In simplified terms, Dolt stores table data in content addressed nodes of Prolly Trees and serializes those nodes in structured binary files called “table-files.”
These table-files, aptly named since they store table data, are used for both local Dolt databases and for the databases hosted on DoltHub. When using Dolt locally, table-files are stored on disk in a user’s local filesystem. On DoltHub, these files are stored in S3.
Every Dolt database uses a set of table-files that, combined, contain all data in the database. Each individual table-file contains some amount of that aggregate data, but there is no structural relationship between tables and commits in the database and individual table-files. Let’s look at an illustration to better visualize the structure.
Here’s an Example Dolt Database depicted with its underlying storage represented by three table-files. The manifest is shown as well, but we’ll touch on that momentarily.

Please note, this illustration is conceptual and obscures the technical detail and complexity involved in Dolt’s serialization process. If you’re curious, and want to read more about the technical details, see the technical implementation details outlined here.
From the image, we can see the example database is made up of three tables—tables Foo, Bar, and Baz. Each table’s data has been color-coded and is shown in the “Table Data Legend.”
There are three table-files shown in the image as well. Each table-file contains two sections, the “Chunks” section and the “Index” section.
The “Chunks” section of a table-file contains the “chunks,” or table data that has been broken up or “chunked” into smaller pieces. “Table-file 1” contains chunks from a single table, table Foo, “Table-file 2” contains chunks from tables Foo and Bar, and “Table-file 3” contains chunks from all three tables, Foo, Bar, and Baz. Chunks in the “Chunks” section are unordered and can represent any data from any table in the database.
The “Index” section, or “index,” acts as a kind of legend for all the chunks contained in the “Chunks” section of the table-file. The index maps the content addresses of the chunks present in the table-file to an offset, or location, in the “Chunks” section so that the chunk can be retrieved from the section quickly. The index is an important part of Dolt’s storage layer and it’s what enables efficient chunk lookups.
Whenever data is changed in a Dolt database, new table-files are added to the database containing the newly created chunks. To keep the number of table-files in the database manageable, table-files are periodically conjoined, which just appends the chunk sections of the respective files and builds an aggregate index. As a result, as a Dolt database grows in size, the chunks representing the table data tend to be spread across table-files in a decently indeterminate order.
The Manifest#
To successfully manage a database’s ever-changing and potentially numerous table-files, Dolt uses an interface called the “manifest.” The manifest, shown in the illustration above, is a stateful list of key-value pairs that maps each table-file in the database to the number of chunks that table-file contains. Looking at the Example Dolt Database, it’s manifest shows that “Table-file 1” contains 100 chunks, “Table-file 2” contains 200 chunks, and “Table-file 3” contains 150 chunks. If we were to insert some data into one of these three tables, we would see a new table-file with new chunks written, and a reference to it would be added to the manifest.
A database’s manifest changes anytime a user performs write operations against the database. Write operations include inserts, edits, and deletes. On the read side however, when a user wants to get or retrieve data, Dolt uses the manifest to determine the current state of the table-files, reads from them in parallel, and returns the user’s requested chunks.
The S3 Chunk Fetching Problem#
Interestingly, until now, Dolt has been agnostic about two details about its storage layer that contribute to DoltHub’s web query timeouts. The first detail is which table-file, or sets of table-files, contain which particular chunks. The second detail is the positioning of the various chunks in the “Chunks” section of each table-file.
To be fair, for the most part, this agnosticism regarding these two details has not mattered very much, especially when using Dolt locally.
Locally, the speed of a computer’s random I/O determines how quickly chunks are retrieved from a database’s table-files. This tends to be sufficiently good for modern SSDs and there’s no additional network overhead slowing down chunk retrieval when reading them from a local disk.
However, when we investigated DoltHub’s chunk retrieval, or fetching since DoltHub fetches the chunks over the HTTP, we observed suboptimal behavior that highlighted an inefficiency.
When a user runs a SQL read query on DoltHub, typically a SELECT query, DoltHub fetches the required chunks from the table-files hosted on S3, looking them up by their offset.
We observed that downloading a range of chunks from the table-files in S3 sometimes required a large number of HTTP round trips (individual HTTP transactions) in order to download just 100 MB of chunk data. Looking closer at our tracing logs we could see that a 100 MB fetch could require a very large number of round trip calls to S3 depending on the amount of data each individual round trip was able to read.
For some of the databases we measured, we were seeing round trips reading an average of 20 KBs of chunk data per trip, sometimes seeing reads as small as a single chunk, just 4 KB! This was a problem, and a definite contributor to DoltHub’s web query timeout frequency, since so much of the web query request time was spent downloading chunk data, essentially, chunk-by-chunk.
We knew that we could get better performance (and cheaper costs!) from S3 if we could convert a lot of this random I/O for chunk data into sequential I/O.
Level-Ordered Appendix Table-files#
If we trade off storage overhead and preprocessing time by storing duplicate chunks in HEAD table data, we can capitalize on S3’s sequential I/O performance boosts by creating a new table-file that has all the table data chunks stored sequentially in “level-order,” level here referring to the levels of the Prolly-Tree. This new table-file is called the “appendix.”
The appendix, like a book’s appendix, is an appendix to a database’s manifest and is simply a list of these new table-files that can be added to a DoltHub database to help reduce the frequency of some web query timeouts. Take a look at an updated illustration, depicting our Example Dolt Database that contains an appendix to the manifest.

The database still contains all the elements we’d expect, but notice there’s a new “Appendix-file 1” table-file that contains chunks from all three tables Foo, Bar, and Baz.
Unlike the main table-files “Table-file 1”, “Table-file 2”, and “Table-file 3” which each contain selections of table data, “Appendix-file 1” contains all of the chunk data from all three tables. More specifically, though, it contains all the chunks in HEAD table data but excludes chunks from system tables and chunks for previous database revisions. Compacting these chunks in a single table-file is an important part of DoltHub’s S3 fetching improvement, since they can now be retrieved from a single appendix table-file, instead of multiple main table-files.
We can also see from the illustration that the appendix table-file does not store unordered chunks in it’s “Chunks” section like the main table-files. “Appendix-file 1” stores chunks by table, in level-order. Serializing the chunks in this structured way means that when Dolt’s storage layer retrieves portions of the prolly-tree during query processing, there are many more opportunities for coalescing reads for individual chunks into large sequences of sequential I/O. This a big performance win when reading chunks from S3, since sequential I/O is much faster (and somewhat cheaper) than random I/O.
If you look at the updated manifest in the Example Dolt Database, you will see it includes an “Appendix” section that stores a reference to the new appendix table-file. This reference allows for simple management of these appendix table-files so they can be easily added and removed from various databases on DoltHub. The addition of the “Appendix” section also means that Dolt is no longer agnostic about which particular table-file it reads from when retrieving chunks. Now, Dolt biases toward reading chunks from the table-files listed in the manifest’s appendix, before it reads from the main table-files. This change in Dolt’s read behavior helps ensure that databases on DoltHub use the most read-efficient table-files available.
Appendix Limitations and Future Work#
After adding the manifest appendix to some select databases on DoltHub we were able to see a significant improvement in DoltHub’s chunk fetching efficiency. For databases using an appendix table-file, 100 MB of chunk data is retrievable in a single round trip call to S3, a vast improvement over an identical database without an appendix.
However there are some limitations to note: when appendix files are created, they contain all chunks in the database at HEAD, and are never subsequently updated. They function almost like a point-in-time static cache of the database contents. While even a stale appendix helps read performance in a lot of cases, we have to constantly update the appendix files in order to continuously provide the most efficient access patterns as the database changes.
Another limitation of the manifest appendix is that it is currently a DoltHub only feature. Local Dolt clients are unable to distinguish these files from the main table-files and for that reason appendix table-files will not be present locally when a database is cloned.
Lastly, appendices are applied to select DoltHub databases using an internal tool, so at the time of this writing appendices on DoltHub will be limited, but we are planning on adding appendices to all DoltHub databases automatically! Dolt’s manifest appendix optimization is just the first step of many to make web queries on DoltHub, and DoltHub itself, better and faster.
Curious about Dolt, DoltHub and the versioned database of the future? There’s no better place to get started than DoltHub.com where you can download Dolt, host your own public and private Dolt databases, or just clone some amazing public databases you won’t find anywhere else.
Questions, comments, or looking to start publishing your data in Dolt? Get in touch with our team here!