
Background#
While building Dolt and DoltHub, we have had many conversations with our users. They all share an interest in finding better ways to manage data. They recognize that writing code to massage CSV, JSON, and other less well known formats, into their production database is required work, but it doesn’t add value. They also recognize that data is increasingly a major component of production systems, and that it’s time to implement data management solutions that reflect this fact.
Many of our users are themselves technologists, and thus skew towards being more sophisticated. As such they often have existing relational database infrastructure. They recognize that Dolt’s version control model can be a powerful way to manage third party data they are ingesting, and that DoltHub’s pull request workflow can help humans safely update production data to meet business needs. To take advantage of these tools, however, they need to integrate with existing relational database infrastructure.
Real World Problem#
Let’s dive into a real world example, this one coming from my previous job. Prior to joining DoltHub, I worked at a quantitative hedge fund. Our team’s job was to provide infrastructure for transforming models of the world (revenue estimates, etc.) into profitable trades. This entailed lots of mapping tables. One data vendor might use a corporate entity ID to associate a value, say a revenue estimate, with a company. But that corporate entity might be associated with multiple securities. For example, Verizon has over 150 outstanding debt securities. Choosing a cost efficient way to express the view of the model in the market is a huge component of successful portfolio management.
The output of our solution to this problem was a set of mapping tables. We had many mapping tables constructed using varying degrees of complexity. Some mappings were simple 1:1 matches using a public standard identifier (CUSIP, ISIN, SEDOL, ticker, etc.). Others were approximate in nature and attempted to make a best guess. For example, when trading bonds we might attempt to select from a number of different bonds the one matching our target maturity.
These tables were frequently wrong either because the vendor provided an incorrect or mistimed value, or because of a software bug. This meant frequent manual adjustments, often resulting in missed SLAs for delivering data. Ultimately an experienced operator frequently had to intervene by making manual edits to the production database. How can we bring best practices from software engineering to such a situation?
High Level Solution#
Dolt and DoltHub provide neat solutions to this problem. New versions of mapping tales can be written to a branch, call it proposed, and then merged into master upon review. DoltHub provides webhooks such that a process can receive a notification of a push. This can be used to kick off data validation, or simply kick off a sync job to write the data to a production database. The workflow would look something like this: 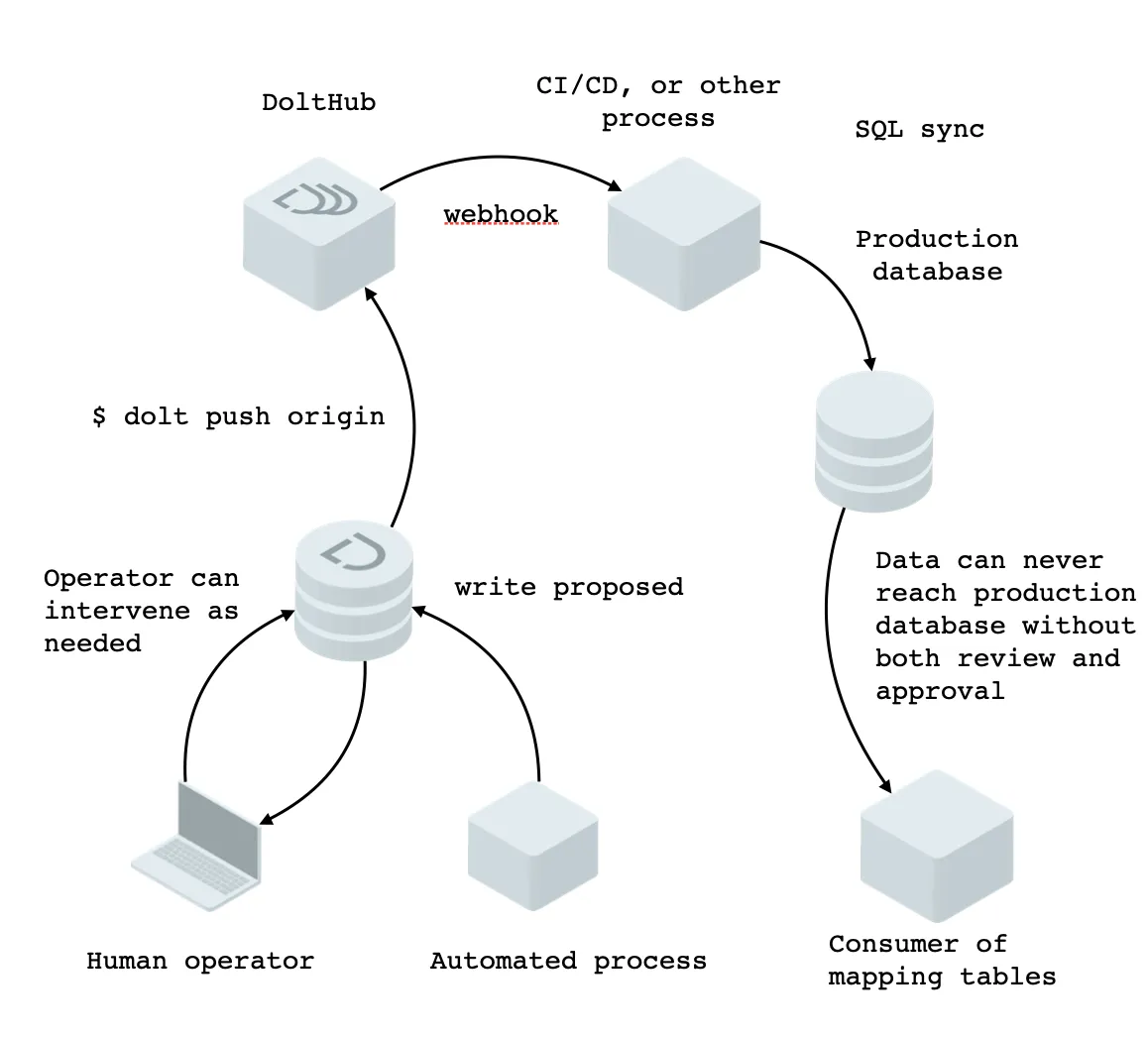
The only parts for the user to implement are the parts that concern their business logic: what to do upon being notified of a push. By filling out this business logic the user decides the criteria for successful deployment of data to their production system.
We’ve mentioned a few components to this solution. Dolt, the database and data format underpinning it all, can be found here. It’s free and open source. DoltHub is a hosting and collaboration platform that provides tools for managing Dolt data. The webhooks mentioned above are a feature of DoltHub we have blogged about previously.
The final piece is the actual code to sync Dolt to a relational database. We now detail that code, which we are releasing today.
Introducing doltpy.etl.sql_sync#
We have been developing a Python API. We call it Doltpy. It surfaces some of the basic operations of Dolt in doltpy.core, and provides ETL functionality on top of that in doltpy.etl. Our first attempt to provide tooling for syncing Dolt to existing relational databases is doltpy.etl.sql_sync. This first release allows users to sync Dolt to a MySQL server instance.
To sync the latest data from your Dolt repository to your MySQL instance, simply write the following code, filling in appropriate values for database connection and Dolt repo location:
import mysql.connector as connector
from doltpy.core import Dolt
from doltpy.etl.sql_sync import DoltSync, get_mysql_target_writer, get_dolt_source_reader, get_dolt_table_reader_diffs
mysql_conn = connector.connect(host='host', user='user', password='password', database='mydb')
dolt_repo = Dolt('/path/to/repo')
table_mapping = {'my_table': 'my_table'}
target_writer = get_mysql_target_writer(mysql_conn)
source_reader = get_source_reader(dolt_repo, get_table_reader_diffs())
dolt_to_mysql_sync = DoltSync(source_reader, target_writer, table_mapping)
dolt_to_mysql_sync.sync()We don’t expect users to make MySQL a replica of a Dolt repository. More likely Dolt and DoltHub will be tools for managing a subset of production data that requires human updates and benefits from review. Mapping tables are a great example. They often embed subjective knowledge about the world, and require manual intervention to update when automated process introduce errors. We foresee our users using Dolt and DoltHub, as well as this sync code, to ensure that the mapping tables that make it into their production database undergo a proper review and checkout process.
As a quick reminder, all this code is open source, so if you want to review before letting it loose on a production database we encourage you to head over to GitHub.
Conclusion#
We started out discussing our user’s need for Dolt and DoltHub to easily sync with existing relational database solutions. We then discussed how such syncing technology enable Dolt and DoltHub to form a solution to the real world business problem of delivering high quality versioned mapping tables into production. The solution provides automation, but also makes room for the inevitable need for human intervention. Finally we provided a code snippet of our newly released doltpy.etl.sql_sync Python package that forms the final piece of the solution.