
We think everything is better with version control. That’s why we made Dolt, the world’s first version-controlled relational database.
But version control works best when you can combine it with all the other features your database uses, and that’s why Dolt isn’t just for version control; it’s a full featured SQL database that you can use as a drop-in replacement for MySQL (and soon, Postgres). Dolt delivers on all the features you expect from a database, and then adds an extra layer of version control on top.
One of those features that’s been getting a lot of buzz recently is vector search and vector indexes. Vector indexes are a special type of index optimized for nearest-neighbor searches in vector spaces, and they’ve seen a spike in interest because of Retrieval Augmented Generation, which is a major component in LLMs and semantic search engines. In the last year, all the major SQL engines have added support for vector columns and vector indexes. And so did we.
Recently we announced that we were launching alpha support for vector indexes. We even designed a novel algorithm for building vector indexes while maintaining structural sharing, a key property of Dolt that allows for space-efficient version history storage. But we acknowledged at the time that we weren’t satisfied with its performance and were looking for ways to improve it.
That’s why we’re pleased to announce that thanks to subsequent performance optimizations, the time required to build vector indexes has decreased considerably.
This was mainly achieved by adding support for a dedicated VECTOR column type, which we previewed previously and is now available. This is a new data type optimized for storing fixed-sized arrays of floating-point values. Previously, vector indexes in Dolt required that the vectors were stored as JSON, which required an expensive deserialization step whenever the vectors needed to be used in a computation. By instead using a dedicated type, we can store vectors in a format that is much more amenable to the kinds of computations that vector indexes require.
Using VECTOR columns is easy. Before, where you might have created a vector index with a script like this:
CREATE TABLE embeddings(pk INT PRIMARY KEY, emb JSON);
INSERT INTO embeddings ...;
CREATE VECTOR INDEX v_idx ON embeddings(emb);All you have to do is replace JSON with VECTOR(N), where N is the number of dimensions in your vector. (This also allows you to validate that your vectors are the right size as you insert them!)
Our implementation matches the implementation used by MySQL and MariaDB1, meaning that databases dumped from MySQL and MariaDB can be imported into Dolt even if they contain vector columns and vector indexes.
Additionally, some changes were made to how Dolt builds vector indexes in order to reduce the number of memory allocations and the amount of memory that gets copied.
In our original announcement, I gave an example of indexing a subset of the vector embeddings from this scrape of Wikipedia. At the time, I mentioned that building an index of 14,000 768-dimensional vectors took approximately 2.5 hours on my machine (an Apple M2 Pr with 32 gigabytes of RAM).
Now, building that same index on the same machine takes approximately 2.5 minutes. This is faster than MariaDB on the same data set, which took approximately 3 minutes on my machine. Here’s a graph comparing Dolt’s new performance to MariaDB indexing variously-sized subsets:
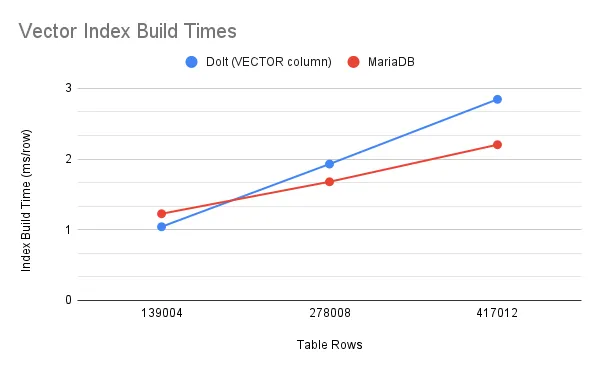
Dolt’s older performance (building vector indexes on JSON columns) isn’t included in this graphs because benchmarking it would have taken days, and it would run way off the top of the graph anyway. We weren’t proud of the performance, which is exactly why we originally launched it in alpha and why we’ve since fixed it. As you can see, the current performance is much closer to MariaDB’s.
There’s still work to do. Although building vector indexes in Dolt is now comparable to the competition, performing vector index lookups is still slower than MariaDB.
Performance is important to us. But we rely on user feedback to understand where to focus our efforts and which workflows to prioritize. If you’re using Dolt or are considering Dolt, and you find that Dolt is slower than MySQL or MariaDB for your workflow, please let us know: you can join our Discord and chat with us there. We take user requests very seriously.
We’re going to continue to work hard to make Dolt the best it can be, regardless of whether you want version control or just a good alternative to MySQL.
Footnotes#
-
MariaDB is the largest open-source implementation of the MySQL dialect. We use it here for our comparisons instead of MySQL because MySQL does not support vector indexes in the Community Edition. ↩