
At DoltHub, we’ve been at the forefront of exploring how AI agents can remodel software development, writing extensively about our experiences from collecting data with agents to how agents are reshaping the software engineering profession. Our work focuses heavily on MySQL correctness testing because Dolt, our flagship SQL database with Git-style version control, is designed as a drop-in MySQL replacement that lets you branch your database, merge changes from contributors, and maintain complete data history (learn more about database branches). This testing happens on go-mysql-server (GMS), the SQL query execution engine that powers Dolt by sitting between SQL clients and Dolt’s storage engine to handle everything from parsing to executing queries. We adopted GMS in 2020 and have been continuously developing it to ensure complete MySQL compatibility (deep dive into SQL engine anatomy).
When I first started using AI agents to test MySQL correctness on DoltHub’s GMS platform, I treated them like one crew member on my ship: I gave orders, they executed, and I waited. This delivered results, but it was painfully slow.
The bottleneck became obvious as customer GitHub issues piled up. While I waited for one agent to work through reproduction, testing, and fixes, new problems kept arriving. At first, I thought I needed a faster crew member or more crew on the same boat. But in the end, it turned out to be an entire fleet.

The Challenge of Single Agent Workflows#
With just one agent, everything happens in sequence: an issue arises, a query is tested, and a fix is proposed. In customer-facing correctness work, this sequential approach quickly becomes a bottleneck on a single system. Why not add more agents? Well, a real challenge emerges when we need multiple builds or instances of the same program running simultaneously, sometimes with conflicting configurations, within the same system context.
If we try to spawn multiple agents in the same environment, they don’t coordinate in real time. They step on each other’s toes, creating file conflicts, competing for resources, and in some cases, producing problematic hallucinations. As we discussed in Protecting against Rogue Agents, agents operating without proper isolation can cause significant damage to your development environment. Agents need clones. The insight that changed everything was realizing that agents, like developers, work best when they have their own dedicated workspace.
My Parallel Agent Setup#
The solution might sound counter-intuitive with our ship model, but each crew member needs their own “ship.” At DoltHub, we’ve developed a Docker-based containerized environment that serves as the foundation for running multiple AI agents in parallel. Each agent gets their own isolated workspace where they can’t interfere with each other, while still maintaining access to the shared resources they need to be effective.
Containerization solved our coordination nightmare. Instead of agents fighting over files and ports, each gets its own pristine environment. I can spin up, tear down, or reset containers without affecting other agents.
The Baseline Workflow#
Our development team uses a custom containerized environment for Claude Code, stored in the claude-dev-agent private repository. Credit goes to our main engineer Neil Macneale for coming up with and writing the baseline container. The Dockerfile foundation looks like this at a high level:
FROM node:20
# Install basic development tools
RUN apt update && apt install -y less \
git procps sudo fzf zsh gh tmux \
curl bats vim wget ca-certificates
# Install MySQL 8.4.5 and PostgreSQL 15
RUN apt install -y mysql-server-8.4 postgresql-15
WORKDIR /workspace
EXPOSE 3307 5433This foundation provides a standardized environment for AI agent interactions, pre-configured with essential development tools including Go, Node.js, Git, and SSH key management for agent CLI tools.
The baseline container comes with pre-cloned DoltHub Git repositories, giving agents immediate access to our core codebases. The SSH key management system allows agents to clone additional repositories as needed, maintaining security while providing flexibility. We also integrated GitHub’s CLI, enabling agents to reference issues, pull requests, and other repository information directly from their isolated environments.
What makes this setup particularly powerful is that each container starts from the same known-good state, but agents can diverge independently based on their specific tasks. One agent might install additional testing tools, another might pull different data sets, and a third might work with experimental branches.
I’ve extended this baseline container on a feature branch to add the database testing infrastructure that my MySQL correctness work demands. The enhanced version includes MySQL 8.4.5 and PostgreSQL 15 on separate ports, providing reference implementations for comparison testing. I’ve also added support for alternative Cursor Agent CLI tools, giving me flexibility in agent selection based on the specific characteristics of each issue.
This dual CLI tool support has proven invaluable in practice. As we detailed in our comparison article, each tool brings different strengths to various types of problems. Cursor’s lower cost makes it practical for running multiple agents simultaneously, making it the default. It delivers similar results at approximately 1/10th the cost of Claude Code.
Cursor also provides access to different models with distinct quirks. GPT-5 hides its reasoning but produces granular results. Sonnet-4 excels at analyzing PR branches using commands like git --no-pager diff main. I use Sonnet first for testing outlines, then GPT to clean up redundancies. This model switching adds complexity but often improves results.
Performance consistency has emerged as another critical advantage of Cursor in parallel workflows. Unlike Claude Code, which can exhibit stutters when multiple instances run over time, Cursor CLI maintains stable performance across multiple terminals, making it more reliable for sustained operations.
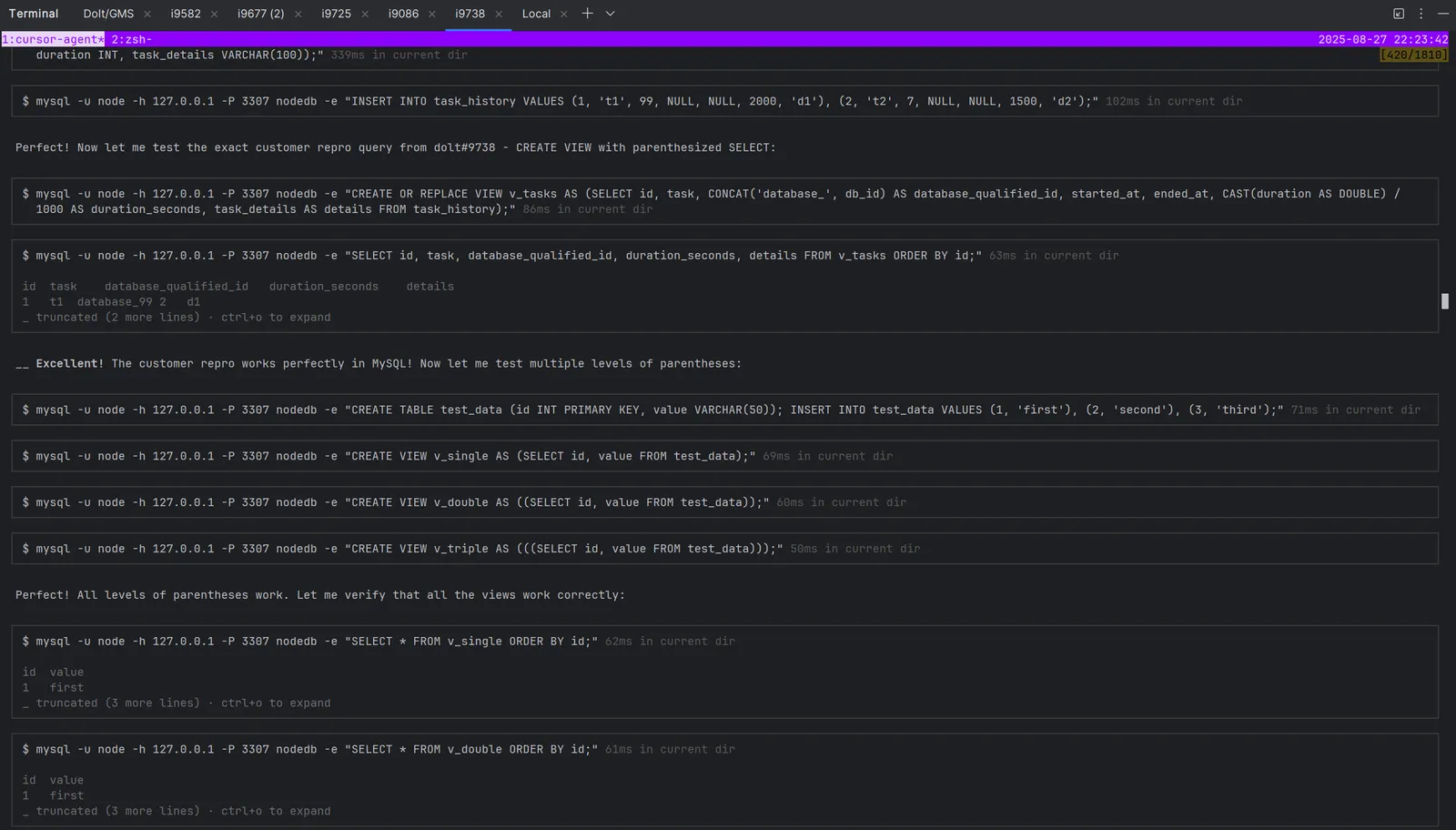
The database servers prove particularly crucial for my MySQL correctness work. Each agent can execute SQL queries against both servers for direct comparison:
# Query against MySQL 8.4.5 reference server
mysql -u node -h 127.0.0.1 -P 3307 nodedb -e "SELECT COUNT(*) FROM test_table WHERE condition = 'value';"
# Result: 42
# Same query against Dolt
dolt sql -q "SELECT COUNT(*) FROM test_table WHERE condition = 'value';"
# Result: 41 (discrepancy found!)This immediate validation prevents agents from hallucinating or abandoning tasks on incorrect reproductions.
Agent Coordination and Workflow#
Since repository files are stored directly on the system, I can intercept and modify agents’ work while they continue on separate issues. This maintains the collaborative workflow I value, but now extends across multiple concurrent problems instead of sequential processing.
My role has evolved into that of a central coordinator, managing the overall workflow by assigning specific, discrete steps to each agent. Rather than having agents tackle entire issues end-to-end, I break down the process into manageable components: reproduce the issue, add a reproduction test and ensure it fails, create the fix, and validate the fix against our reproduction test. I manually signal each agent to proceed to the next step, but otherwise avoid interrupting them during execution.
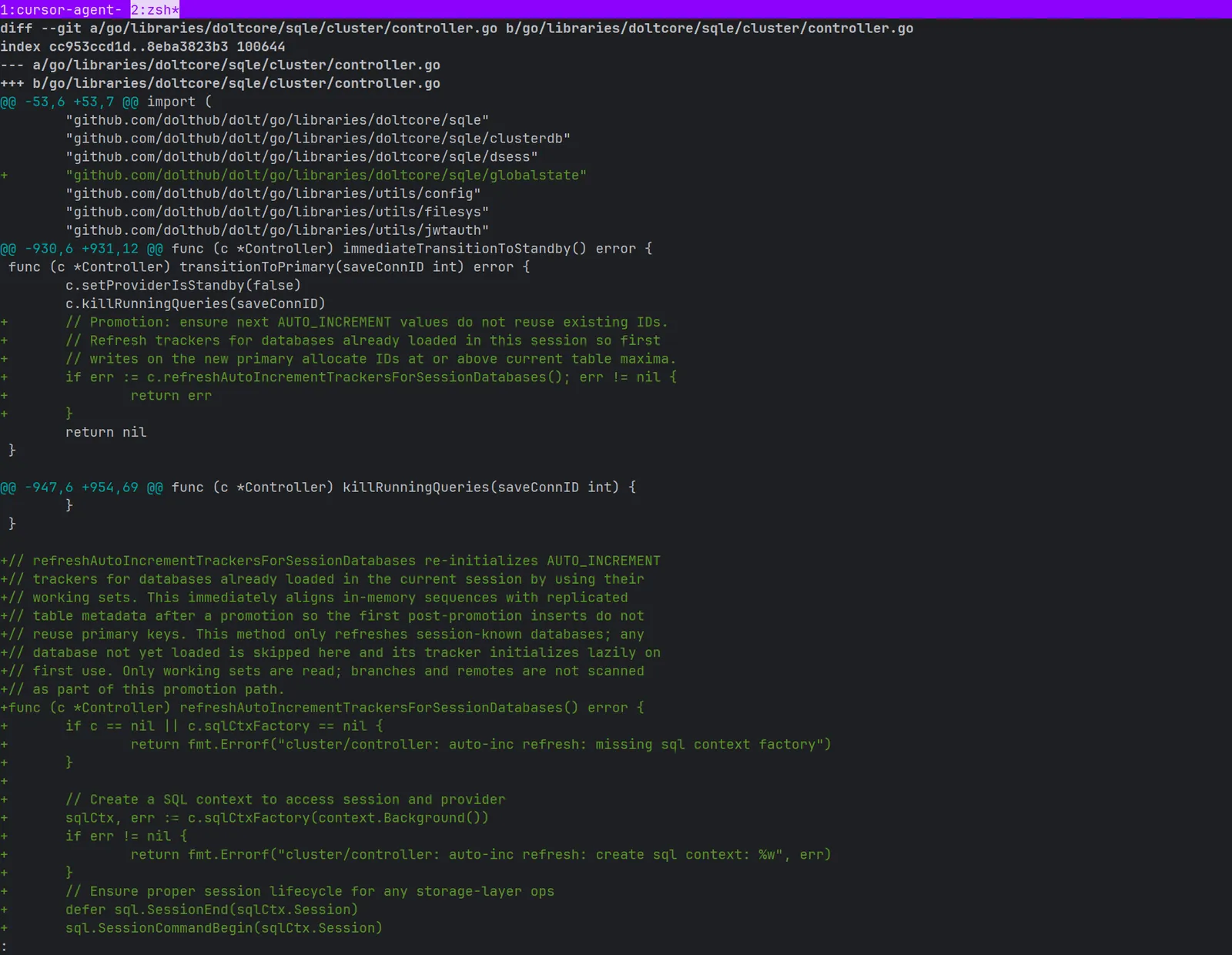
This step-by-step approach provides precise control over the workflow while maintaining agent autonomy. I can track progress across all agents by monitoring which step each one is currently executing, and redirect effort if priorities shift. Debugging is always necessary, so I instruct agents to use logrus for tracing which is kept through development.
Logrus, a structured logging library for Go that works seamlessly across both Dolt and GMS layers, provides agents with crucial information about variable states and program flow when they execute their tests. This visibility is particularly important since agents lack access to full IDEs. The logging approach discourages agents from making assumptions about program state. Instead of guessing what variables contain or how execution flows, they can observe actual execution paths and variable values in real-time.
This methodology aligns with patterns we’ve observed in our own agentic workflows and agentic data collection, where consistent feedback mechanisms enable agents to improve their performance over time. The trace statements are temporary artifacts, eventually removed once fixes are complete. This is a decision I make rather than delegating to the agents.
Our workflow embodies the prediction from The Agentic Software Engineer: software engineers becoming “code editors” who review agent-generated code rather than writing it themselves. By decomposing tasks into discrete steps with comprehensive testing infrastructure, I can review focused, validated outputs instead of monitoring every intermediate step. This separation allows me to work on multifaceted tasks while agents progress independently through their assigned targeted components.
Technical Implementation#
The technical foundation revolves around our bootstrap.sh script, which orchestrates the entire environment setup. Here’s how it works at a high level:
# Start SSH agent and add key to avoid multiple password prompts
eval "$(ssh-agent -s)"
# Start MySQL 8.4.5 on port 3307
echo "Starting MySQL server on port 3307..."
sudo service mysql start
# Start PostgreSQL 15 on port 5433
echo "Starting PostgreSQL server on port 5433..."
sudo service postgresql start
# Clone core repositories
git clone git@github.com:dolthub/dolt.git
git clone git@github.com:dolthub/go-mysql-server.git
git clone git@github.com:dolthub/lambdabats.git
# Install pre-push hooks
cd dolt && git config core.hooksPath .githooksThe script handles SSH key management, starts database servers, clones core repositories, and installs pre-push hooks that prevent agents from accidentally pushing to main branches. It then launches the specified CLI tool based on the CLI_TOOL environment variable and automatically attaches to a tmux session.
The tmux integration is important for managing agents’ sessions effectively. Each agent operates within its own tmux session named “agent.” Here’s the tmux configuration:
# tmux.conf
unbind C-b
set -g prefix C-a
set -g base-index 1
set -g status-position top
set -g status-style 'bg=#8c03fc fg=#e8d5f7'When I exit a tmux session, the container continues running in the background, and I can reconnect with:
docker exec -it $HOSTNAME tmux attach -t agentThis persistence eliminates the frustration of losing agent context during longer development sessions.
Each container automatically creates a comprehensive CLAUDE.md reference file with common commands, testing procedures, and development guidelines:
# Auto-generated in bootstrap.sh
cat > CLAUDE.md << EOF
# Development Reference
## Project Structure
- /dolt - Main database repository
- /go-mysql-server - SQL engine
- /lambdabats - Test framework
## Testing Commands
- Run specific test: go test -run TestName
- Integration tests: bats integration-tests/bats/sql.bats
EOFLessons from the Trenches#
After a month with multiple agents, I learned what works and what doesn’t. I’d launch agents only to watch them take forever to fix issues or, worse, break things because my instructions were too ambiguous about which tools to use. Without proper testing infrastructure, parallel agents become parallel sources of confusion rather than productivity multipliers.
Testing infrastructure is everything. Dolt’s codebase makes this easy. When results don’t match between MySQL and Dolt, agents can run the MySQL server to see exactly what’s different. When agents need extra tools, I install them with docker exec commands. This lets agents request exactly what they need without worrying about messing up other agents’ environments.
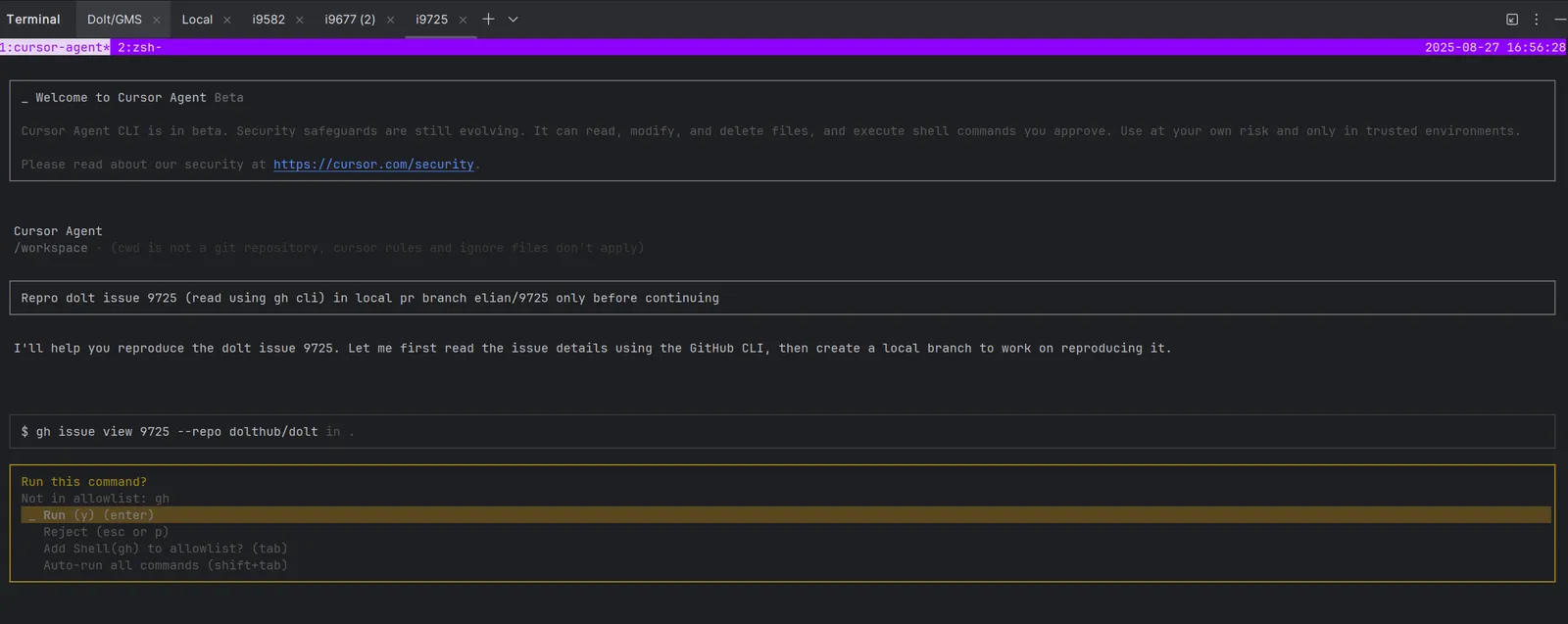
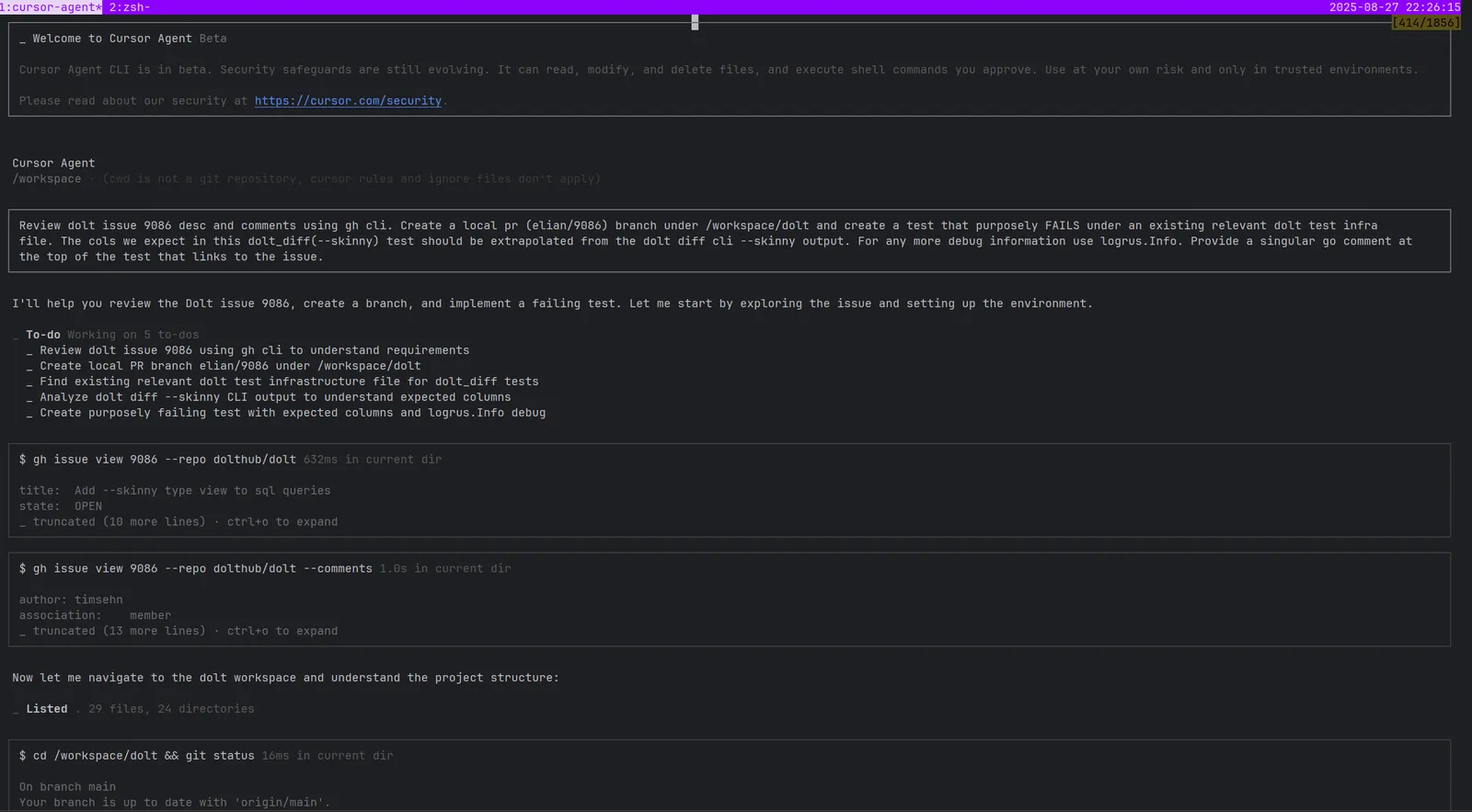
Task boundaries became critical early on. I keep each agent on its own local PR branch to avoid them touching main at all. This makes it much easier to review their changes with git diff main and prevents any conflicts between agents. I use simple prompts like “repro issue #### on dolt repo (access with gh cli) on a local pr branch elian/#### only.” I also keep a CLAUDE.md file with common commands and program structure. This stops agents from reinventing wheels or guessing about unfamiliar code.
Taking agent progress in measured steps prevents them from spiraling into unproductive directions while maintaining their operational autonomy. I monitor work incrementally rather than letting agents run unconstrained. This approach keeps me focused on what I want accomplished rather than what I don’t want, which has proven far more effective for maintaining direction and quality.
Resource monitoring became a painful lesson in overconfidence. I initially tried running six agents (for long periods), assuming more was always better. Even with 32GB of RAM, I consistently hit memory limits with browser instances, Docker containers, GoLand IDE, and growing chat logs. The worst part? The Docker daemon crashes, which closes every container instance and forces me to restart Docker entirely. This wipes out hours of agent conversation history because we lack chat saves. So, for me, 3-4 agents is my memory limit on long runs.

My setup still has significant optimization gaps to be fair. I haven’t messed with WSL (Windows Subsystem for Linux) memory usage or Docker core allocation settings yet, but tinkering with them might alleviate the resource overhead that causes Docker daemon crashes. Lambdabats can take longer to run than targeted local bats tests, due to long startup times, so I focus on bats runs, which also adds to the memory pressure.
Negative instructions prove counterproductive and wasteful. I never tell agents what they shouldn’t do as it clutters their reasoning space and diverts focus from the specific issue at hand. Instead, I provide clear, positive directives about what to accomplish. This approach keeps agents focused on solutions rather than constraints. I may ask for reverts, but these aren’t permanent rules for agents to keep in their context.
I learned to break down problems because agents try to speed up their completion as their context window fills up. This makes them cut corners on the initial or concluding steps in the instructions. Now I enforce pure steps that focus on one issue, preventing agents from rushing through important parts. I’m curious about exploring agents launching other agents for specialized sub-tasks like writing tests or investigating function existence. The hierarchical approach could be interesting, but I suspect coordination complexity is no joke.
The Transformation#
Running multiple agents taught me something I didn’t expect: agents act more like separate services than helpful assistants. Give them clear boundaries and isolated environments, and they work great. Try to scale them carelessly, and you get the same coordination mess that hits any complex system.
Agents also behave like stressed humans. When their context gets full, they rush through steps and skip important parts. They need clear tasks and concrete directions. They’re not magic infinite compute but “cognitive” entities with real limits that compound under pressure.
The throughput transformation is the real story here. Instead of waiting for one agent to finish before starting the next customer issue, I now have 3-4 agents working in parallel. This shifts the entire optimization problem from “how do I make this one thing faster” to “how do I keep multiple streams of work flowing.” Customer issues that used to queue up behind each other now get parallel attention.
Having to break every task into tiny steps for agents showed me something: there’s way more hidden complexity in “simple” coding tasks than I realized. All that orchestration overhead isn’t waste but the cost of making implicit knowledge explicit.
This builds on what we explored in The Agentic Software Engineer about developers becoming “code editors” who review agent-generated work. But running agents in parallel adds another layer. We’re not just reviewing code anymore but plan multiple concurrent workstreams. It’s like combining a Project Manager with a DevOps Engineer. The question evolves from “can I effectively review agent code” to “can I coordinate multiple agents without losing quality.”
If you’re interested in learning more about how to integrate AI agents into your development process, check out our other articles or join us on Discord to discuss your experiences.