
Here at DoltHub, we’re embracing the agentic revolution. A few weeks ago, I discovered Claude Code and it changed my whole perspective on using generative AI for software development.
Moreover, we think Dolt has a major role to play with agents. Agents work because their write targets, code in files, are stored under version control, allowing multiple asynchronous writers, instant rollback, and diffs for human review. Without version control coding agents would not work. Dolt brings version control to databases, the place where the rest of the write targets in software development, structured data, are stored. Swap your database out for Dolt and allow agents to work on a branch through your website or API. Review the changes when the agent is done just like you do with code. Dolt is the database for agents.
So, naturally, we’re curious about the other coding agents out there beyond Claude Code. There are three agents with a command line aesthetic: Claude Code by Anthropic, Codex by Open AI, and Gemini by Google. There is also “agent mode” in Cursor which is now on by default for those who prefer a more traditional Integrated Development Environment (IDE) interface.

Which of these four is the best? Should you switch agents based on the task? This article tries each agent against two tasks: a small bug fix and a more ambiguous code search and understanding problem. I use the results of this experiment to review each agent.
The Tests#
I devised two tasks that, given my experience with Claude Code, I thought agents would be able to solve.
1. The Bug#
The first is a simple bug fix. The prompt I used was:
Fix this bug: https://github.com/dolthub/dolt/issues/9176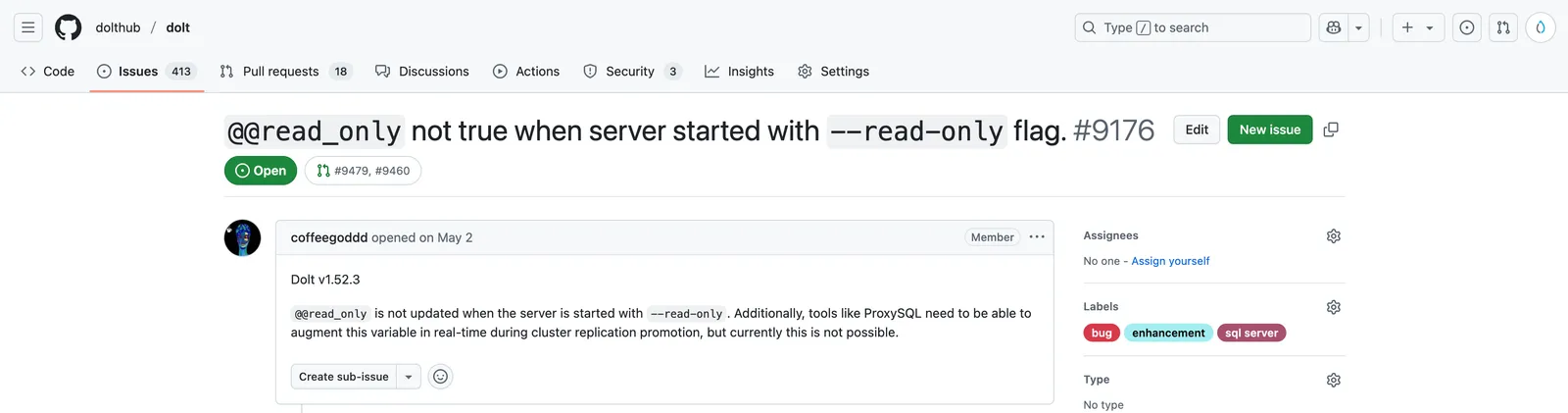
There’s not much to go on in there but it is a rather simple change to make and test.
2. The Ambiguous Task#
The goal of this test is to unskip a single Bash Automated Testing System (BATS) test. Dolt uses BATS to test command line interactions.
The working directory contains the open source projects Dolt, go-mysql-server, and vitess.
Your goal today is to fix a single skipped bats test as defined in dolt/integration-tests/bats.
bats is installed on the system and can be invoked using bats /path/to/file/tests.bats.
Make sure you compile Dolt before running the tests.
A single test can be run using the -f option which is much faster than running the whole test file.
Focus on making a very simple change.
SQL behavior is a bit harder to fix because it is defined in go-mysql-server and vitess.This test judges whether the agents can search a codebase and use that knowledge to differentiate a simple fix from a hard fix.
The Results#
I spent three full days setting up my environment for each agent, getting each agent to work, and ushering the agents through each task. All but Gemini were eventually able to complete both tasks and produce working Pull Requests to the Dolt repository.
I’ve given each agent an overall letter grade influenced by its performance in four categories: interface, speed (ie. code/prompt), cost, and code quality. I’ve ordered the tools from worst to best below. I’ve included commentary to explain my ratings.
Gemini#

| Overall | F |
|---|---|
| Interface | C |
| Speed (Code/Prompt) | F |
| Cost | A |
| Code Quality | F |
Task #1: The Bug#
Gemini failed to produce working code for this task after about two hours.
I feel like Gemini could have fixed the bug had it focused on the simplest solution first. It started with the literal interpretation of the bug, thinking that it needed to implement a read_only mode and have that mode controlled by the system variable. It did not inspect the code to see read_only mode already existed. So, it set off down a path to implement duplicate read_only functionality. I decided to let it proceed because having the read_only variable control read_only mode would actually be a superior change to just populating the variable for read purposes.
But after over an hour, I realized it was off track by noticing changes to journal_writer.go, a definite do not touch, and I instructed it to revert all its changes and just populate the system variable. It worked for another hour or so with prompts from me but I think it was sufficiently confused so it could not make progress.
Finally, after about two hours it froze and would not proceed. I’m not sure if I ran out of quota or if I hit some sort of UI bug. But at this point I was sufficiently frustrated that I gave up.

Task #2: The Ambiguous Task#
For the ambiguous task, Gemini seemed to not understand how to scope tasks before choosing one. It attempted the following bug fixes, each for 30 minutes or so before getting it or I got frustrated and started another task.
- Implement
RESET PERSIST - Implement double type with precision
- Add to
dolt_docswithdolt add - Implement detached head
- Removed a
remote-engineskip that was surrounded by an IF block. - Tried to add a lock to
dolt backup
In previous runs with Claude Code, I had watched it fail to implement double type precision so we can give Gemini a pass on that one. Removing a skip in an IF block was useless change. The others were massive undertakings. Gemini didn’t stand a chance. No basic understanding of how difficult a task will be as evidenced by the following conclusion.
Okay, I've reviewed the skipped tests again. I'm looking for something
truly simple.
Let's consider integration-tests/bats/commit_tags.bats, line 69: skip
"need to implement detached head first". This seems like a good
candidate. It's a clear "todo" and "detached head" sounds like a core
Git concept that Dolt should support. If it's truly a missing feature,
implementing it might be straightforward.Commentary#
There’s some real issues with Gemini’s general approach combined with bad basic tactics.
I used it a full day and got no working code. Moreover, in the end I was very frustrated. I did not think I could have changed my prompts or interactions with Gemini to get more out of it. This is in contrast to the other agents where even if they didn’t work exactly the way I wanted at first, I could direct them to work a bit more how I liked. With Gemini, I felt like there was no hope. Gemini needs major improvement before I would try it again. It is new so I’m sure Google will make it better.
Tactically, Gemini exhibits the following issues:
- It often can’t edit files, looping for minutes trying and failing as seen in the screen capture below
- It does not know to run single tests, it only runs whole test files, slowing iteration immensely
- It used and continued to use print statements for debugging even though they weren’t printing output and I prompted it not to use them
- It will routinely make far larger edits than other agents

With no working code produced, I was forced to give it a failing grade overall and on speed and code quality.
On the bright side, Gemini does work for long stretches without requiring prompting. Unfortunately, it is often working very ineffectually. At one point it removed everything from Dolt’s go.mod and then proceeded to re-add each dependency as it couldn’t compile. This took 20 to 30 minutes.
The interface is clean and you can change the look and feel to match your tastes. However, it is quite verbose in its explanations and it is hard to tell sometimes exactly what it is changing.
On cost, Gemini is free which is the best it could be. Though I did use my DoltHub Google Workspace account to login so it may cost DoltHub $20/month based on the documentation.
Cursor#

| Overall | B- |
|---|---|
| Interface | C+ |
| Speed (Code/Prompt) | D |
| Cost | A |
| Code Quality | B |
Task #1: The Bug#
For the read_only bug, Cursor was able to produce a working Pull Request in approximately 2 hours with greater than 25 prompts. I had to prompt it at the end to clean up dead code. The code is very similar to what Claude Code produced. It wrote new tests instead of modifying existing ones which I liked. In general, Cursor was slow but strong on this task.
Task #2: The Ambiguous Task#
For the ambiguous task, Cursor had to find another test to skip greater than 10 times. It relied on my input to tell it what was easy and hard. It did not seem to have good intuition about what was easy. It made deep attempts, spending approximately two hours on each issue, to fix two fetch bugs but failed on each. Claude Code was able to fix one of the fetch issues Cursor failed to fix.
Finally, Cursor identified a skipped test in sql-diff.bats. Here is the Pull Request. After inspecting the test and the code, it removed a check which caused Dolt to panic. Given the panic, it decided that Dolt can’t diff across schema and data changes, so we decided to update the test to the current behavior. It did find something and unskip the test so Cursor succeeded in this task, barely.
The whole process took about 4 hours with me watching and prompting the whole time.
Commentary#
In general, Cursor agent mode works. I was able to generate quality code.
However, its approach and design are a lot closer to a coding partner than coding agent. It rarely works for more than five minutes without pausing for you to confirm its approach. This means you end up sitting there watching it work, confirming that it is on the right track, or answering its questions. Even the interface is more built to review code as it is generated, rather than all at the end after it works. This all contributed to my middling rating on interface. I imagine agents as autonomous partners working in the background, not a coding partner where I review its every move. For some, Cursor may be their preferred interface.
This approach really slows down the speed of the process and you can’t do other things in the background while the Cursor agent is working. I was able to get code produced but it took 3-5X longer than it took with Codex and Claude Code. And I needed to be watching it the whole time. I was more aware in the moment of what Cursor was doing and I was more in tune with the code it was writing as it was writing it. For large changes, this may have saved me time in code review but the two tasks in this bake off were small.
On cost, I used the free plan to get these changes made so it doesn’t get much better than that. The models the free plan accesses are clearly capable of producing working code in agent mode. Cursor does offer a $20/month and $200/month plan that give access to better models, but given my experience I don’t think those are strictly necessary.
Finally, the code Cursor wrote for the read_only bug was clean and very similar to Claude Code’s. I did have to prompt it to delete dead code. Cursor did try and fail to fix a fetch bug that Claude Code was able to fix. But it did succeed in finding a different test to unskip that was much easier. So, on code quality I rated it slightly above average.
Codex#

| Overall | B |
|---|---|
| Interface | C- |
| Speed (Code/Prompt) | A |
| Cost | B+ |
| Code Quality | B- |
Task #1: The Bug#
For the read_only bug, Codex made good progress for about 30 minutes until it ran out of context. Then, it just hung and spat out ambiguous “stream errors”. I was surprised after inspecting the code that it had produced that it had fixed the bug with very minimal changes.
After pushing to GitHub, I noticed the Go tests were failing. Because Codex had hung, I had to restart with a fresh context and prompt it to fix the failing tests. I think this cost it some cycles because it proceeded to iterate on fixing the tests for an hour. Codex is extremely hands off and offers little in the way of explanation of what it is doing. I suspected it was down a rabbit hole but it fixed the tests with no user intervention. I was surprised.
Here is the Pull Request it generated. It add cases to existing tests which is ok but I would have preferred new tests. It also picked a weird Go test to add the read_only assertion to. The code works and is very minimal and clean.
Task #2: The Ambiguous Task#
Codex really performed well on the ambiguous task. It found a test that could be unskipped with no code changes in less than 5 minutes with no additional prompting. Here is the Pull Request. Very strong performance here. So strong that I wonder if Codex got lucky.
Commentary#
Codex produced working code very fast for very little cost. It is light on both user input and user feedback. It is the most agent-y coding agent. With a better interface, it would be a strong competitor to Claude Code.
On the downside, I had a hard time getting Codex started due to this bug. If you don’t set up your account right, it just spits out “stream errors”. In general the user interface is buggy with characters not clearing from the screen making output harder to read the longer you stay in the same session. Even without the bugs, the user interface is hard to read and the model doesn’t explain much. Finally, there are way more permissions checks in the beginning to get it started.
On cost, the whole session cost me $4.73. This was for about 2 hours of work. This is about 1/4 the cost of Claude Code. OpenAI is keeping Codex cheap.
Claude Code#

| Overall | A |
|---|---|
| Interface | B+ |
| Speed (Code/Prompt) | B+ |
| Cost | C- |
| Code Quality | A |
Task #1: The Bug#
Claude Code fixed the read_only bug in approximately 45 minutes using 4 prompts.
- Fix the bug.
- Please add a bats test.
- You changed code in 3 places. That could be one place.
- The Go tests fail in CI. Fix them.
You can see the Pull Request here. The code is clean and it discovered and fixed an additional issue with preserved state bleeding over into other tests. It also tested both ways to set the read_only variable. No other agent did that.
Task #2: The Ambiguous Task#
For the ambiguous task, Claude Code fixed a fetch test with code changes to implement the missing functionality in about 45 minutes. Cursor failed to fix the exact same test. This was accomplished with 3 prompts.
- Fix a test prompt from above
- Good progress. Please actually unskip the test
- Clean up some dead code I found in review from a failed approach
This is the Pull Request. The code is clean and the logic it fixed is rather tricky. I was very impressed with this fix.
Commentary#
I think Claude Code is the standard other coding agents should be measuring themselves against. Claude Code outputs just the right amount of context about what it is doing. The prompt to code ratio is the right balance. It almost always produces challenging code in a reasonable amount of time.
Claude Code seems to persevere and stay on the right track better than other agents. Codex could be similar but it doesn’t explain what it’s doing so it’s hard to tell.
Tactically Claude Code does things other agents don’t do. I don’t think this is a model advantage. It uses manual tests to understand the behavior of the program. It never uses print statements to debug. It runs single tests to speed up iteration time. It seems to have a better grasp of shell commands and editing, not wasting cycles on trivial read and write operations.
As I say about Santa Monica, the only problem with Claude Code is the price. It is expensive. On average it costs about $10/hour and it can spike to as much as $20/hour, especially if you give it a task outside its capability.
Conclusion#
Judging using my two tests, Claude Code is currently the best coding agent. If you want more of a coding partner, Cursor may be better for you. Codex is strong if you want an agent that requires very little attention. Gemini needs some work but it’s new and I suspect it will get better. Have another agent for me to try? Come tell me about it on our Discord.