
Last month I published a blog post about the parallel invention of Prolly Trees, where I observed the repeated independent invention of a certain type of data structure within a relatively short period of time.
In short, I described the concept of a Merkle Tree created by applying a content-defined chunker to a file, hashing the chunks, and then recursively reapplying the chunker to the concatenated list of hashes until only a single chunk remained. Each iteration of this process defined a separate row of the tree, with the leaves containing the chunks of the original file. This process allows for storing the version history of a dataset while achieving a high level of data deduplication.
That post kicked off enough conversation and debate that I felt it was worth taking another look at some of my claims. I definitely recommend at least skimming the original post before continuing here. I’ll wait.
Okay, all caught up? Great. Let’s continue.
Even More Parallel Invention#
In my previous post, I included every implementation of this concept that I was aware of, but acknowledged that it wouldn’t surprise me if there were more.
So given the amount of traction the original post got, it’s not at all surprising that people chimed in with other examples that they either knew about or had created themselves:
- The creator of rdedup pointed out how they independently invented using recursive content-defined chunking to build a Merkle Tree back in 2016.
- compressedgas on HN brought up Jumbo Store, another implementation of nested content defined chunking used for storing files circa 2007, predating bup by two years.
A couple of other people mentioned other previous projects that used a content-defined chunker to build Merkle Trees, such as this proposal to add file chunking to git. However, that proposal is missing the most important bit, which is the idea that this chunking is applied recursively. In fact, the linked proposal by C. Scott Ananian explicitly rejects the idea of applying the process recursively, saying “I propose keeping this only one-level deep: we can only specify chunks, not pieces of files.” So I’m not sure that counts.
What are the Properties of a Prolly Tree?#
Of all the responses the last post got, the most illuminating came from Aaron Boodman, the co-creator of Noms and the nomenclator of the term “Prolly Tree”. He chimed in to correct the record, both commenting on Hacker News and messaging us on the DoltHub Discord (which I’ve heard is a really cool place for people who love data structures) in order to add some important context. He clarified that:
- The Noms team was in fact familiar with bup. In fact, they cite bup as an inspiration in their technical overview, and felt it was important to give appropriate credit.
- The design of Noms’ Prolly Trees had an important innovation over Bup’s recursively chunked trees, which justified giving a new name to the data structure. To quote one of Aaron’s comments on Hacker News:
The reason I thought a new name was warranted is that a prolly tree stores structured data (a sorted set of k/v pairs, like a b-tree), not blob data. And it has the same interface and utility as a b-tree. Is it a huge difference? No. A pretty minor adaptation of an existing idea. But still different enough to warrant a different name IMO.
Essentially, Aaron argued that a defining aspect of Prolly Trees is the fact that they can be used to implement key-value maps. In my original post, I said that “a prolly tree is ultimately nothing more than a Merkle Tree built by recursively applying a Content-Defined Chunker, such as with a rolling hash function.” But Aaron opted for a stricter definition: in order to be a Prolly Tree, the chunking process must understand and utilize the structure of the underlying data in order to expose the same interface as a B-tree. Using recursive chunking is necessary, but not sufficient.
While I did discuss this property in the original post, I presented it as an innovation on top of Prolly Trees, a use case rather than a core requirement. But Aaron is right to highlight it, because it’s a property that enables use cases beyond any of the prior implementations.
Noms’s best and most novel features were the ability to do fast lookups on structured objects, and its Git-inspired diffing, branching, and merging of values. Aaron would go on to create Replicache and Zero, which use Prolly Trees to build Conflict-Free Replicated Data Types (CRDTs).
I work on Dolt, which started its life seven years ago as a fork of Noms. It’s the world’s first version controlled database. And neither the database functionality nor the version control capability would be possible if we were just building on something like bup; the B-tree-like data model that Noms invented is essential for that.
None of this was possible with bup, or the other projects of its era that used content-defined chunking for the purposes of storing large opaque files. Bup’s trees are useful for efficiently storing multiple versions of a file, but they can’t be used to diff or merge versions of a file outside of the most trivial of cases. (Resolving conflicts in concurrent changes to a content-defined Merkle tree is a deceptively challenging problem, which will be the topic of an upcoming post.)
That’s the real power here: leveraging the semantic meaning of the data in order to embed information in tree keys. It’s a nontrivial addition. It gives a double-meaning to the “content-defined” part of content-defined chunking: the chunker is defined not just on the file bytes, but on its actual meaning.
I suppose that hearing directly from the guy who invented the term is probably as close to a source of truth as we’re ever going to get: Bup doesn’t use Prolly Trees. Sorry, apenwarr. It’s still really cool though.
Most of the other projects that were brought to my attention fall into this category too: rdedupe and Jumbo Store use the same recursive chunking strategy as bup, but neither extend the functionality beyond storage and compression.
Revisiting Inria and XetHub#
Based on Aaron’s clarifications, we can imagine a data type with four properties:
- History independence - If two trees have the same underlying data, then the trees are bit-for-bit identical.
- Structual sharing - Two trees with only small changes between them should be able to reuse storage for the parts that haven’t changed.
- Queryable - If the tree stores structured data, it’s possible to evaluate queries on that structured data while minimizing the number of chunks that need to be read.
- Diffable and Mergable - It should be possible to compare two versions of a tree, or merge two concurrent changes made to a tree, with a runtime based on the size of the changes, not the total tree size.
Bup had the first two properties, but lacked the last two.
But what about the other parallel discoveries, BlueSky’s Merkle Search Trees (based on Inria’s paper) and XetHub’s Content-Defined Merkle Trees (based on a DePaul University paper)?
The Merkle Search Trees described by Inria and used by BlueSky are specifically designed for key lookup (hence the “search” in the name). Both of the latter two properties naturally follow from this choice.
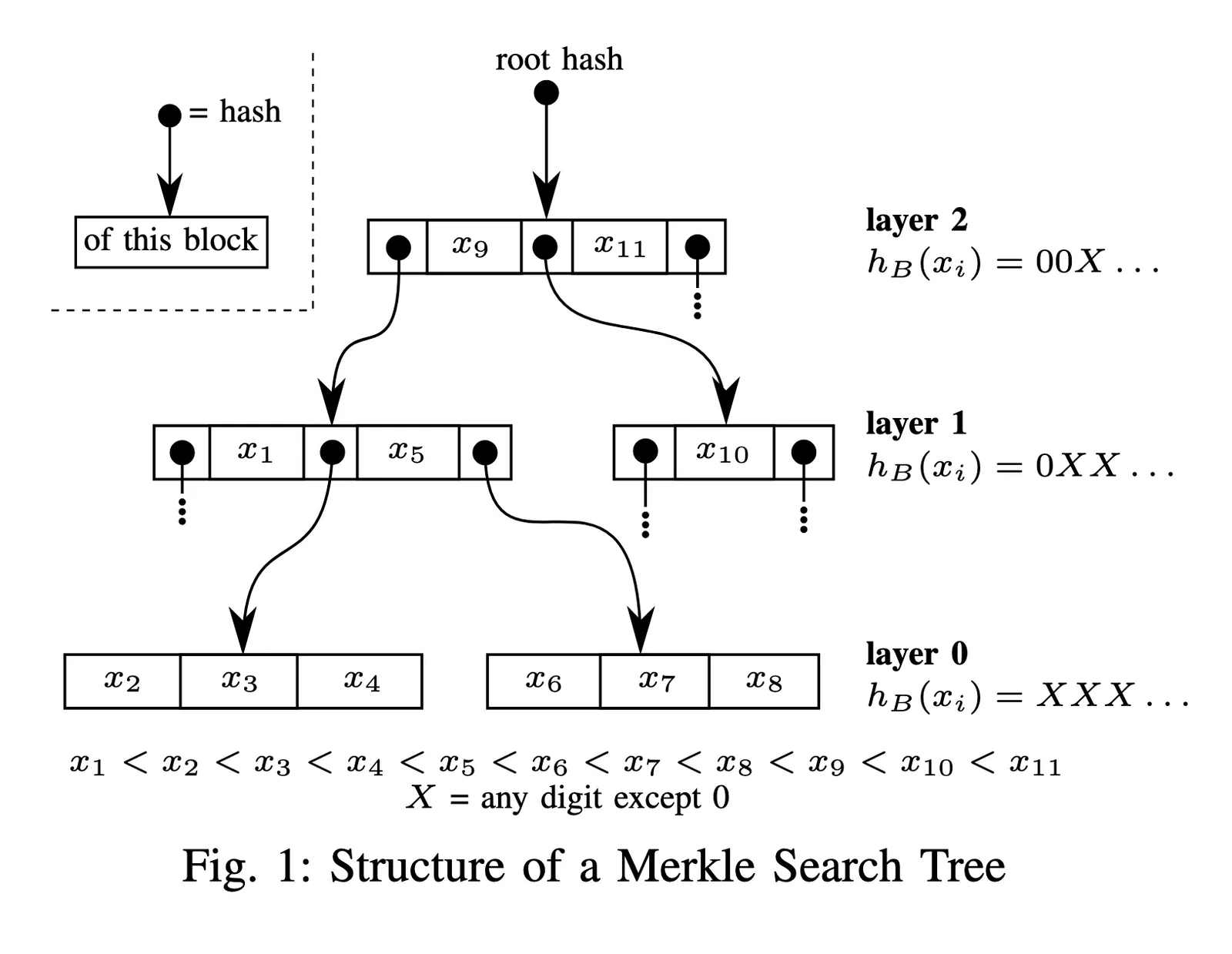
The above diagram is from the Inria paper, and it does a great job of conveying their data model while leaving very little to the imagination: keys stored in intermediate nodes create a usable tree map with a data-driven shape. That’s a Prolly Tree.
But XetHub’s Content-Defined Merkle Trees are… interesting. The DePaul University paper, which formed the basis of their implementation, described a method for compressing virtualization containers. The paper’s approach has no consideration for the structure of the underlying data, and doesn’t store any keys or other metadata in the Merkle Tree it produces. It’s thus more akin to bup than any of the other designs.
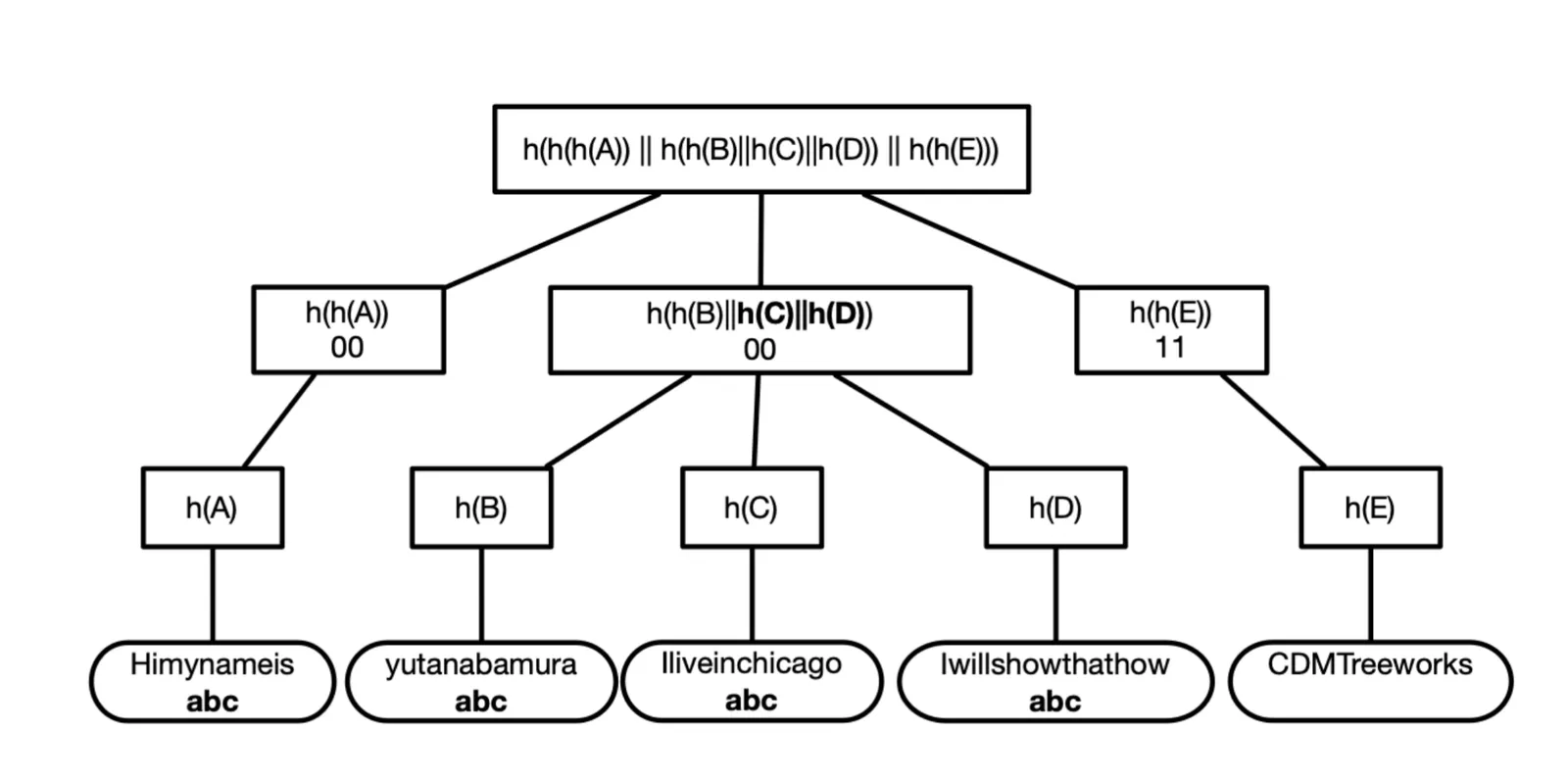
This is from the DePaul paper. There’s a the conspicuous lack of labeled edges that could be used for data lookups. If XetHub had implemented their DePaul design exactly, then I’d say no, they didn’t invent a Prolly Tree.
But notably, XetHub didn’t limit themselves to the DePaul design, and did something quite clever. In their pursuit of improving how they stored Parquet files, XetHub realized that they could leverage properties of the file format and create a custom chunker specifically for chunking Parquet files:
- First, they realized they could hash table keys instead of opaque byte sequences, in order to avoid chunk boundary changes when only table values changed.
- But more importantly, they realized that Parquet data is already naturally divided into chunks called “row groups”, where each row group encodes a range of records. And then they wrote a custom Parquet serializer that used their chunker to determine the boundaries between Parquet’s row groups.
Unlike the Noms and BlueSky implementations, XetHub’s trees don’t store metadata in the keys. But because their chunks coincide with the structure of the underlying data format, they didn’t need to; instead, an engine can load the chunks containing the necessary offsets. This has some very interesting tradeoffs:
- On the upside, it means that they can make the stored files available via a FUSE filesystem mount, which can then be accessed by standard tooling; any existing tool that can read Parquet files can run queries on a XetHub dataset, while the FUSE filesystem only needs to load the minimum set of chunks to resolve the query. Meanwhile, here at Dolt we had to implement our own SQL engine in order for people to run queries on our data store.
- On the downside, running a query on XetHub requires loading more chunks than an equivalent query on Noms or Dolt, because the engine will need to load one or more metadata chunks. Data that existed in keys now need to be read in from at least one other leaf node. This does make me suspect that XetHub could reduce the number of lookups required by storing key metadata in their Merkle trees in addition to having the data available in the underlying file.
Interestingly, they managed to do this without having to make any changes to the Parquet file format, although they also proposed that their stored chunks could have changes to the data format (such as removing absolute file offsets) and then regenerating the valid Parquet file as needed.
The most intriguing outcome of this design is the fact that XetHub has created a general-purpose framework that can theoretically accommodate many types of data. Each data type could get its own chunker that normalizes the file and intelligently draws chunk boundaries, and the FUSE filesystem allows the chunked file to be efficiently read by existing tools. Unfortunately, this requires a format that both already has good tooling and is amenable to this kind of chunking, which may be a big ask. In their paper, they mentioned also optimizing SQLite files in a similar way, although with a smaller performance gain.
I couldn’t determine after some light research whether or not XetHub offers the ability to semantically diff their normalized Parquet files across branches, or merge concurrent changes from different branches. My intuition is that it’s possible but would require specialized tooling can operates on their content-addressed storage, not just the files exposed by their FUSE system. If they have this capability, they should advertise it more; it’s a killer feature for Dolt and would be a killer feature for Xet too.
So although the implementation details are quite different, all three of these designs achieve similar properties.
On the other hand, Aaron was pretty clear that it was storing semantic data in tree keys that was the defining feature of a Prolly Tree. And XetHub very notably doesn’t do that.
So should we count it?
It might come down to whether the term Prolly Trees is referring to a data structure or a data type.
What is a Data Structure anyway?#
When we say “data structure”, sometimes what we actually mean to say is “abstract data type”:
- An abstract data type (ADT) is an interface with specific properties and behavior.
- A data structure is a specific data layout or storage format.
Data structures implement abstract data types the same way that types in a programming language implement interfaces. For example, a priority queue is a collection data type that can return the lowest-valued element in the collection, typically in constant time. A min-heap is a data structure that implements a priority queue because it provides the required behavior.
Noms, Inria, and XetHub each implemented a data structure capable of the same four properties mentioned above: history independence, structural sharing, efficient queries, and efficient diffing/merging. So in that sense we can say that Noms, Inria, and XetHub each implemented the same data type. But there are substantial differences in how these properties were achieved:
- Noms and XetHub achieve structural sharing by running an independent hash function on each level of the tree to produce the next level.
- Inria uses a single hash function to determine the number of chunk boundaries to draw for each new key.
- Noms and Inria store keys in intermediate nodes, allowing for a standard TreeMap lookup to locate sorted data and perform version diffing, while minimizing node loads for both.
- XetHub manifests data as mounted files that can be efficiently read using standard tooling, and requires additional content-aware analysis to perform version diffing.
So we can also say that these are clearly three different data structures.
But all of begs the question: does each of the proposed names for this invention (Prolly Tree, Merkle Search Tree, Content-Defined Merkle Tree) refer to the abstract type and the capabilities it provides, or the underlying data layout that achieves those capabilities?
When it comes to language, there is no absolute authority. It all comes down to convention. And for the cutting edge, there is no convention. Perhaps only time will give us the answer.
In the meantime, if you’re as obsessed with emerging data structures as I am, we have a Discord server where you can chat with us about it. And maybe we’ll convince you to give Dolt a try too; we think everything should be version controlled, why not version your database too?