
We’re on a mission to show that Dolt, the world’s first version controlled SQL database, works with all your favorite tools in all your favorite languages. Today, we stay in Dolt’s native tongue Golang to show off how Dolt works GORM, the most popular Golang-native object relational mapper (ORM).
Why GORM?#
GORM is the most popular Golang-native ORM. Like all ORMs, GORM offers applications a function-based alternative to writing SQL queries as raw strings and directly managing SQL sessions and transactions. The layer of indirection gives application a buffer between business logic and database internals. As a result, ORM interfaces are usually a common ground for coordinating front and backend changes. Switching databases providers, adding new databases, adding read/write replicas, moving tables between databases, and schema migrations are all common problems that would require more coordination and stress without ORMs.
Summary (TLDR)#
In this tutorial, we will use GORM with a Dolt backend. GORM is designed around a set of core interfaces that embed relational objects. Those interfaces can be hand-written in Golang or generated from preexisting SQL scripts/databases. Static model types make the read, update, delete lifecycle easy. Synchronizing table schemas and ORM models is a little trickier. GORM’s codegen feature makes this easier most of the time, but in certain cases, the codegen misses referential constraints and hidden tables.
Dolt is a relational database with Git-like version control. Throughout we blend GORM best practices with Dolt’s versioning features. In particular, Dolt’s branching can make it easier to keep table schemas and GORM models in sync. We walk through an example of how a team might use database branches and GORM’s codegen package to make upgrades easier.
The code in this demo is on GitHub, and the letters database used in the demo is on DoltHub.
Connecting To A Database With GORM (Read/Update/Delete)#
Setup#
We’re using an existing database, so we’ll start by installing Dolt and cloning the love letter database from DoltHub:
sudo bash -c 'curl -L https://github.com/dolthub/dolt/releases/latest/download/install.sh | bash'
dolt clone evan/lettersNext, we start a local SQL server for GORM to access:
cd letters
dolt sql-serverFinally, we make a new directory for our demo project, with the GORM and GORM-MySQL connector libraries handy:
mkdir gorm-demo
cd gorm-demoj
go mod init
go get gorm.io/gorm
go get gorm.io/driver/mysqlA fresh Golang binary can be downloaded here if needed. I ran this code with go1.21.5 darwin/arm6.
Hello World#
We use GORM’s codegen to seed the initial Letter model:
> go install gorm.io/gen/tools/gentool@latest
...
> gentool -dsn "root:@tcp(localhost:3306)/letters?charset=utf8mb4&parseTime=True&loc=Local" -tables "letters"
2024/03/13 10:22:04 got 6 columns from table <letters>
2024/03/13 10:22:04 Start generating code.
2024/03/13 10:22:04 generate model file(table <letters> -> {model.Letter}): /Users/maxhoffman/go/github.com/max-hoffman/gorm-dolt/dao/model/letters.gen.go
2024/03/13 10:22:04 generate query file: /Users/maxhoffman/go/github.com/max-hoffman/gorm-dolt/dao/query/letters.gen.go
2024/03/13 10:22:04 generate query file: /Users/maxhoffman/go/github.com/max-hoffman/gorm-dolt/dao/query/gen.go
2024/03/13 10:22:04 Generate code done.Here is the output:
type Letter struct {
ID int32 `gorm:"column:id;primaryKey" json:"id"`
Letter string `gorm:"column:letter;not null" json:"letter"`
Date time.Time `gorm:"column:date" json:"date"`
Lang string `gorm:"column:lang" json:"lang"`
Country string `gorm:"column:country" json:"country"`
Region string `gorm:"column:region" json:"region"`
}A minimal GORM script now just needs (1) the Letter model, (2) a database connection, and (3) a method combining the two:
import (
"gorm.io/driver/mysql"
"gorm.io/gorm"
)
func main() {
// refer https://github.com/go-sql-driver/mysql#dsn-data-source-name for details
dsn := "root:@tcp(127.0.0.1:3306)/letters?charset=utf8mb4&parseTime=True&loc=Local"
db, err := gorm.Open(mysql.Open(dsn), &gorm.Config{})
if err != nil {
log.Fatal(err)
}
readFirstLetter(db)
}
func readFirstLetter(db *gorm.DB) {
var letter Letter
db.First(&letter)
// SELECT * from letters LIMIT 1
}The library “just works” out of the box for common read and write cases as long as the Letter model mirrors that table’s schema. Later we’ll touch on some cases where this doesn’t work seamlessly.
Inserts and updates use a common interface. We’ll start with an insert. Below we create a new Letter object and hand off to the ORM with db.Save.
func insertLetter(db *gorm.DB) {
newLetter := &Letter{
ID: 1,
Letter: "the fault, dear Brutus, is not in our stars, but in ourselves",
Date: time.Now(),
Lang: "english",
}
db.Save(newLetter)
// // INSERT INTO `letters` (`letter`,`date`,`lang`,`country`,`region`,`id`) VALUES (?,?,?,?,?,?) ON DUPLICATE KEY UPDATE `letter`=VALUES(`letter`),`date`=VALUES(`date`),`lang`=VALUES(`lang`),`country`=VALUES(`country`),`region`=VALUES(`region`)
}db.Saveing a letter with a preexisting primary key will perform an update:
func updateLetter(db *gorm.DB) {
// fetch
var letter Letter
db.First(&letter)
// modify
letter.Country = "Italy"
letter.Date = time.Now()
// save
db.Save(&letter)
// INSERT INTO `letters` (`letter`,`date`,`lang`,`country`,`region`,`id`) VALUES (?,?,?,?,?,?) ON DUPLICATE KEY UPDATE `letter`=VALUES(`letter`),`date`=VALUES(`date`),`lang`=VALUES(`lang`),`country`=VALUES(`country`),`region`=VALUES(`region`)
}We use an INSERT INTO ... ON DUPLICATE KEY UPDATE above as an effective
upsert.
GORM has multiple ways to express most queries. For example, we can chain relational operators to find and update a specific field on rows that match a filter. Below we update all letters where country='Italy to now be country='IT':
func chainedUpdateLetter(db *gorm.DB) {
db.Model(&Letter{}).Where("country = ?", "Italy").Update("country", "IT")
// UPDATE `letters` SET `country`='IT' WHERE country = 'Italy'
}A more thorough list of interface options are here. There are also several ways to extend GORM’s model interface to enclose custom logic. And if you want to go even deeper, the clause API details how GORM aggregates chains of commands into a fully fledged SQL query strings. Each of these layers is customizable.
Dolt commits#
One way Dolt differs from traditional databases is its dual commit lifecycle. The SQL commit lifecycle is the standard transactional model. But Dolt also has versioned commits that capture snapshots of the database state in a commit graph. Adding to the commit graph regularly makes branch, merge, diff, and rollback easier.
We can hook into the query lifecycle with callbacks to interleave Dolt commits. It is often best to call dolt_commit() after a batch of related changes. Turning on the @@dolt_transaction_commit system variable is one way to perform a Dolt commit for every transaction commit. For this demo, we’ll instead use a ticker to rate limit Dolt commits to at most once per minute:
var ticker = time.NewTicker(time.Minute)
func (l *Letter) AfterSave(tx *gorm.DB) (err error) {
select {
case <-ticker:
tx.Exec("call dolt_commit('-Am', 'periodic commit')")
return tx.Error
default:
}
return nil
}This hook is called before a transaction COMMIT, so the ticker only picks up the contents of the current commit during the next iteration. The point is, Dolt transactions are easy to interleave into GORM, and need not overlap with SQL transactions.
System Table With Fixed Schemas#
We can use Dolt system tables to inspect the periodic commits we added to Dolt’s commit graph in the previous section. We use the dolt_log table to do this.
By default, Dolt hides system tables from the information_schema tables GORM uses for codegen. So we’ll need to first enable the dolt_show_system_tables variable for visibility:
> set @@GLOBAL.dolt_show_system_tables = 1;Now we can codegen DoltLog:
gentool -dsn "root:@tcp(localhost:3306)/letters" -tables "dolt_log"
2024/03/14 14:42:47 got 5 columns from table <dolt_log>
2024/03/14 14:42:47 Start generating code.
2024/03/14 14:42:47 generate model file(table <dolt_log> -> {model.DoltLog}): /Users/maxhoffman/go/github.com/max-hoffman/gorm-dolt/dao/model/dolt_log.gen.go
2024/03/14 14:42:47 generate query file: /Users/maxhoffman/go/github.com/max-hoffman/gorm-dolt/dao/query/dolt_log.gen.go
2024/03/14 14:42:47 generate query file: /Users/maxhoffman/go/github.com/max-hoffman/gorm-dolt/dao/query/gen.go
2024/03/14 14:42:47 Generate code done.The contents of dao/model/dolt_log.gen.go look like this:
const TableNameDoltLog = "dolt_log"
// DoltLog mapped from table <dolt_log>
type DoltLog struct {
CommitHash string `gorm:"column:commit_hash;primaryKey" json:"commit_hash"`
Committer string `gorm:"column:committer;not null" json:"committer"`
Email string `gorm:"column:email;not null" json:"email"`
Date time.Time `gorm:"column:date;not null" json:"date"`
Message string `gorm:"column:message;not null" json:"message"`
}
// TableName DoltLog's table name
func (*DoltLog) TableName() string {
return TableNameDoltLog
}Which we can use to issue read queries the same way we did with the Letter model:
func getLastCommit(db *gorm.DB) {
var log DoltLog
db.First(&log)
// SELECT * FROM `dolt_log` ORDER BY `dolt_log`.`commit_hash` LIMIT 1
}Table Functions#
Dolt provides many built-in functions for accessing versioning metadata
For example, the dolt_schema_diff table function returns the alter statements between any two commits. Reading schema diffs is as simple as reading the dolt_log table because the return type is constant. However, the syntax difference between tables and table functions means we need to use the raw SQL API to scan results:
type SchemaDiff struct {
from_table_name string `gorm:"column:from_table_name" json:"from_table_name"`
to_table_name string `gorm:"column:to_table_name" json:"to_table_name"`
from_create_statement string `gorm:"column:from_create_statement" json:"from_create_statement"`
to_create_statement string `gorm:"column:to_create_statement" json:"to_create_statement"`
}
func getOneSchemaDiff(db *gorm.DB) {
var result []SchemaDiff
db.Raw(
/* sql: */ "SELECT * FROM dolt_schema_diff(@from_commit,@to_commit)",
/* values: */ sql.Named("from_commit", "main"), sql.Named("to_commit", "feature"),
).Scan(&result)
// SELECT * FROM dolt_schema_diff('main', 'feature')
}System Tables With Dynamic Schemas#
The dolt_diff_{table} returns a variable number of columns to describe cell level diffs between two commits. In other words, table schema changes are reflected in the outputs schema of dolt_diff_letters. We load table diffs into an unstructured hashmap in this case:
func getOneDiff(db *gorm.DB) {
var result map[string]interface{}
db.Raw(
/* sql: */ "Select * from dolt_diff_letters where to_commit=@to_commit and from_commit=@from_commit",
/* values: */ sql.Named("from_commit", "main"), sql.Named("to_commit", "feature"),
).First(&result)
for k, v := range result {
fmt.Printf("%s: %#v\n", k, v)
}
}The burden of managing schema structure is shifted onto the application. If we are 100% certain of the letters schema between our two commits, we could load the diff rows into statically typed objects (in practice use a proper decoder/deserializer):
type TableDiff struct {
fromId int
fromLetter string
fromLang string
toId int
toLetter string
toLang string
fromCommit string
fromCommitDate time.Time
toCommit string
toCommitDate time.Time
diffType string
}
func getOneDiff(db *gorm.DB) {
...
tableDiff := TableDiff{
fromId: result["from_id"].(int),
fromLetter: result["from_letter"].(string),
fromLang: result["from_lang"].(string),
toId: result["to_id"].(int),
toLetter: result["to_letter"].(string),
toLang: result["to_lang"].(string),
fromCommit: result["from_commit"].(string),
fromCommitDate: result["from_commit_date"].(time.Time),
toCommit: result["to_commit"].(string),
toCommitDate: result["to_commit_date"].(time.Time),
diffType: result["diff_type"].(string),
}
}I only selected a subset of columns above for brevity. We could also access the to/from country, region, and date columns if desired.
Schema Changes (Create/Alter)#
Database migrations#
Applications that are lucky enough to age and grow must change over time as a consequence. Database migrations are one of the biggest resulting headaches. Migrations include CREATE and ALTER statements that create new databases, new tables, edit schemas of existing tables, and establish new referential constraints between tables. ORMs help decouple client services from databases services, but they don’t absolve us of forwards incompatible changes. Coordinating database migrations and client upgrades is inevitable.
A “versioned migration” is one way to perform this upgrade. The simplest way to version a migration is to combine a set of CREATE and ALTER statements into a SQL script, add that script into source control, and run the script in production. Every migration has its own “migration” script, and we can run migrations sequentially to retrace the production versioning. GORM references Atlas on their migration page as the traditional way to do this.
But this creates several problems. One is that the versioning history is explicit and imperative. We can only understand a point in time by looking at its aggregated history of SQL queries. Buggy or fixed migrations that impact a subset of database servers fail to self-correct. There is also an operational mismatch. We usually need to double the database count to separate before and after the upgrade. We can only test one set of changes at any given time, and the “production” database from the client perspective alternates between the two.
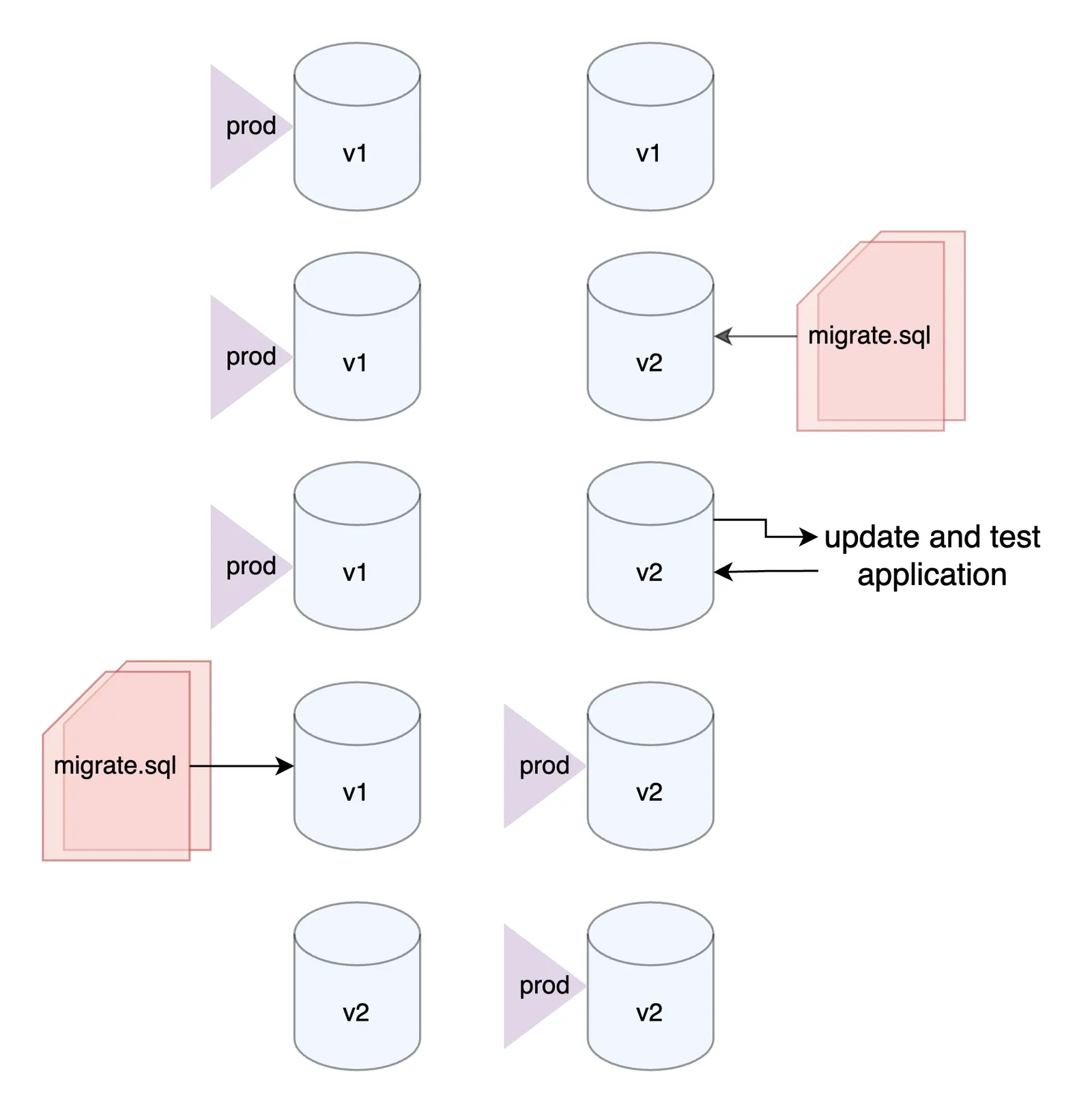
Dolt migrations#
With Dolt, migrations in GORM might look a little different. Choreographing migration scripts and client library updates is still an option, but we could also decouple the two. This lessens the coordination overhead otherwise required by a versioned migration script.
Here is the sample migration:
create table countries (id varchar(36) primary key default (uuid()), name varchar(1000) , lang varchar(1000), region varchar(1000));
insert into countries (name, lang, region) select country, lang, region from letters group by country, lang, region;
alter table letters drop column country, drop column lang, drop column region;
alter table letters add column countryId varchar(36);
alter table letters add foreign key (countryId) references countries(id);
alter table letters add column id_tmp varchar(36) default (uuid());
alter table letters drop primary key;
alter table letters drop column id;
alter table letters add primary key (id_tmp);
alter table letters rename column id_tmp to id;
update letters set countryId=(select id from countries limit 1);We split countries into its own table identified by a UUID id. This denormalizes letters into the core data and associated metadata. In the future we can add metadata to countries without impacting the letters table. We also establish a pattern for adding new metadata tables reference via foreign keys in the letters table. Finally, the UUID column for letters is a best-practice that supports multiple branch edits that side-step merge conflicts.
There are two halves to this migration split between (1) a database team and (2) an API team. The database team is concerned with edits to the feature branch and with operational continuity. The API team needs to update the application models to match the schema changes.
Here is how we add the changes to a new Dolt branch on the database side:
> dolt checkout -b feature
> dolt sql < alter_queries.sql
> dolt add letters, countries
> dolt commit -m "proposed schema alterations"And the resulting Dolt diff:
> dolt diff feature main
diff --dolt a/countries b/countries
added table
+CREATE TABLE `countries` (
+ `id` varchar(36) NOT NULL DEFAULT (uuid()),
+ `name` varchar(1000),
+ `lang` varchar(1000),
+ `region` varchar(1000),
+ PRIMARY KEY (`id`)
+) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_bin;
diff --dolt a/letters b/letters
--- a/letters
+++ b/letters
CREATE TABLE `letters` (
- `id` int unsigned NOT NULL,
`letter` text NOT NULL,
- `date` datetime(6),
- `lang` varchar(100),
- `country` varchar(56),
- `region` varchar(100),
- PRIMARY KEY (`id`)
+ `createdAt` datetime(6),
+ `countryID` varchar(36),
+ `id` varchar(36) NOT NULL DEFAULT (uuid()),
+ PRIMARY KEY (`id`),
+ KEY `countryID` (`countryID`),
+ CONSTRAINT `78ubif2r` FOREIGN KEY (`countryID`) REFERENCES `countries` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_bin;
Primary key sets differ between revisions for table 'letters', skipping data diffAnd here is how we can automatically generate the updated models for creating a PR on the API team’s side:
func generateModels() {
g := gen.NewGenerator(gen.Config{
OutPath: "./query",
Mode: gen.WithoutContext | gen.WithDefaultQuery | gen.WithQueryInterface, // generate mode
FieldWithIndexTag: true,
})
gormdb, _ := gorm.Open(mysql.Open("root:@(127.0.0.1:3306)/letters?charset=utf8mb4&parseTime=True&loc=Local"))
g.UseDB(gormdb) // reuse your gorm db
gormdb.Exec("use 'letters/feature'")
if gormdb.Error != nil {
log.Fatal(gormdb.Error)
}
g.ApplyBasic(
// Generate structs from all tables of current database
g.GenerateAllTable()...,
)
// Generate the code
g.Execute()
}We include an important use 'letters/feature' query to checkout the feature branch for our database connection (branch database revisions are another way to do this). The branch we choose determines which schema seeds our generated table structs. Here is the Git diff after generating our GORM models:
type Letter struct {
- ID int32 `gorm:"column:id;primaryKey" json:"id"`
- Letter string `gorm:"column:letter;not null" json:"letter"`
- Date time.Time `gorm:"column:date" json:"date"`
- Lang string `gorm:"column:lang" json:"lang"`
- Country string `gorm:"column:country" json:"country"`
- Region string `gorm:"column:region" json:"region"`
+ ID string `gorm:"column:id;primaryKey;default:uuid()" json:"id"`
+ Letter string `gorm:"column:letter;not null" json:"letter"`
+ CreatedAt time.Time `gorm:"column:createdAt" json:"createdAt"`
+ CountryID string `gorm:"column:countryID;index:countryID,priority:1" json:"countryID"`
+ Country Country `gorm:"foreignkey:CountryId;references:Id"`
}
+type Country struct {
+ ID string `gorm:"column:id;primaryKey;default:uuid()" json:"id"`
+ Name string `gorm:"column:name" json:"name"`
+ Lang string `gorm:"column:lang" json:"lang"`
+ Region string `gorm:"column:region" json:"region"`
+}This almost works seamlessly. The one wrinkle is that I had to manually add the Letter.CountryId->Country.Id foreign key reference. Without this addition, GORM associations and preloading would fail to auto-fetch the appropriate Country object when we scan a Letter.
The Dolt migration process is declarative and I think simpler than a versioned migration:
- Schema changes are isolated to the feature branch and immediately mergeable to main with
dolt merge feature. - GORM’s auto-generation lets us translate freely between database and application changes. The API team might have to make application edits in response to model struct changes, but many of these changes will be flagged at build time because of Golang’s static typing.
- The API team can test migrations by connecting to the
letters/featurebranch (or a clone of the branch). This is a configuration as opposed to a resource change. - Migrations can be asynchronous and concurrently tested, deployed, and rolled-back using Git and Dolt commits.
Application owners see diffs of the client code and database owners see diffs of the database changes. Everyone judges and edits changes in their respective context. But the last point is maybe the most important: there is no migration operational impedance mismatch. The two teams do not need tight coordination. They iterate in their respective layers until settling on an agreed configuration. The final changes are reviewable and versioned on isolated branches between the client and databases. The diagram below describes the two-way relationship between database and code migrations.
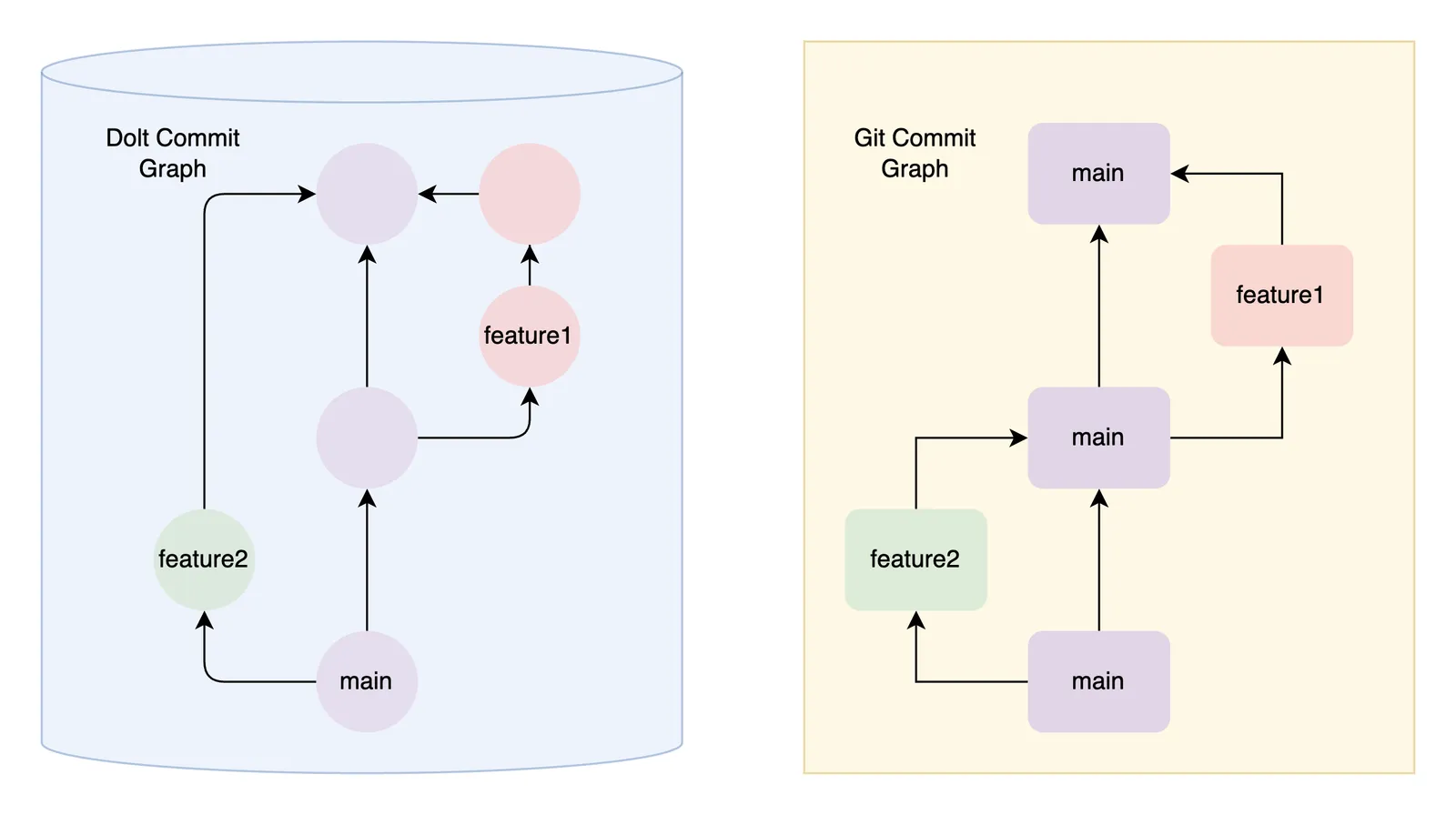
Summary#
This blog shows how to use GORM with Dolt. Because GoLang is static, read, update, and delete operations are fairly straightforward. The full sample app using a Dolt database can be found here. The operational difficulties are (1) getting GORM and database schemas in sync, and (2) keeping the two in sync during database migrations. We talked a little about how GORM’s codegen can make this synchronization easier. We also walked through a migration on a Dolt database to show how Dolt branches and GORM’s codegen reduces the burden of coordinating application-side changes.
If you have any questions about Dolt, databases, or Golang performance reach out to us on Twitter, Discord, and GitHub!