
Dolt is the world’s first version controlled SQL database. To implement Git-style version control functionality at Online Transaction Processing (OLTP) performance, Dolt has different hardware requirements than other OLTP databases. This article outlines general hardware sizing recommendations for your Dolt instance in disk, memory, CPU, and network.

Disk#
Dolt uses less disk to store a single HEAD of a database than MySQL or MariaDB. A HEAD is a term borrowed from Git. A HEAD in Dolt represents the data stored at a single point in history. For instance, when you import a dump file, the database after import represents a HEAD for that database. Databases like MySQL or MariaDB have a single HEAD whereas Dolt has multiple HEADs. Dolt implements modern compression on the data files it stores to save space at any given HEAD. Thus, Dolt uses less disk per HEAD than other comparable databases.
However, Dolt stores the complete history of your data going back to the inception of the database. This increases storage requirements. Traditional databases tend to store log files for disaster recovery. In Dolt, the data stored in these log files is essentially compressed and stored in the database itself. Thus, for short histories, Dolt could use less or equivalent disk to a traditional database. However, for long histories, Dolt will surpass traditional database disk usage.
Moreover, unlike traditional databases, Dolt produces disk garbage which must be collected occasionally to recover disk space. Depending on the frequency of your uncommitted updates, disk garbage can increase your disk requirements. Disk garbage accumulation is particularly acute for some import processes.
Example#
Let’s look at an example. I am going to load this sample database into both MariaDB and Dolt and compare the disk profiles. This sample database’s dump files are 167MB.
When I load the data into a fresh install of MariaDB, the database takes 187MB with an additional 157MB of log data.
$ du -h /opt/homebrew/var/mysql
4.0K /opt/homebrew/var/mysql/test
588K /opt/homebrew/var/mysql/sys
3.8M /opt/homebrew/var/mysql/mysql
4.0K /opt/homebrew/var/mysql/performance_schema
187M /opt/homebrew/var/mysql/employees
344M /opt/homebrew/var/mysqlThese logs look like the ib_logfile and the undo logs. These also look pre-allocated as they existed at approximately the same size on a fresh install.
$ ls -alh /opt/homebrew/var/mysql
total 443248
drwxr-xr-x 17 timsehn admin 544B Nov 27 13:21 .
drwxrwxr-x 9 timsehn admin 288B Oct 5 15:40 ..
-rw-rw---- 1 timsehn admin 7.7K Nov 27 13:21 Tims-MacBook-Pro.local.err
-rw-rw---- 1 timsehn admin 408K Nov 27 13:21 aria_log.00000001
-rw-rw---- 1 timsehn admin 52B Nov 27 13:21 aria_log_control
drwx------ 17 timsehn admin 544B Nov 27 13:17 employees
-rw-r----- 1 timsehn admin 16K Nov 27 13:21 ib_buffer_pool
-rw-rw---- 1 timsehn admin 96M Nov 27 13:21 ib_logfile0
-rw-rw---- 1 timsehn admin 12M Nov 27 13:21 ibdata1
-rw-r--r-- 1 timsehn admin 14B Aug 17 11:33 mariadb_upgrade_info
-rw-rw---- 1 timsehn admin 0B Aug 17 11:33 multi-master.info
drwx------ 90 timsehn admin 2.8K Aug 17 11:33 mysql
drwx------ 3 timsehn admin 96B Aug 17 11:33 performance_schema
drwx------ 106 timsehn admin 3.3K Aug 17 11:33 sys
-rw-rw---- 1 timsehn admin 36M Nov 27 13:21 undo001
-rw-rw---- 1 timsehn admin 36M Nov 27 13:21 undo002
-rw-rw---- 1 timsehn admin 36M Nov 27 13:21 undo003On Dolt, the database after importing the same dump file is 81MB. Remember, the size of the dump file was 167MB. Dolt does a pretty good job of data compression on disk.
$ du -h
0B ./.dolt/noms/oldgen
81M ./.dolt/noms
0B ./.dolt/temptf
81M ./.dolt
81M .As you can see, Dolt requires less storage for an un-versioned database than MariaDB.
Note, if you structure your import as many single point inserts, Dolt generates as much as 10X disk space as garbage. This dump file uses one large insert for each table, minimizing the amount of disk garbage produced. Structuring imports as large multi-value inserts is best practice when importing data to Dolt.
Garbage Collection#
Additionally, with Dolt, we can reclaim some space using garbage collection, invoked using dolt gc. In this case, dolt gc reclaims about 9MB of space. There is not much garage produced by this import process because the inserts are done in bulk, not as individual inserts. As you’ll see later, each individual uncommitted update in Dolt generates disk garbage.
$ dolt gc
$ du -h
8.0K ./.dolt/noms/oldgen
72M ./.dolt/noms
0B ./.dolt/temptf
72M ./.dolt
72M .Version Storage#
A good way to get a rough estimate of how much disk you need for version storage is to multiply 4KB by the number of update or insert transactions you intend to make, multiplied by the average number of indexes updated in a transaction, multiplied by a rough estimate of the depth of your tree. A rough estimate of the depth of your tree for most tables is log(table size)/2. This is a magic number and based on how many rows we can usually stick in a single chunk but it should generally work. This will give you an estimate of the un-garbage-collected storage you need.
Multiply this result by the percent of transactions you will Dolt commit and this will give you an estimate of your permanent storage requirements for history. This estimate is very rough and results will vary based on the data and nature of the updates. Obviously, it is better to test and observe your requirements from your actual use case.
Let’s see how this estimate holds up to our toy example. I concocted a simple shell script to update the same row twice, 500 times. The table I’m updating is ~2.8M rows. The column I’m updating has no indexes. The script makes a Dolt commit after every second update.
for i in {1..1000}
do
if [ $(expr $i % 2) == 0 ]
then
j=$(expr $i - 1)
dolt sql -q "update salaries set salary=salary+1 limit 1 offset $j"
dolt commit -am "Update for iteration $i"
else
dolt sql -q "update salaries set salary=salary+1 limit 1 offset $i"
fi
doneSo, I’m expecting the size of the update to be on the order of 13MB, 1,000 _ 4 _ log(2.8M/2). Our magic scale factor here is about 3.2. Let’s see how this works out in practice.
After running the updates, I get the following real world results, approximately 16MB added.
$ du -h
72M ./.dolt/noms/oldgen
88M ./.dolt/noms
0B ./.dolt/temptf
88M ./.dolt
88M .After garbage collection, I would expect half the space to be collected because half the updates are not committed.
$ dolt gc
$ du -h
79M ./.dolt/noms/oldgen
79M ./.dolt/noms
0B ./.dolt/temptf
79M ./.dolt
79M .As you can see about 9MB of the additional 16MB were garbage collected resulting in an additional 7MB of permanent storage needed for these updates. This is pretty close to our offhand estimates.
History Compression#
Currently, Dolt does not support any form of history compression. However, history compression via a Git-style rebase will be shipped in the next couple months. Moreover, we have other ideas to implement borrowed from Git, like Git graft, to store history in another location.
Memory#
Dolt is more memory-hungry compared to other databases. Memory is often the resource that limits scale of a Dolt database.
Dolt loads the commit graph into memory on start up. Queries require additional memory. Dolt is written in Golang, a garbage collected language, so we don’t have as much control over memory usage as databases written in other languages.
As a rule of thumb, we recommend you provision 10% to 20% of the database disk size as RAM. If you expect your database to be 100GB on disk, we would recommend 10 to 20GB of RAM. RAM usually comes in binary orders of magnitude so a 16GB host should work. If your database has a deep history and less data at each individual HEAD, Dolt may require less memory.
Example#
As part of our now discontinued data bounty program, we built a large, open database of US Hospital Prices. It’s 104GB on disk. It has a fairly deep history with only about 10GB of data at HEAD.
When I clone this database and start a dolt sql-server, Dolt uses 2GB of RAM.
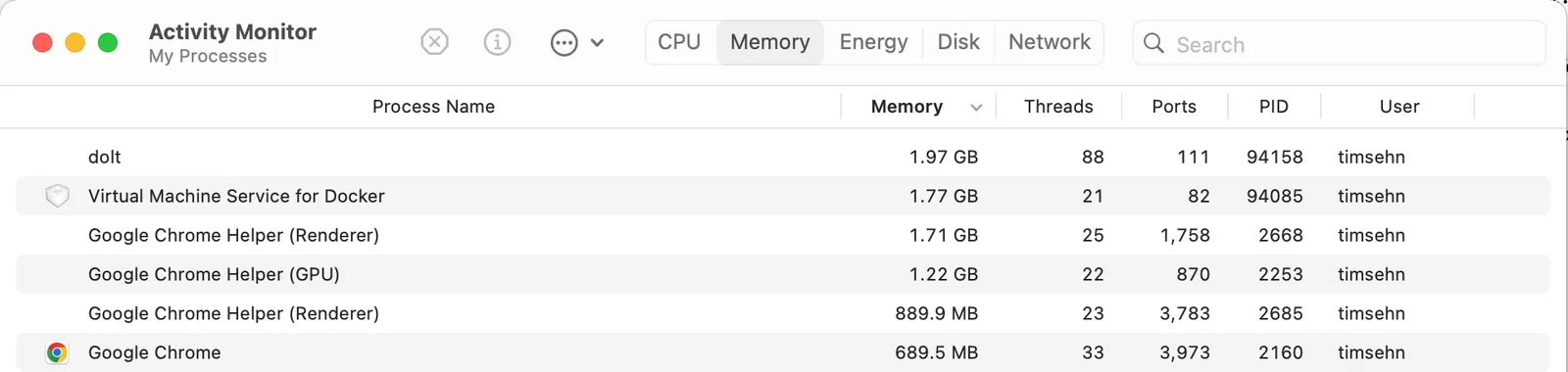
When I run a full table scan query against the rate table (select * from rate order by standard_charge desc limit 10), Dolt uses 4.6GB of RAM.
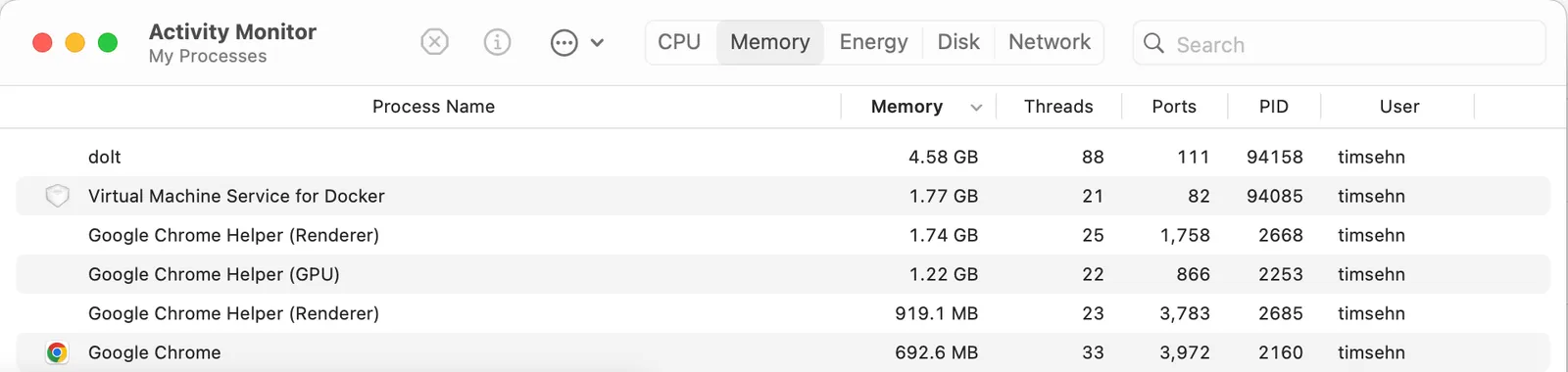
With any amount of parallelism you could quickly eat up 16GB of RAM and you would be more comfortable at 32GB. This fits with our 10-20% of database size recommendation.
CPU#
Dolt has no special CPU requirements. Dolt does not do any parallelization on a single query so CPU will only be used if you have high level of parallel read queries. Memory is much more likely to be the scale limiting factor in query throughput than CPU.
Network#
Dolt has no special network requirements. Dolt is no more chatty on the wire than MySQL. If you are making heavy use of the remotes port for cloning, you will want high upload bandwidth so your host can serve more data to the hosts cloning and fetching.
Conclusion#
As you can see, sizing your Dolt host is a little different than traditional OLTP databases. Dolt requires more disk and memory than a traditional OLTP database in most use cases. Need help sizing your Dolt instance? Come chat with us on our Discord. We’re happy to help.