
A year ago, our founder and CEO Tim wrote a blog post about the recent explosion of interest in decentralized databases. You can read it here. If you like learning about cool new technologies, you should read that first.
In Tim’s post, he defines “decentralized” as:
- Offline first: The database needs to be usable even when you’re not connected to the network.
- Sharing: Changes must be able to propagate the network. Nodes can form consensus on the state of the database.
- Fault Tolerant: A disappearing or misbehaving node shouldn’t make you lose or corrupt data.
- Trustless: Users in a network don’t have to know or trust each other. So sharding technologies that require coordination like Apache Druid or MySQL Cluster don’t count.
Tim’s post provides a great view of the ecosystem and categorizes the different core design principles that decentralized databases have. I’m going to take that idea even further.
How it Started#
See, if you’ve read any of our other blog posts, you’ve probably seen our catchphrase:
Dolt: It’s like Git and MySQL had a baby.

Git and MySQL had a baby. Somehow.
But combining Git and MySQL made me wonder what other things we can combine. If Git + MySQL = Dolt, then what about Postgres + RSync? GraphQL + Emacs?

It's like Android and GNU had a baby.
This isn’t entirely silly. Talking about “adding” two applications helps us understand what features each one is bringing to the table. It lets us break them down into their atomic parts and give those parts names. And once we do that, we can understand how two applications differ by comparing these “atoms”.
Imagine a supercollider for database software: We’re not just mashing random concepts together for fun.
We’re doing it for science.
Starting Simple#
Let’s start by imagining the simplest possible version of a decentralized database, based on Tim’s definition above. It would probably look something like this:
- A client connects to a known peer (of which there can be many) and requests a specific content-addressed chunk by sending the content hash to the server.
- The peer responds with the full chunk that corresponds to that hash, and the client verifies it.
That’s it. That’s all the application does.
Turns out this is a real application. It’s called Venti, and it was invented at Bell Labs in 2002. It’s one of the oldest open-source content-addressed storage servers. (But not the oldest, as we’ll soon see.)
But we’ve come a long way in the past 21 years, and modern databases can do a lot more than Venti can. In the years since Venti’s release, a plethora of new protocols added incremental features on this model.
Venti + “Discoverability” = BitTorrent#

A decentralized database being “Discoverable” means that clients in the network can request a chunk of data, even if they don’t know who in the network has it. All the client needs is the chunk’s name, which is usually a content-addressed hash. These databases are often called “Distributed Hash Tables”, and the algorithm for finding who has a given chunk is called a “gossip protocol”.
The most well-known DHT is BitTorrent, which enables file-sharing without a central host by content-addressing a piece of data and using a gossip protocol to help other nodes in the BitTorrent network find it1.
- Initial Release
- 2001
- GitHub
- https://github.com/bittorrent/bittorrent.org
Venti + “Graph Structure” = Perkeep#

A good database needs more than just storing and reading opaque chunks of data. Often, we want to inspect the structure of our data: either to semantically understand a chunk, or to understand the relationship between chunks.
Perkeep (formerly Camlistore) is a content-addressed database that also allows for storing metadata on the uploaded chunks2. This metadata forms the edges of a graph. One advantage this offers is the ability to store meaningful complex structures within it, like tags or directories.
Perkeep also has another important feature: it’s queryable: a user can write arbitrarily complicated search queries that leverage the structure of the database. This is technically a distinct feature from just having structured data, but we’re going to ignore that distinction for now, just to keep things simple.
- Tagline
- Perkeep lets you permanently keep your stuff, for life.
- Initial Release
- June 2013
- GitHub
- https://github.com/perkeep/perkeep
Smashing Atoms#
By using BitTorrent and Perkeep, we’ve identified two add-on features of decentralized databases. Discoverability and Graph Structure are both “atoms” that can be added to a decentralized database in order to make a more complicated “molecule.”
Now what would happen if we smashed those “molecules” together?
Prime the supercollider.
BitTorrent + Perkeep = IPFS#

The Interplanetary File System sometimes describes itself as “Torrents 2.0”. It uses a gossip protocol just like BitTorrent, but the chunks that it stores can contain pointers to other chunks, forming a graph. This graph is used primarily for (but is not limited to) representing file systems. Representing file systems this way has two advantages over BitTorrent:
- If two file systems stored in IPFS contain the same file, a client only needs to download and store that file once. It can then share that file with other nodes requesting either file system.
- User can clone and replicate part of a file system, such as a single file or directory, without having to clone and replicate the entire system. Thus, IPFS file systems can become much larger than a torrent.
Thus, IPFS combines the features BitTorrent and Perkeep to make something greater than the sum of its parts.
- Tagline
- A peer-to-peer hypermedia protocol
- Initial Release
- February 2015
- GitHub
- https://github.com/ipfs/ipfs
Dissecting Dolt#
And this is what we mean when we say that Dolt = Git + MySQL: Dolt is a decentralized datastore with a look and feel heavily inspired by Git. But it adds the MySQL query language on top of it. More generally, it adds support for Relational Data, which is how data in SQL is structured. It’s what allows data in SQL databases to be efficiently queried.
We could write this as Git + “Relations” = Dolt, which gives us our third atomic feature: Relations.
Alternatively, we can swap our perspective and say that Dolt is a SQL database, with Git’s version control capabilities added on top.
Viewing it through that lens lets us write MySQL + “Version Control” = Dolt. This gives us our fourth and final atom, Version Control.
Every decentralized database can be described as the set of “atoms” that it includes. Conversely, given a set of desired atoms, we can enumerate the databases that support that set. This is tremendously useful because it means that we can take each of these databases and put them on a map.
More specifically, we can put them on a Lattice.
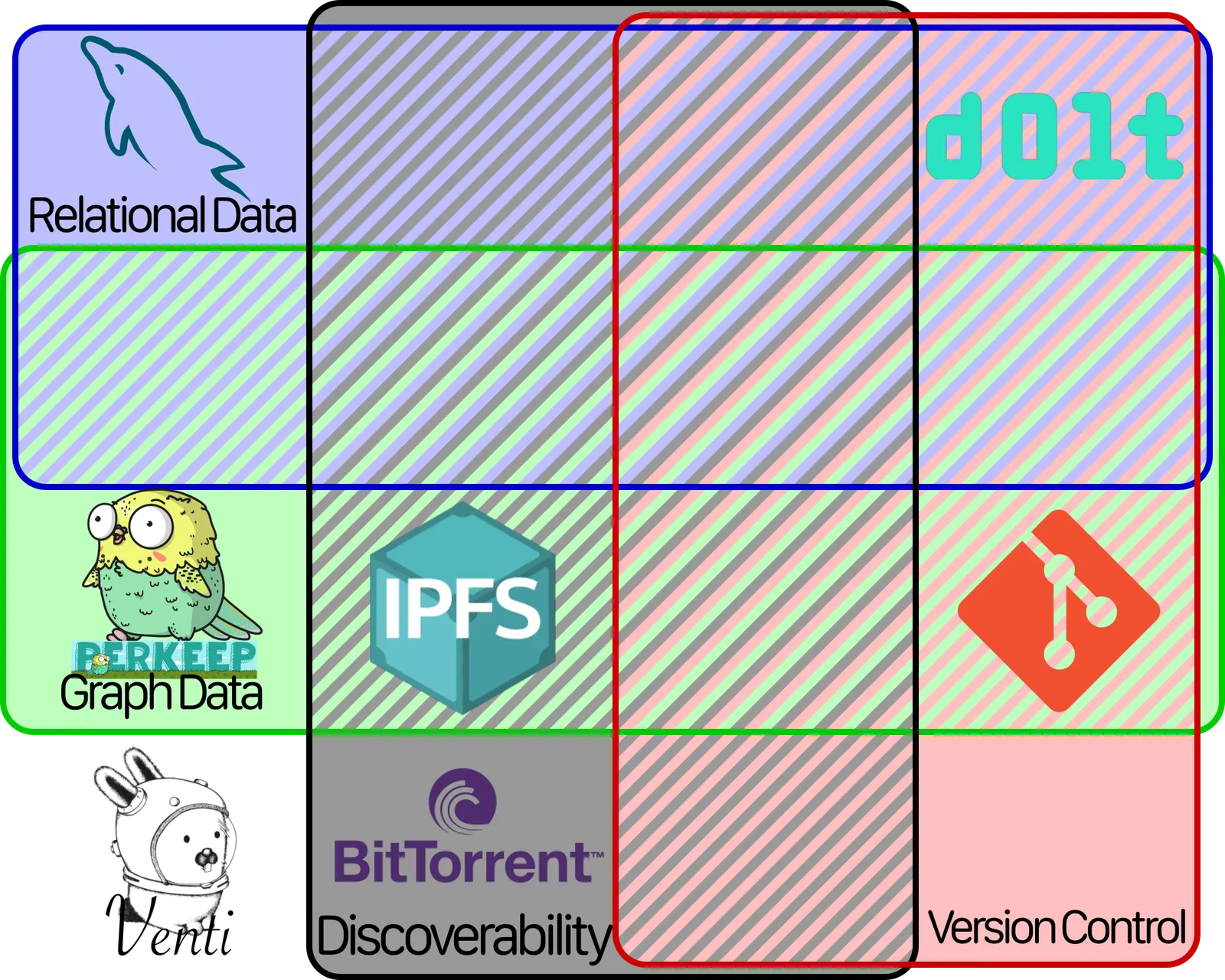
The Lattice of Decentralized Databases#
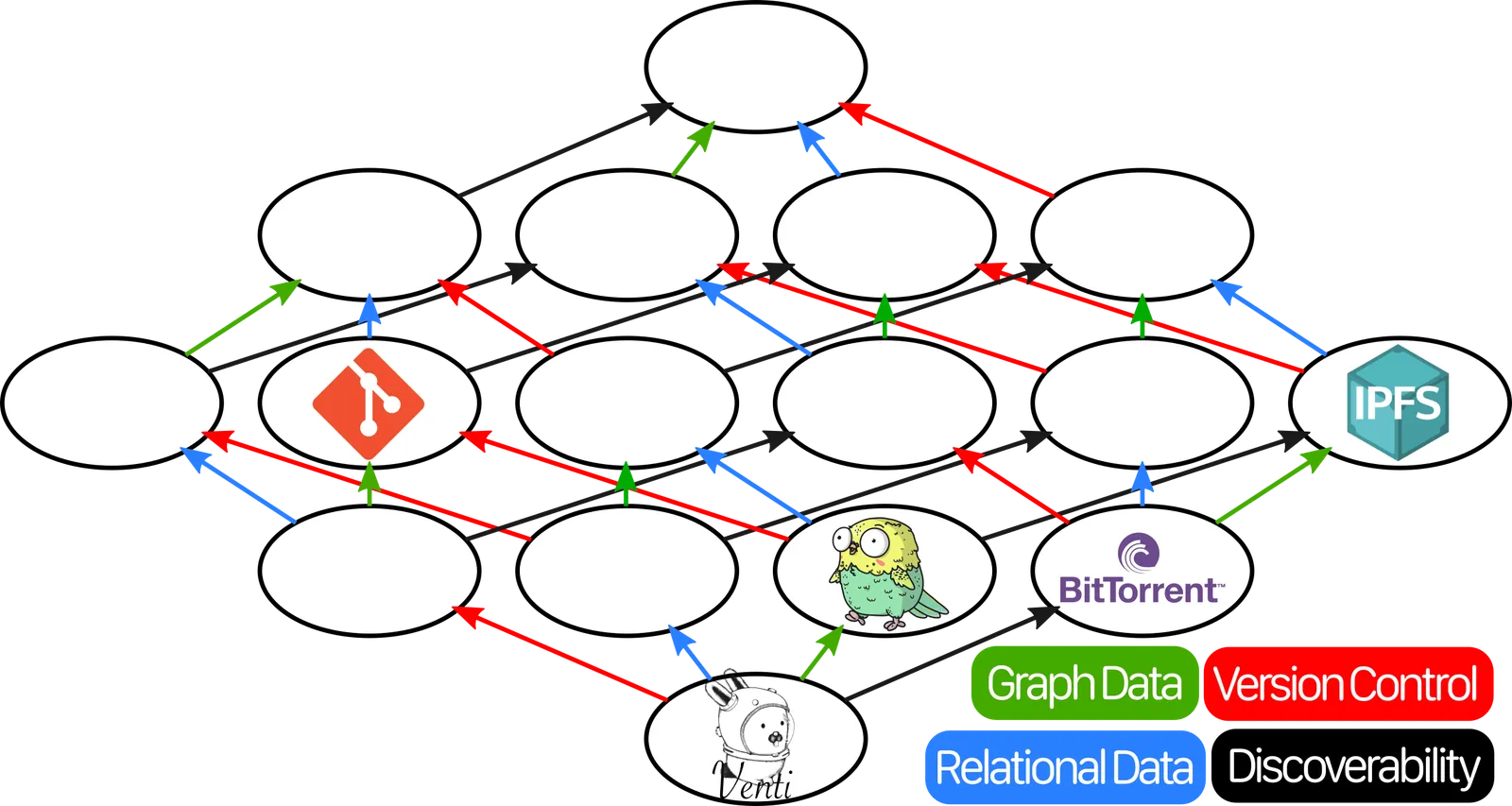
Lattices are neat because you can take all the elements and arrange them in a fancy little graph like this:

But it’ll probably be more clear to also make a Venn diagram like this:
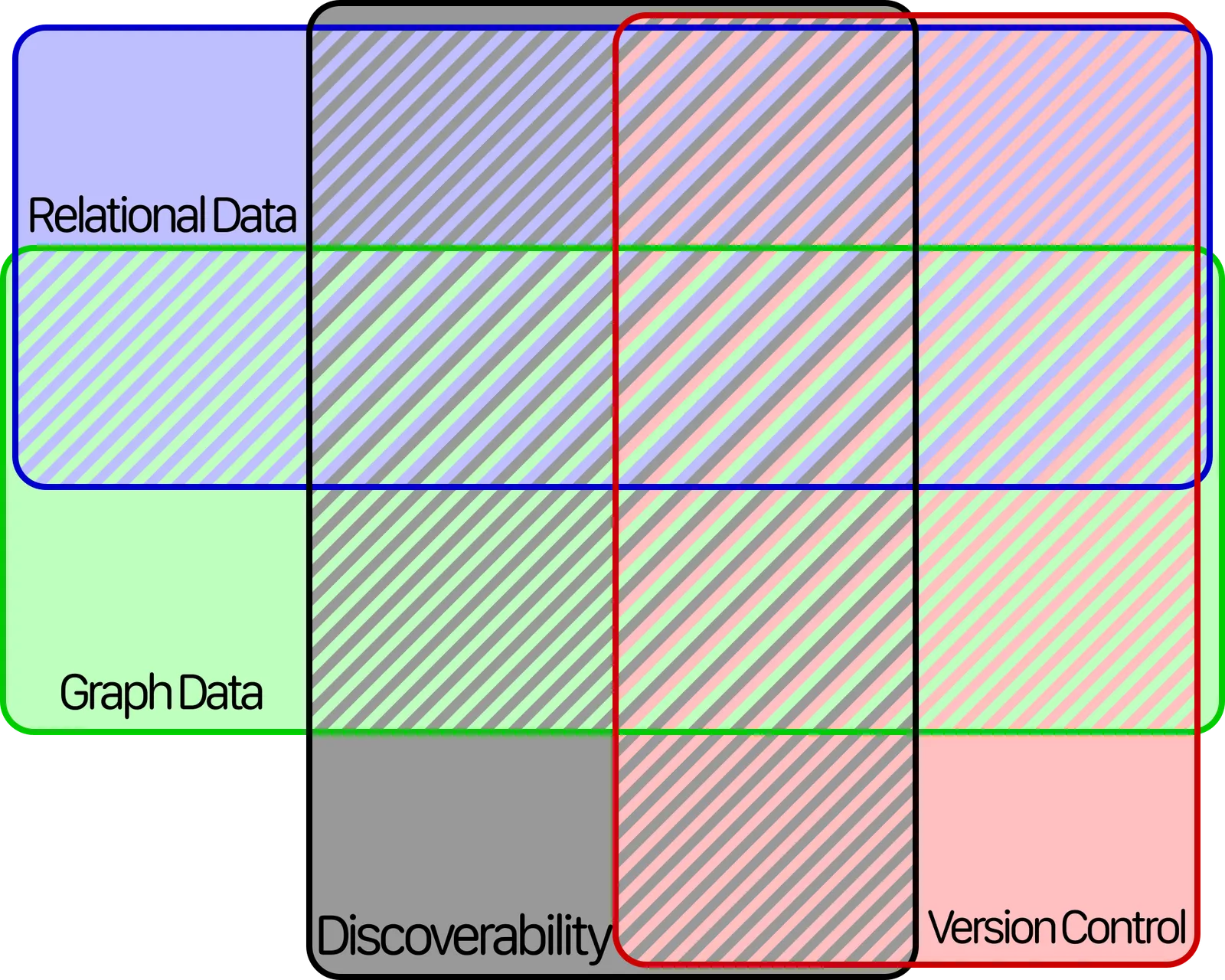
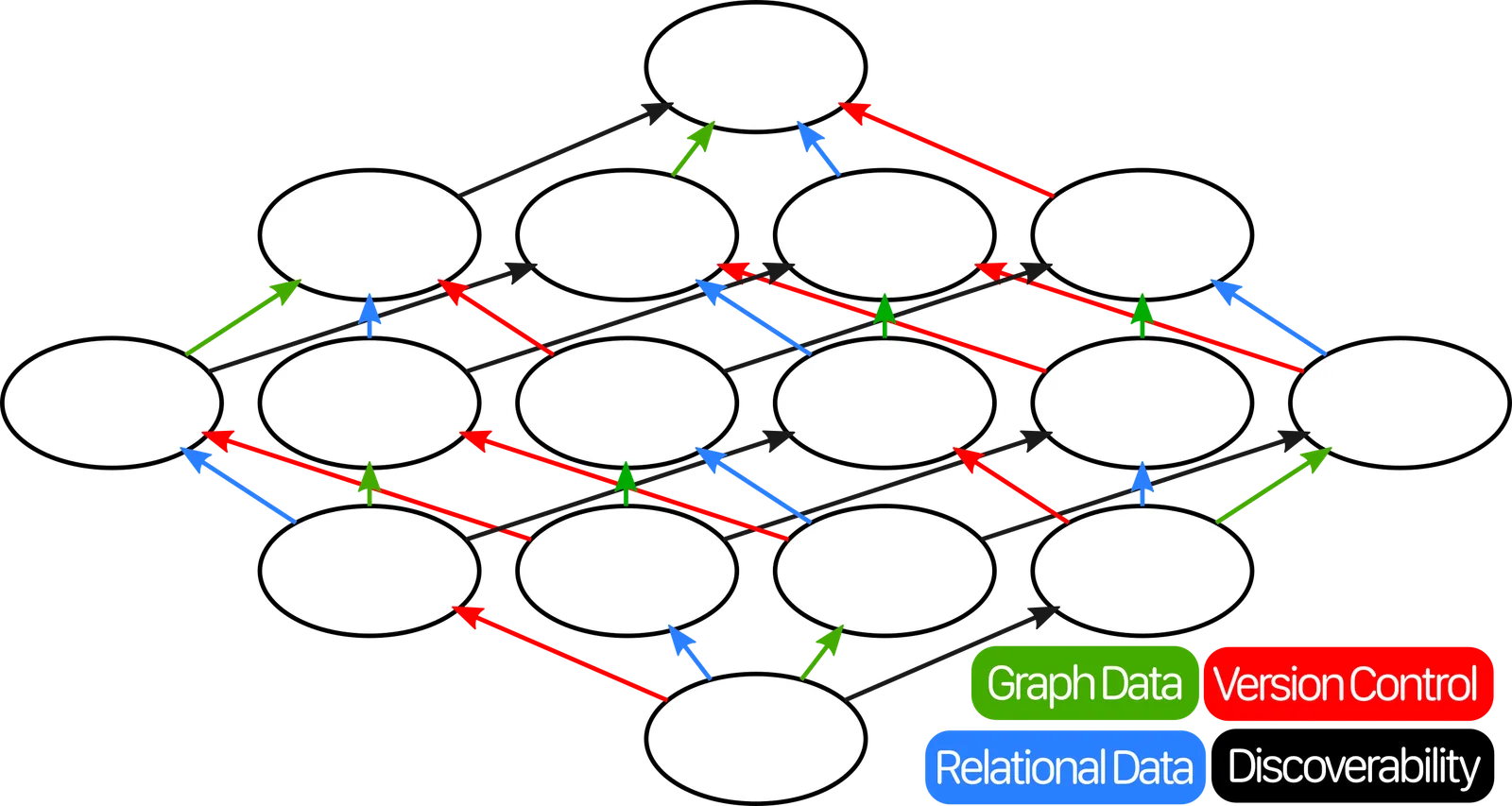
The only thing nerdier than the SQL Iceberg
There’s sixteen different ways to combine these atoms, and we have a space for each combination.
Each of the databases we’ve mentioned so far goes in a different spot on this chart. Venti, Perkeep, BitTorrent, and IPFS slot in like so:
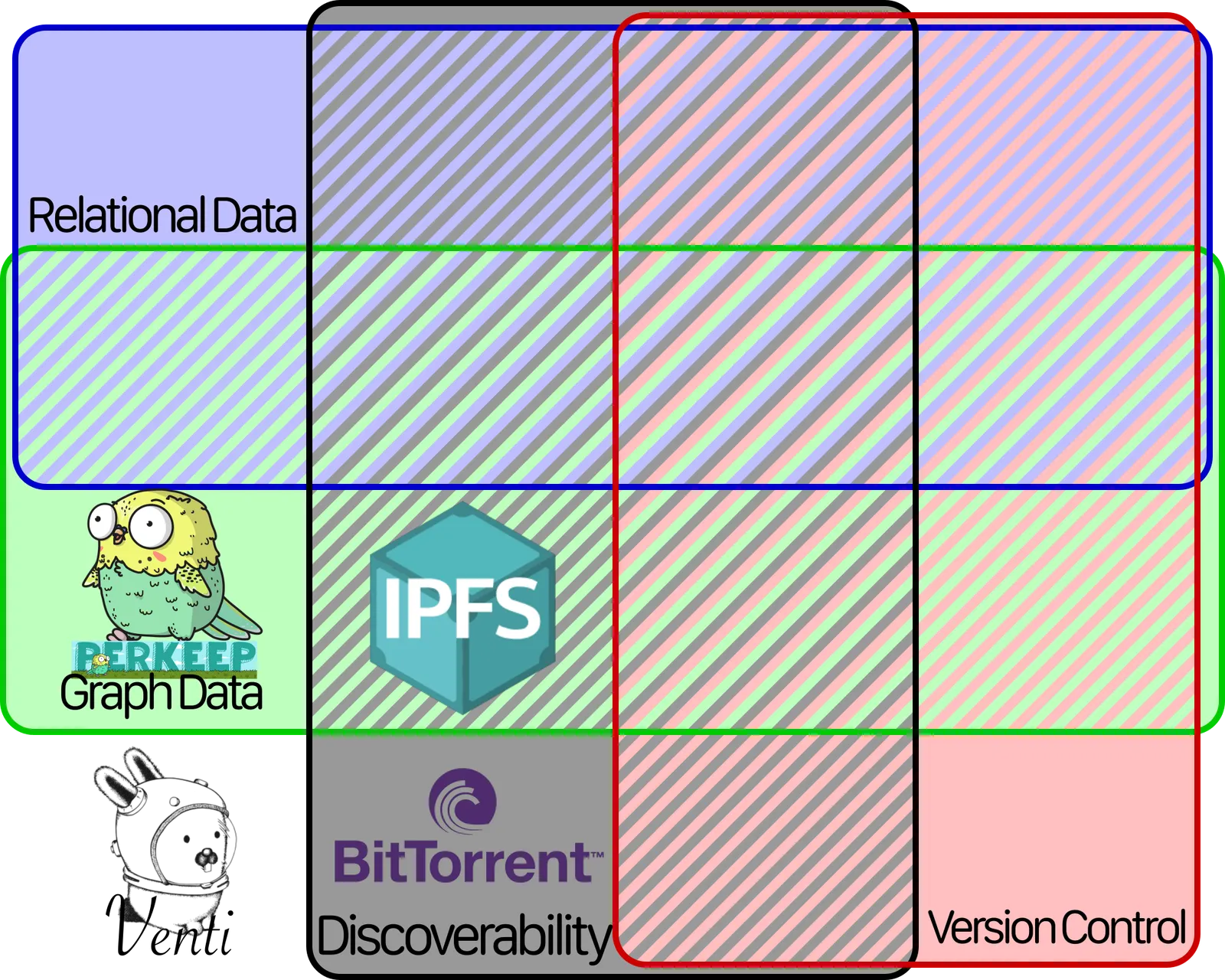
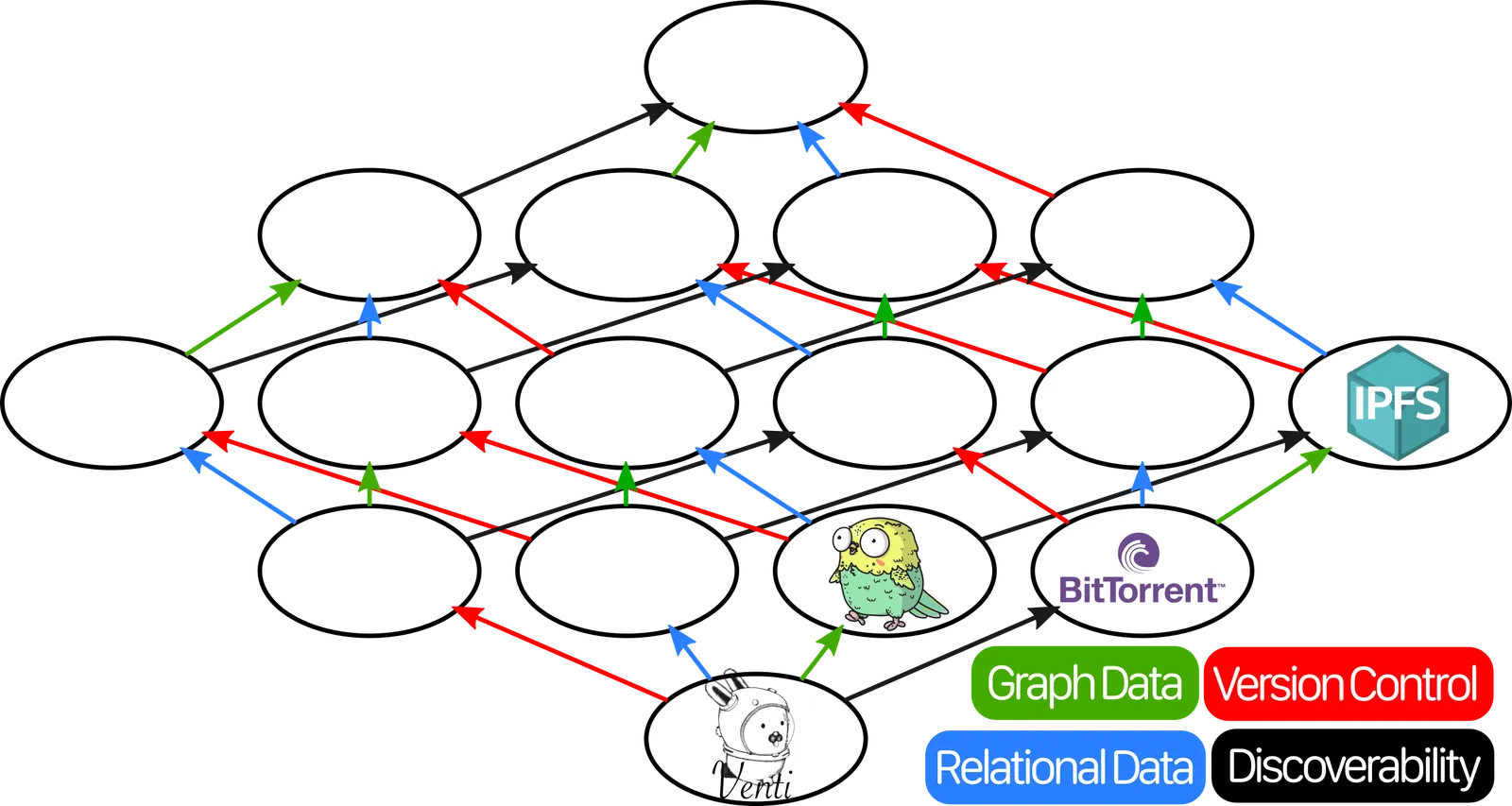
As previously mentioned, Git has Version Control. But it also has Graph Structure, because file systems are just graphs where files and directories are the nodes and edges. So we can add it to the chart like so:
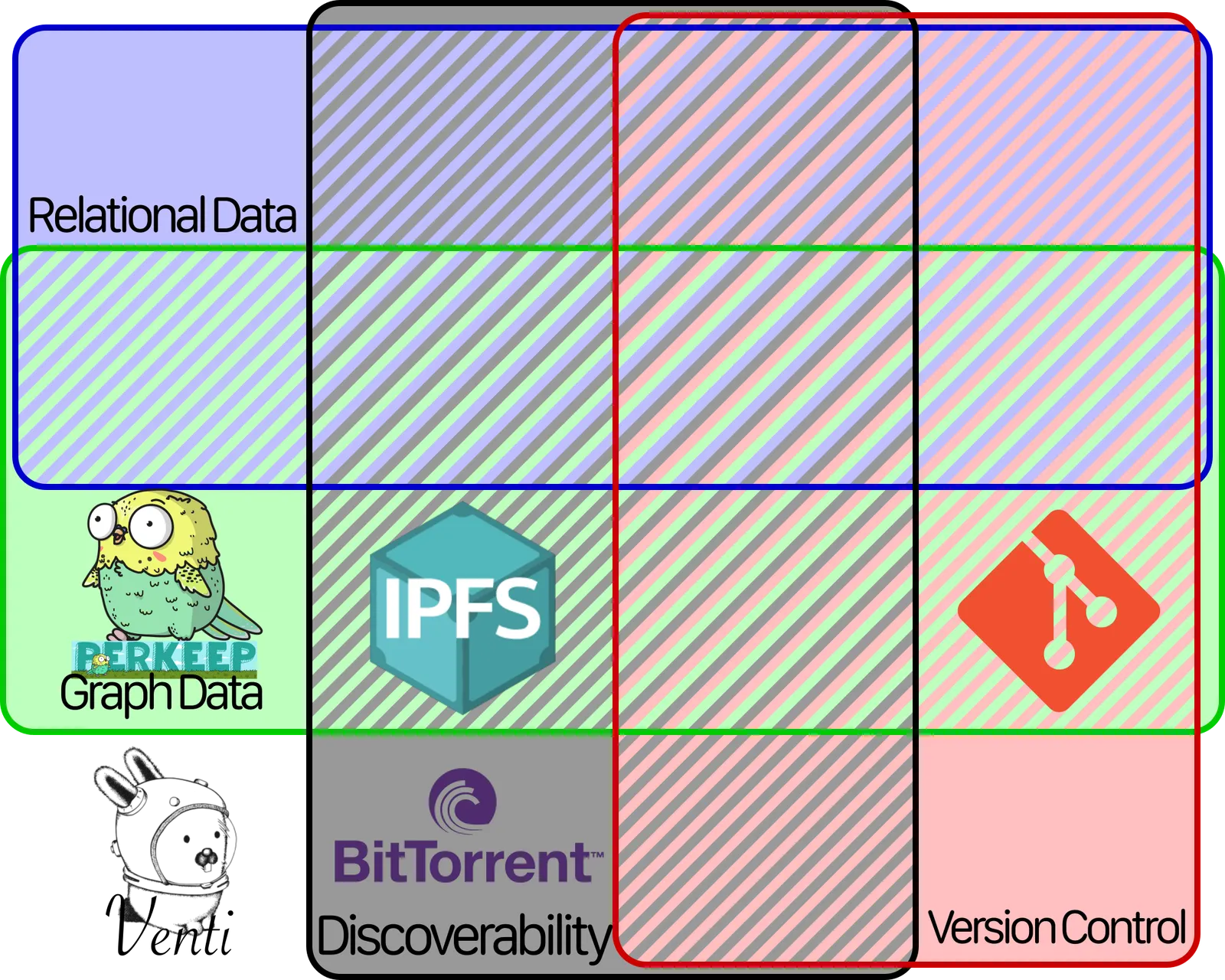
MySQL isn’t technically a decentralized data store, but we’re going to add it to the chart anyway. It only has one feature: Relational Data. It goes here in the chart here:
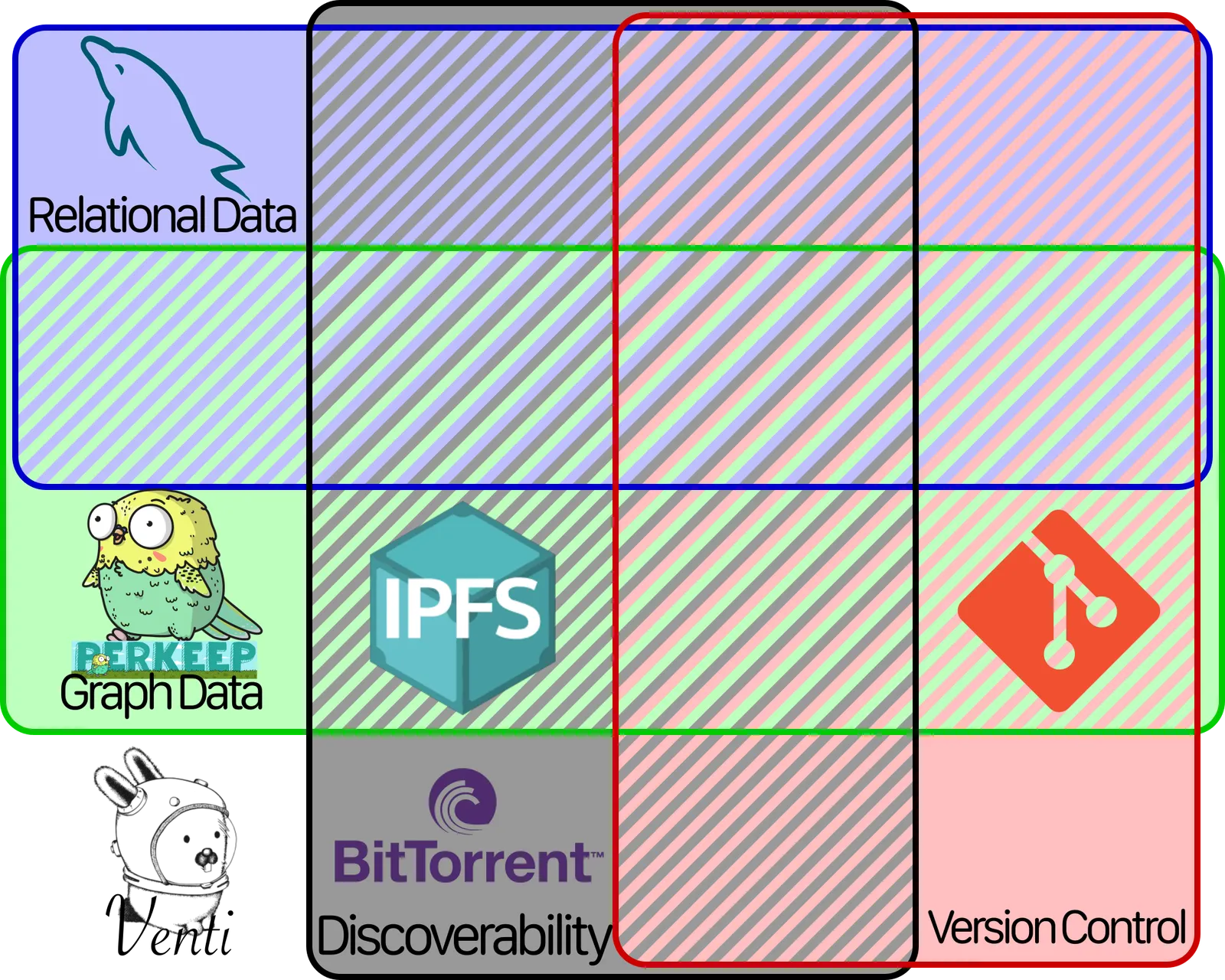
And Dolt has two features: Version Control and Relations. So it goes here:
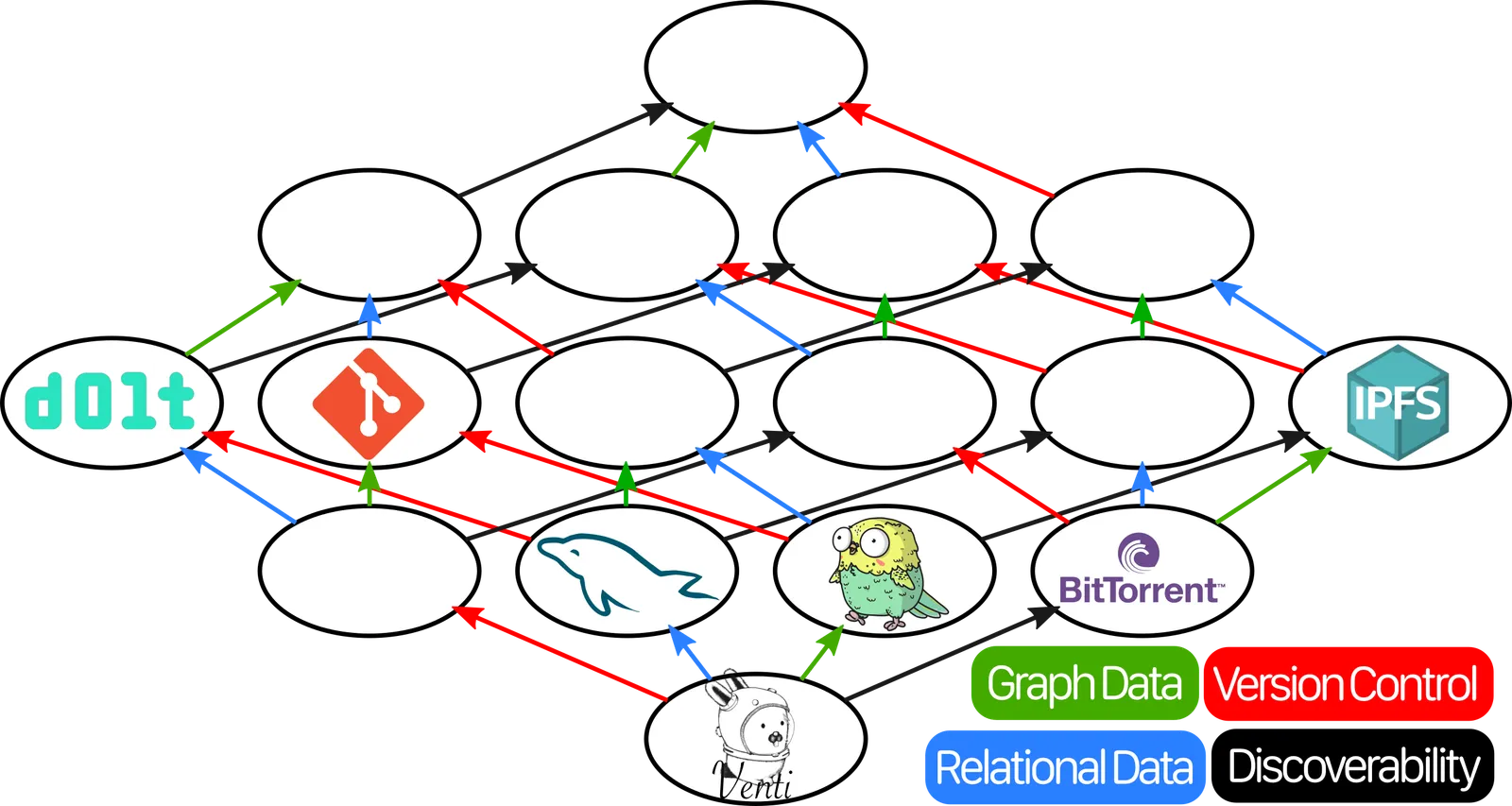
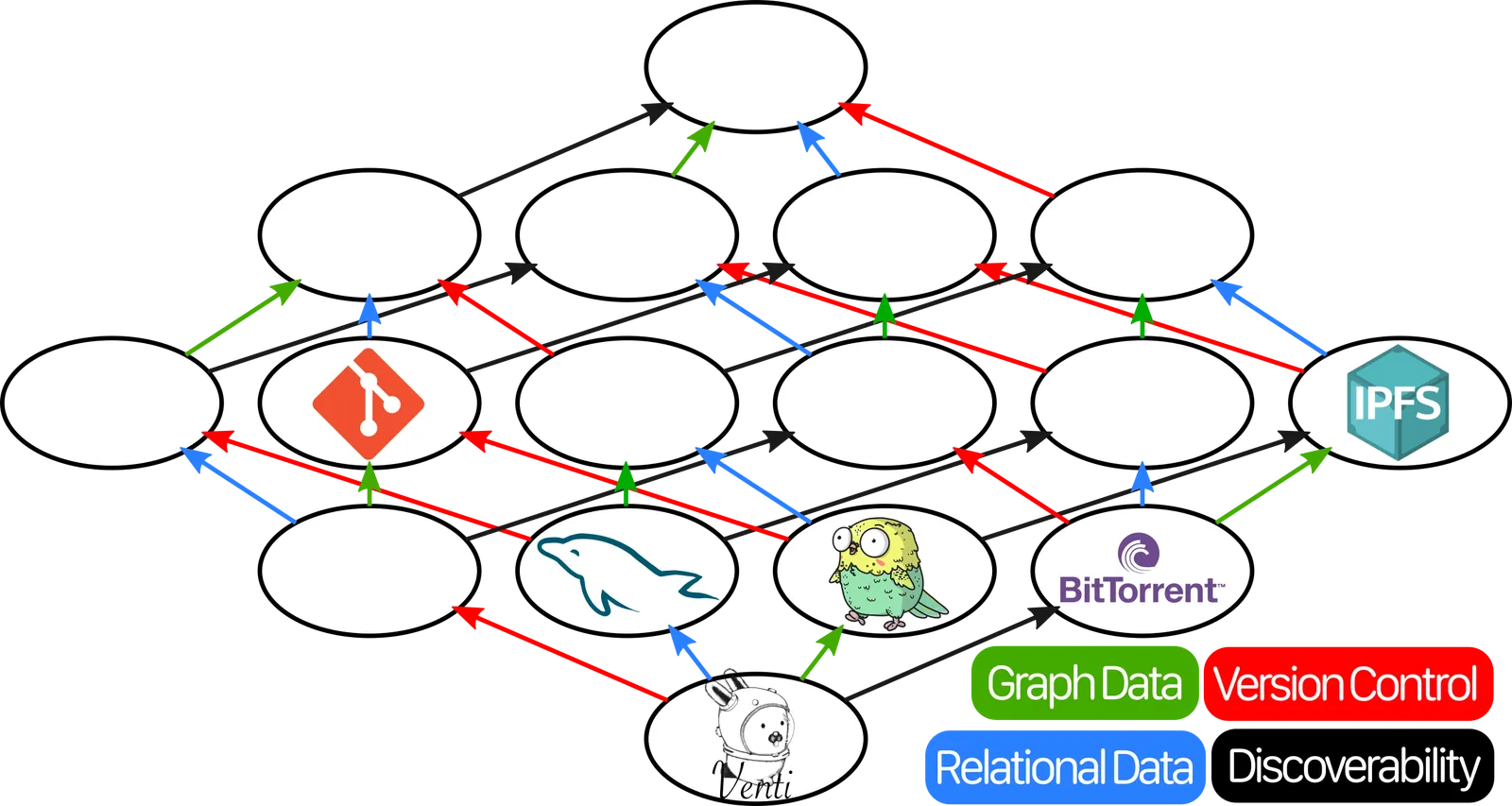
In order to add two items in the lattice, you just have to find the first item that can be reached from both of them by following the arrows. So Git + MySQL would be… this one:
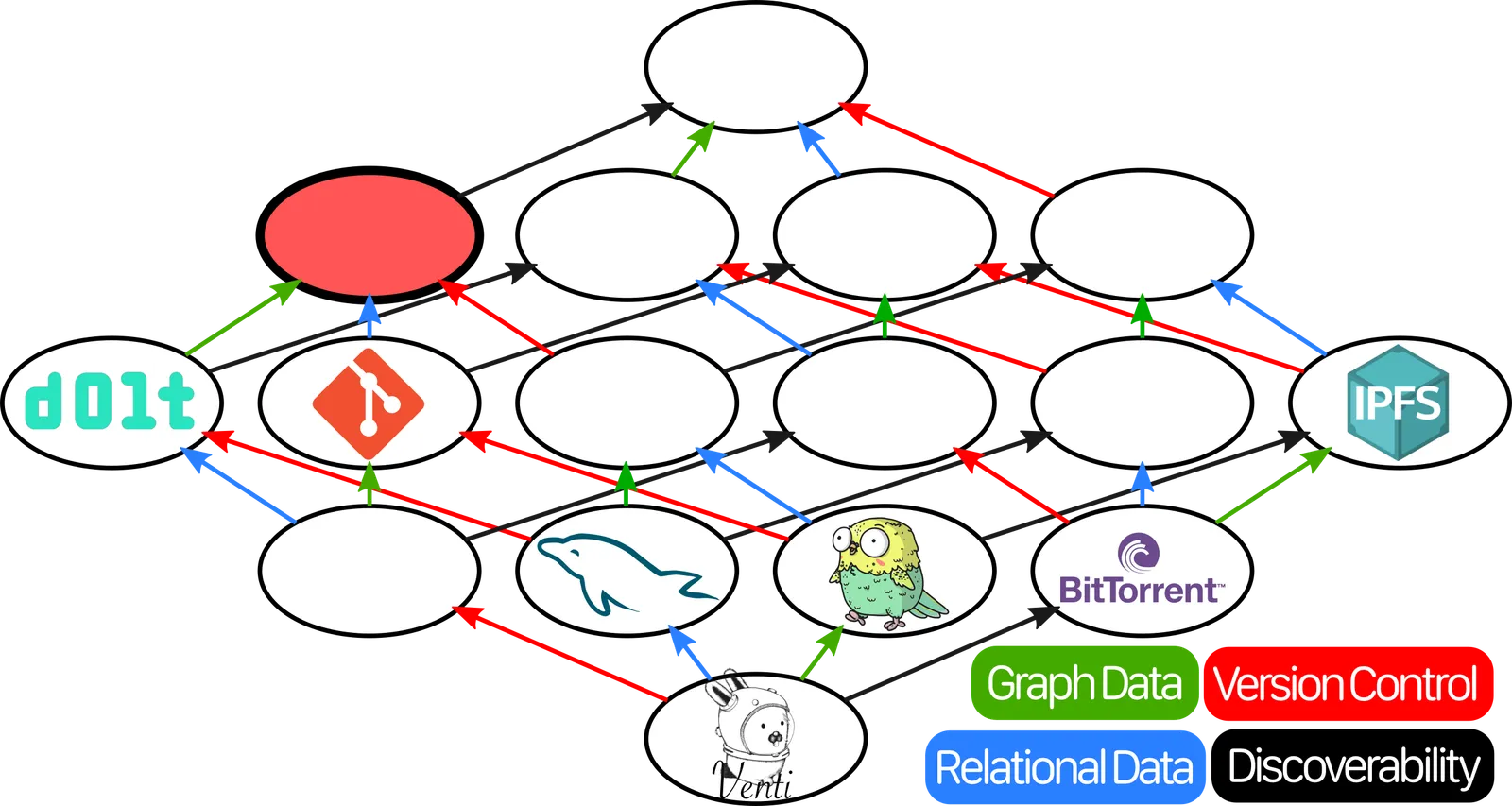
But that’s… not where Dolt is. Did we make a mistake somewhere? If we really wanted to say that Dolt is MySQL plus something, that something would be whatever goes in this spot:
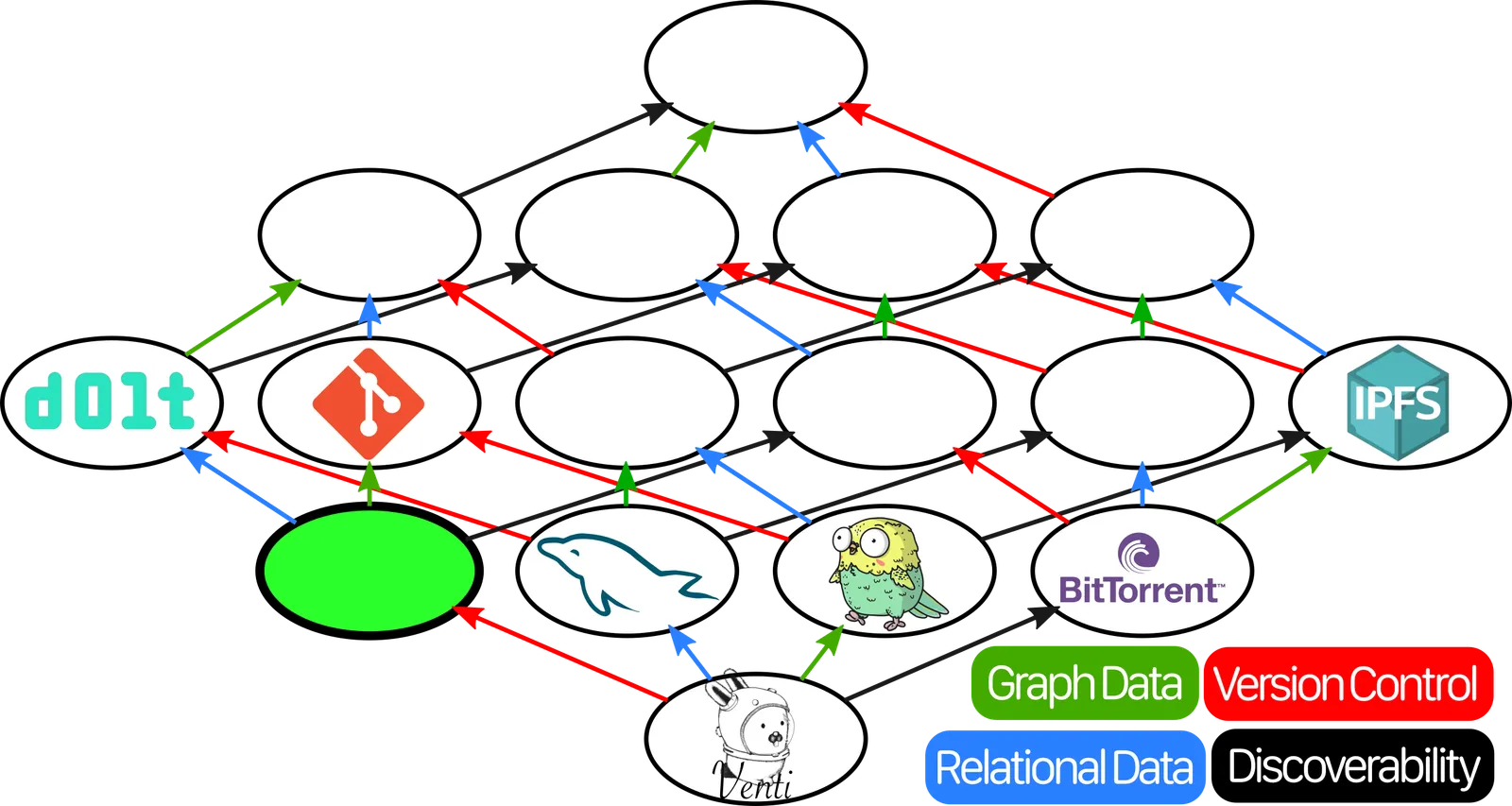
That spot corresponds to a hypothetical decentralized datastore that has Version Control, but none of the other features. Does there exist such a tool, with versioning but without graph structure or relational data? There actually does, but it’s a bit of a technicality!
I’m referring, of course, to the Docker Container Registry.
In Docker, container images are stored by the hash of their contents. You can tag them. You can version them. You can push them to and pull them from container registries. You can even (sort of) merge them by having a Dockerfile that FROMs multiple other images. But although docker images may contain filesystems, the datastore treats them more like opaque blobs.
So, does this mean we got it all wrong? Did we make a math error when we said that Dolt = Git + MySQL, and it would actually be more accurate to say that Dolt = Docker Container Registry + MySQL?
Hang on. I need to call Tim and tell him to change our front page.

Much better.
Let’s try to the best of our ability to fill every empty spot with a different existing program and see what happens.
The following is a short list of other distributed data stores and where they fit in the lattice.
BitTorrent + Docker Container Registry = Hyphanet#

Hyphanet, formerly known as Freenet, is a distributed datastore designed for hosting web content. Immutable content is content-addressed and can be queried by other nodes, just like BitTorrent. But the network can also index mutable content if it’s signed with a public key. Chunks can have a version number in their metadata, and chunks with a higher version number supersede lower version numbers (and the same public key.) Thus, data belonging to a specific address can change over time. This allows for both websites that can update over time, as well as more complicated applications like forums and chat rooms that use Hyphanet for storage.
In learning about Hyphanet, I was impressed by how it was possible to build complex apps on top of very simple primitives. Hyphanet has some other unique features too, like a routing algorithm that automatically organizes where chunks are stored in the network, such that chunks are easy to locate, and are replicated proportional to their demand. It’s an ingenious design.
It’s also quite old: Hyphanet was first released in 2000, two years before Venti, making it the oldest decentralized database I could find. This makes the fact that it’s still around and still seeing active use quite impressive. Unfortunately it’s also poorly documented, and difficult to develop for if you don’t intimately understand the cryptographic primitives it’s built on. That’s probably why its developers are in the process of replacing it with a more modern protocol called Freenet, formerly known as Locutus3.
- Tagline
- Censorship-resistant and privacy-respecting publishing and communication
- Properties
- Version Control, Discoverability
- Initial Release
- March 2000
- GitHub
- https://github.com/hyphanet/fred
Git + Queries = TerminusDB#

TerminusDB describes itself as Git-for-data, just like Dolt. But where Dolt is a relational database, TerminusDB embraces the graph and document approach of Git, extending it with support for multiple query languages, including a custom query language based on Datalog. It has a Git-inspired command line where you can branch, diff, and merge.
We were excited by TerminusDB a year ago, and we’re still excited by it today. It exists in a similar space as Dolt and solves similar problems, but does so its own way. I’ll be watching to see where TerminusDB goes from here.
Also Terminus has a mascot called the CowDuck, which feels very appropriate.
- Tagline
- Making Data Collaboration Easy
- Properties
- Version Control, Graph Structure, Queryable
- Initial Release
- October 2019
- GitHub
- https://github.com/terminusdb/terminusdb
Git + BitTorrent = Hyperdrive#
Hyperdrive is part of the Holepunch Ecosystem (formerly Hypercore Protocols, formerly Dat Ecosystem). It uses a B-tree constructed from append-only logs to represent a file system called a Hyperdrive. Each hyperdrive is identified by a public key, and a custom DHT is used to resolve keys to the corresponding file system. Since the underlying data structure is append-only, the drive also contains its entire history.
Hyperdrive is under active development on Holepunch’s GitHub and powers Holepunch’s peer-to-peer chat app, Keet. The main way to use it is via a command line tool called Drives, or third-party clients like Agregore
A related project is Sonar, an in-development third-party project to build queryable NoSQL databases on top of Hypercore and Hyperdrive. Their documentation does not currently define queries other than full-text searches.
Hyperdrive#
- Tagline
- A secure, real-time distributed file system designed for easy P2P file sharing
- Properties
- Version Control, Discoverability, Graph Structure, Queryable
- Initial Release
- December 2015
- GitHub
- https://github.com/holepunchto/hyperdrive
Hyphanet + Perkeep = GunDB, m-ld, and OrbitDB#
All three of these tools tackle the same problem: building an eventually consistent graph database on top of a distributed hash table by using Conflict-Free Replicated Data Types. CRDTs are useful because they guarantee that merge conflicts in a decentralized system can always be automatically resolved. Thus, all three also contain a queryable history of the data store’s state. This is similar to but not quite the same as Git’s model of version control.
GunDB#

- Tagline
- The database for freedom fighters
- Properties
- Version Control, Discoverability, Graph Structure, Queryable
- Initial Release
- January 2015
- GitHub
- https://github.com/amark/gun
m-ld#

- Tagline
- live ⦁ shared ⦁ information
- Properties
- Version Control, Discoverability, Graph Structure, Queryable
- Initial Release
- Pre-release, announced June 2020
- GitHub
- https://github.com/m-ld/m-ld-spec
OrbitDB#

- Tagline
- Peer-to-Peer Databases for the Decentralized Web
- Properties
- Version Control, Discoverability, Graph Structure, Queryable
- Initial Release
- May 2019
- GitHub
- https://github.com/orbitdb/orbit-db
The Final Taxonomy of Decentralized Data Stores#
After adding all of those tools, and removing MySQL because it’s not actually a decentralized database, the final chart looks like this:

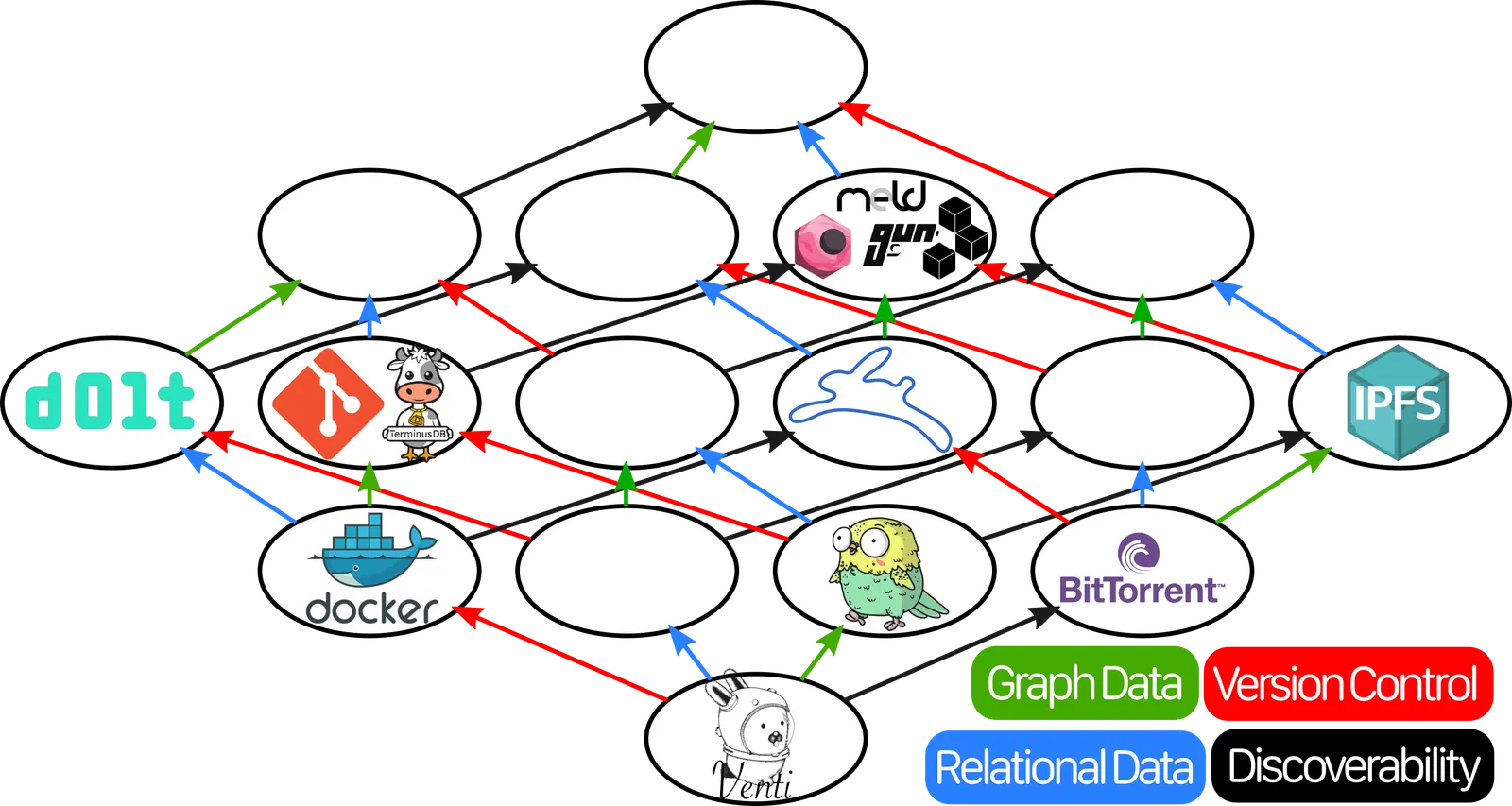
(Picture of the final chart and graph. Notably, nearly every item without “relations” has been filled in. But on the side with “relation”, Dolt stands alone.)
By comparing the relative position of two programs on this chart, we can instantly understand how they differ in their capabilities.
I think this chart speaks for itself, and gives us valuable insight into the current state of the ecosystem. Because while there’s a lot of very cool stuff here, there’s an obvious area of the map that’s almost completely uncharted. There’s an almost overwhelming number of decentralized databases leveraging graph data, but when it comes to relational data? It’s entirely uncharted, with one exception.
We often crow about how Dolt is the world’s first version controlled SQL database. But I think Dolt is actually even more special than that:
Dolt is the first decentralized database to use a relational data model, period.#
None of these other datastores support relational data as a first-class concept. There’s no reason why they can’t, but they don’t. And Dolt’s support for version controlling relational data is a major feature So why isn’t anyone else embracing it yet?
It could just be because Dolt is built on prolly trees, which are a relatively new invention. We are seeing more use of prolly trees though, including in some high-profile projects like BlueSky, and some lower-profile projects like Fireproof.
There’s been a clear shift toward decentralized applications that started around 2017. I don’t see that going away. More and more, applications are embracing an offline-first, trustless model for sharing data. And a lot of the data that we use is relational in nature. So perhaps we’re going to see more of these spots filled in in the future.
I really think that DoltHub has found something special. Bringing version control to relational data feels like stepping out the dark ages. We’re not going to be the only ones to do it.
Where’s It’s Going#
Since we went through all the effort of making this whole lattice, I’d be remiss to not at least ask:
What would the application at the very top of the lattice look like?#
This would be an application that has all four of these properties:
- It can store both relational data and graph data, including hierarchical data like file systems.
- It would be versioned controlled: the data can evolve over time, branch, diff, and merge.
- Users can discover the most recent value of a branch, even if they don’t know another user that has it.
Looking at how the other applications in the lattice combine some of these features, we can get a pretty good idea of how this could be done.
Relational and Graph data can coexist#
There’s no reason why Dolt couldn’t allow for storing both relational and hierarchical data. In fact, we have a feature for storing files in a Dolt repo, although we currently restrict it to just a single LICENSE.md and README.md. Conceptually, there’s no reason you couldn’t store entire file systems in Dolt, but given that Git already exists and is pretty good at that, adding support for that hasn’t been a high priority. We decided it was better to let Git be the “version controlled hierarchical data” tool and focus on making Dolt the best “version controlled relational data” tool it could be4.
IPFS shows us how to add discoverability to structured data#
IPFS uses Merkle trees to organize data: every leaf in the tree corresponds to a file, every non-leaf node corresponds to a directory, and every node is indexed in a distributed hash table by the hash of its content.
A similar application could add that discoverability to relational data if it swapped out the Merkle trees for prolly trees: users would be able to clone and replicate a database even if they don’t know anyone who has a copy. Users would also be able to clone and replicate individual tables/indexes/views, or even store and diff multiple snapshots of a database at different points in time without having to store the redundant chunks multiple times.
However, if users can only request databases from the DHT by their content-address, there wouldn’t be any way to get updates if the database changes. But the other tools we looked at today have solutions for that too:
Hyperdrive and Hyphanet shows us how to add discoverability to versioned data.#
Hyperdrive is pretty cool. To repurpose a particular slogan: it’s like if Git and BitTorrent had a baby. (I’d make a joke about “GitTorrent”, except that GitTorrent is real and does something similar.)
Hyperdrive works by using a public key to identify a file system. The file system is stored as a Merkle tree of chained commits, just like Git. However, every commit in the chain must be signed by the corresponding private key. Since they form a chain, any user who has one commit in the chain can request the rest from the P2P network, and any user who has all the commits can easily determine which one is the most up-to-date.
Hyphanet works very similarly: a piece of mutable content is linked to a public key, updates to that content are signed by a corresponding private key, and nodes in the network are a DHT that index content by a (key, version-number) pair and can serve the most recent version.
Again, there’s no reason why an application can’t swap out the Merkle trees for prolly trees and apply the same principle to relational databases. Imagine a variant of Dolt where:
- Commits could be tagged with metadata and signed by a public key.
- Instead of identifying a branch by a (remote-URL, branch) pair, you instead specify a (public-key, branch) pair.
- The network resolves that request to the single commit that:
- Has that branch name in its metadata.
- Is signed by that public key
- Has every other commit that matches (1) or (2) as a direct or indirect ancestor.
Heck, you could even implement this on top of Dolt and give it a really punny name, like Dhlt (still pronounced like Dolt, of course.)
To be clear, this is not something that we currently have any plans to implement. It’s a thought experiment. But Dolt is also an open source project, so who knows what it might get used for in the future. Knowing that the potential exists for new things to be built on top of Dolt gives me confidence that Dolt really does have a place in the future of the Internet.
Conclusion#
If anything, despite the 23 year history of decentralized databases, it’s clear that there’s still a lot more room for them to innovate and develop. And within the last couple of years, decentralized alternatives to traditional web platforms have begun to penetrate the mainstream, with Mastodon and BlueSky in particular getting widespread media attention.
Decentralized technology is still young, and every new protocol brings new approaches, new features, and new concepts. We’re still trying to figure out what works and what doesn’t. But the current landscape paints a very promising picture of the future.
Obviously, I’m biased toward Dolt. I think our focus on relational data brings something new and innovative to the table which will push the ecosystem forward in meaningful ways. But I’m just as excited with what others are bringing to the table as well. Ultimately, pushing the boundaries of the space benefits everyone: a rising tide lifts all boats.
What do you think? Hearing from the decentralized community is important. If you’d like to chat with us about the future of databases, come hang out on our Discord. You can also reach us on Twitter, or GitHub.
Footnotes#
-
For large files, the torrent gets divided into multiple chunks which are hashed separately and can be downloaded in parallel from different nodes. ↩
-
The metadata are themselves chunks, which contain a reference to the chunk that they modify. ↩
-
Yes, the new name of the new protocol is the same as the old name of the old protocol. Yes, it’s confusing. ↩
-
If you want to version control a combination of relational and hierarchical data, you can still run Git alongside dolt and store the commit hash for one in the other. ↩