
The term “decentralized” is mentioned more and more lately.
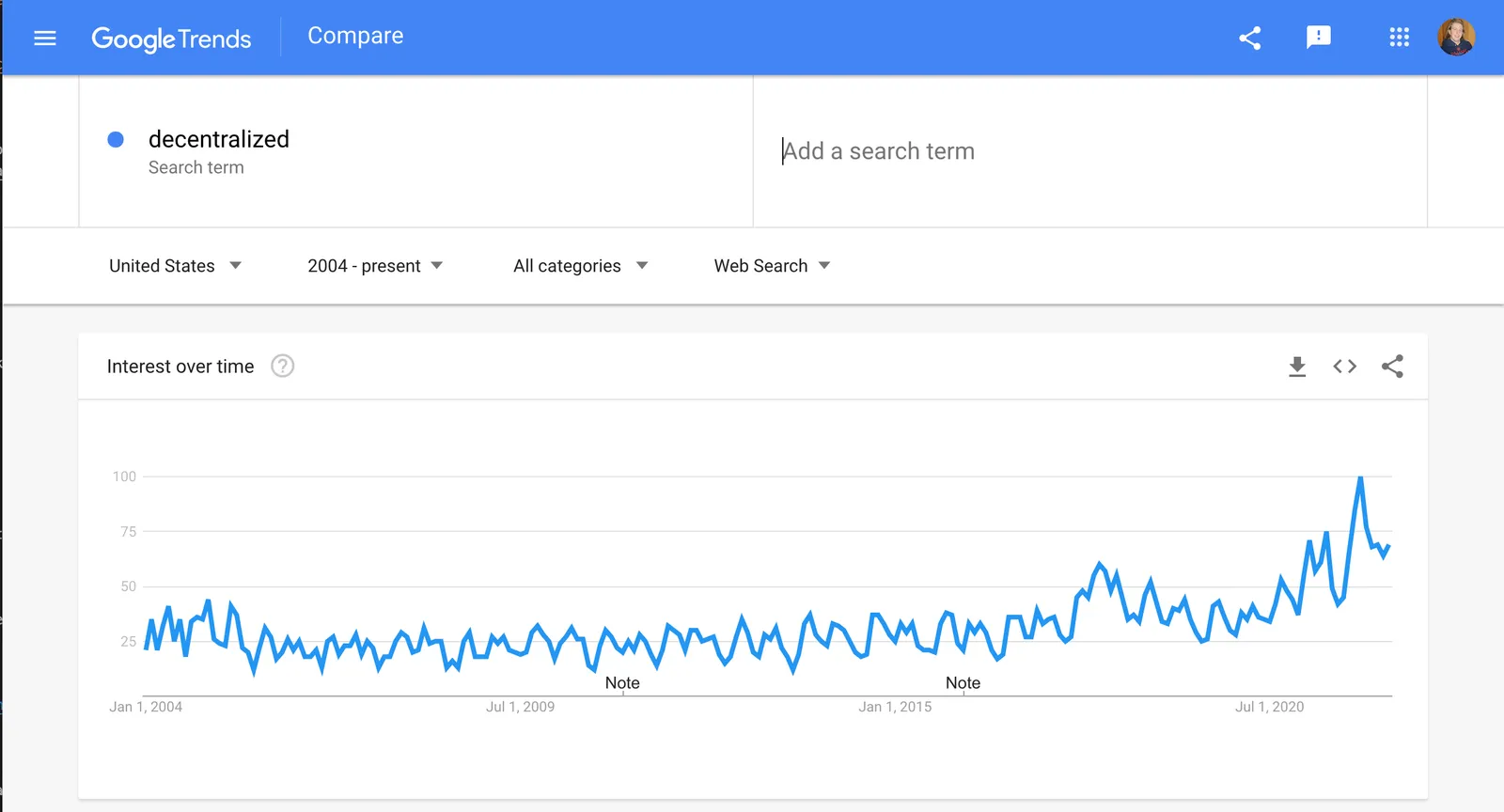
There’s been a 3-4X increase in google searches for the term since 2017 before which searches were relatively constant.
What is a Decentralized Database?#
A Blockchain is often referred to as a decentralized database. What do people mean when they say “decentralized database”? What are the core features of a decentralized computer system? Are all blockchains decentralized databases? Do other, non-blockchain, decentralized databases exist? This blog attempts to answer these questions.
What do you mean “Decentralized”?#
What does “decentralized” mean in the software context?
A decentralized software system has four key properties that build on each other.
- Offline first
- Sharing
- Fault Tolerant
- Trustless
From a user perspective, the choices the decentralized system makes in these categories defines your experience with the decentralized system. How is the accepted, “true” copy determined? Which node should you copy? How easy is it for you to maintain your own independent copy? How expensive is it for you to get your writes on the generally accepted, “true” copy? Who or what decides the accepted, “true” copy? What do you do if you get a bad copy? How often are there bad copies? Can an ill intentioned person mess up your experience?
Distributed software systems are not the same as decentralized software systems. However, a decentralized system is a class of distributed system. Distributed systems describe software where load is distributed among many computers. The key differentiating feature between distributed and decentralized systems is that in distributed systems, it is assumed that each node or instance in a distributed system is trusted. In a decentralized system, nodes can be owned by untrusted parties.
1. Offline first#

A decentralized system must be offline first. You must be able to create a new instance or node. Or, more commonly, you must be able to obtain a copy of an existing node in the system. Once you have a copy you must be able to read from and write to your copy. Offline first minimizes your dependency on the network or other nodes. This property is important because it allows for you to leave the system at any time and start your own “fork”, or competing system. Without offline first, you are subject to a central authority to make reads or writes. Offline first “decentralizes” the system. Without offline first, a decentralized system is called a “distributed system”.
2. Sharing#
Offline first is necessary but not sufficient for decentralization. A file on your computer is decentralized but not very much of a system. To become a system your instance or node needs to communicate with other nodes, individual actors in the system. How do nodes communicate changes? How do nodes agree which changes are valid? There are a bunch of different models of sharing in decentralized systems.
3. Fault Tolerant#
Decentralized software systems assume nodes can and will disappear without warning. These nodes will also reappear without warning. Nodes can try to publish stale or bad writes. Decentralized systems design methods for handling this type of activity from other nodes. Decentralized systems usually maintain some sort of list of active nodes. Moreover, decentralized systems usually maintain history so that bad changes can be reverted or nodes coming online can synchronize to the correct state.
4. Trustless#

Trustless means the system must be resilient to negligent or malicious nodes. This is slightly different than fault tolerant. In a distributed system where you control all the nodes, you often design against faults, like a server crashing. But you rarely design for a node “going rogue” and maliciously trying to break the system. You are in control of all the servers so you try to prevent that kind of attack upstream of the system using other security measures, like access controls. In decentralized software systems, you assume you do not have control of all the nodes and that some nodes may decide to try and “take over” or “destroy”. In order to achieve these ends, most decentralized systems use cryptography to identify users and data in the system.
The Decentralized Models#
Decentralized systems have adopted three general decentralized models based on product decisions on the offline first, sharing, fault tolerance, and trustless dimensions. The three general categories are:
- Blockchains
- Peer-to-Peer
- Git
1. Blockchains#
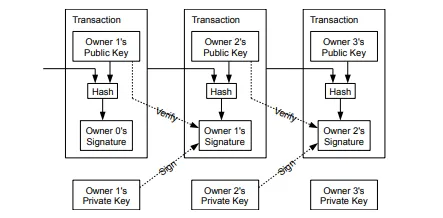
Blockchain is a particular flavor of decentralized, the most-hyped flavor, but not the only flavor. There are not many folks in the intended audience for this post that have not heard of Bitcoin or Ethereum, the two most popular public blockchains. A quick Google suggests there are over 1,000 public blockchains.
A blockchain is offline first. You can grab a copy of Bitcoin or Ethereum and start reading or writing to it. You can even initialize your own chain using the same software. You won’t be part of the consensus main copy (ie. mainnet) but there is nothing stopping you from forking at any time.
For sharing, fault tolerance, and trustless-ness, a blockchain generally uses a combination of transaction verification and identity. Most blockchains use longest chain combined with some sort of verification work, the most popular being proof of work or proof of stake, to determine the version of the system to recommend as trustworthy.
Getting a little more detailed, you must make transactions with a cryptographically provable identity. The funds to finance the transaction must be tied to this identity. Combining economic incentive for transaction verification with consensus effectively means there is one source of truth in the decentralized system that most people agree on. You have to pay to write to the chain, sometimes a lot, so you don’t want to request bad writes or else you’ll pay anyway and they won’t be persisted.
Blockchains are vulnerable to takeover by rogue nodes. If you get enough nodes to agree that your new state is the source of truth you can effectively take over the chain. Blockchains defend against this through scale. If everyone on earth was running a blockchain node, getting a majority percentage of them to agree on anything but the truth would be hard. So, the more nodes in the blockchain system the more fault tolerant and trustless it becomes.
2. Peer-to-Peer#
Peer-to-Peer (P2P) decentralized systems rose to popularity in the late 1990s as a way for people to share music and eventually all media on the internet. The decentralized nature of the system allowed for copyrighted material to be shared over the internet amongst individuals, leaving copyright holders with the only recourse to sue individuals instead of a central authority. Suing every individual who shared a music file for $1 proved untenable.
Systems of this type still exist, the most popular being BitTorrent. However, shifting focus more in the database direction, there is Dat and IPFS.
In a peer-to peer network, each node maintains a subset of all the data in the network locally on its computer. You also maintain a list of peers. When you want data you don’t have you ask your peers to send it to you.
The system is offline first. You can read or write data to your own node without being connected. Sharing is added through the peer list and request mechanisms of the network. Nodes can disappear and reappear without warning and the system will reroute you to another node that contains the data you want. The system prevents malicious actors mostly by being append only. Once data is in the system it will stay in the system until it is evicted from all nodes.
3. Git#
![]()
Finally, we have the Git model of decentralization. Git is an extremely popular decentralized version control system used to version files. It is mostly used to version source code. It was invented by Linus Torvalds, the creator of Linux, the popular open source operating system, in 2005.
In the Git model, each node maintains a copy of the files and all of the history of each file. Thus, the node can make reads and writes of all past revisions offline. When a node wants to share changes, it specifies a “remote”. The node can then send its state to that node, called “push”, or receive new state from it, called “pull”. Writes are organized on branches. Git is designed to compute differences between versions quickly. Generally, Git relies on human action to share and merge changes.
Fault tolerance and trustless-ness are achieved via the separation of remotes from individual nodes. Each node in the network is maintaining it’s own copy, its history and coordinating via one or many remotes. If a remote you trust gets corrupted, you have the ability to roll back to a previous good state and switch to a new remote. Even if you lose your copy you can rely on other nodes’ copies to restore from. Compared to Blockchain, the Git model of decentralization requires more trust but not complete trust.
What do you mean “Database”?#

A database obviously must store data. A file can be a database. However, databases are usually defined by their query capabilities. How easy is it to retrieve one of many small pieces of data within the overall whole? How big can the data be? Does the data need to be structured or unstructured? What query capabilities do you need?
In the context of decentralization the answers to the above questions matter more because there are trade-offs between how big an individual node in a decentralized system can be and how decentralized the system can be in practice. For instance, from the Ethereum documentation:
Ethereum itself can be used as a decentralized storage system, and it is when it comes to code storage in all the smart contracts. However, when it comes to large amounts of data, that isn’t what Ethereum was designed for. The chain is steadily growing, but at the time of writing, the Ethereum chain is around 500GB - 1TB (depending on the client), and every node on the network needs to be able to store all of the data. If the chain were to expand to large amounts of data (say 5TBs) it wouldn’t be feasible for all nodes to continue to run. Also, the cost of deploying this much data to Mainnet would be prohibitively expensive due to gas fees.
As the size of the node gets larger, you effectively limit the number of people who can maintain a node to those that can afford a hard drive that big. This centralizes control of the system to nodes which can afford big hard drives.
Decentralized Databases#
As you can see, the search for a decentralized database gets complicated rather quickly. There are a number of products on the market that have attempted to answer the above questions in different ways.
In 2017/2018, there was a Cambrian explosion of products in the space. Many did not survive. Here are the list of decentralized databases I researched for this article that seem to be dead or near dead. If you have alternative information about the state of these products, please let me know.
| Product | State |
|---|---|
| TiesDB | Last release March 31. Roadmap on website not updated past 2019 |
| BigchainDB | Last release 2020. Not much code since then. |
| ChainifyDB | Haven’t tweeted since 2020. Not open source. |
| CovenantSQL | Website not updated. Last Github commit of code 3 years ago |
| Postchain | Code updated 11 months ago. |
| ProvenDB | Last code 2 years ago |
For each decentralization model outlined above, I’ll start by explaining some products I excluded. Then, I give a brief description of the databases in the space.
The Blockchain Model#
To be considered a database, I think you need to be able to store data unrelated to the system in question. Thus, I’m going to ignore Bitcoin and all other currency focused blockchains.
I’m also going to ignore all other smart contract blockchains other than Ethereum. From my research, other smart contract based blockchains offer different trade offs between level of decentralization and transaction throughput. Some use proof-of-stake instead of proof-of-work to do transaction verification, which Ethereum is switching to. For the purposes of this article, if you’re interested in using Ethereum as a database, know that you have a number of other options that make different trade offs and thus have different characteristics.

Ethereum#
- Tagline
- Home to digital money, global payments, and applications
- Initial Release
- July 2015
- GitHub
- https://github.com/ethereum
Ethereum is a very popular blockchain implementation that allows users to store application code on the blockchain, called smart contracts. These applications are executed when they are involved in a transaction.
A distributed application can in theory store 2^256 bytes (keys) x 32 bytes (values) or ~63 petabytes. However, each read and write from a distributed application costs “gas” to incentivize the miner to execute the transaction. The amount of gas you need to pay is proportional to the amount of work required to execute the transaction, which includes reads and writes to the chain.
Thus, storing data on the chain is in practice extremely expensive. So, you could think of Ethereum more like a really expensive, small, public, low throughput database that is extremely secure and immutable. If you need a database with those properties, Ethereum is for you. You could use it for storing really important pieces of small data.
So, what if you want to access to or store more data in your smart contract? People are working on this problem, the most popular being Chainlink which is another blockchain to provide secure access to data off Ethereum.
All this said, Ethereum is more akin to a decentralized computer than a decentralized database. If you want a to store lots of data or use a query language, Ethereum is probably not the tool for the job.
Filecoin#
- Tagline
- Decentralized storage network designed to store humanity's most important information
- Initial Release
- July 2014
- GitHub
- https://github.com/filecoin-project
Filecoin is a popular decentralized file storage system. Filecoin is built on top of IPFS, a peer-to-peer file sharing system discussed later. Filecoin and IPFS are maintained by the same company, Protocol Labs.
Filecoin has designed a consensus algorithm called “proof of spacetime” that forces miners to prove they stored a chunk of a file over a certain amount of time. This sits on top of the peer-to-peer storage network, IPFS, to provide economic incentive to store files in the system. The Filecoin spec gets pretty dense. I encourage anyone interested to dive in.
Filecoin has been around since 2014 and has proven very reliable. Moreover, Filecoin and other IPFS implementations are often the format Ethereum and other smart contract blockchain users use to write large data on the chain. This is because data can be compressed down to a single hash and that hash can be used as an address.
But, is Filecoin a database? There is no query language. You need to know where to find files stored. I would call Filecoin a decentralized file system, a global hard drive with token economics driving storage reliability. I think one would build a database on top of something like Filecoin using Filecoin as the storage layer.
Arweave#
- Tagline
- Store data, permanently
- Initial Release
- June 2108
- GitHub
- https://github.com/ArweaveTeam/arweave
Arweave is an interesting decentralized file storage system. The idea is that you pay for “permanent” storage upfront. The interest off your upfront investment is used to pay the computers which store your data and which verify your data is still stored. You pay enough upfront that the interest is enough to fund the storage in perpetuity. This is all managed via a built in currency, the Arweave token.
Technically, Arweave claims that their system is not a Blockchain but a “Blockweave”. The chain is constructed using a “recall block” where the computer appending to the chain, and thus earning new tokens, must have the “recall block”. This encourages miners to store as many blocks as possible. Behind the blockchain mechanism is a Peer-to-peer storage network. So, Arweave is a hybrid blockchain/peer-to-peer decentralized system much like Filecoin.
Arweave is very cool. Using token economics to power a permanent web is an inspiring mission. Like Filecoin, I don’t think Arweave could be called a database. It is a decentralized file system.
KwilDB#
- Tagline
- Decentralized Database Solutions
- Initial Release
- Not yet released
- GitHub
- https://github.com/kwilteam/kwil_db_v2
KwilDB is brand new and not yet released. KwilDB is building a familiar SQL database on top of a decentralized filesystem, in this case, Arweave.
The idea is to use the decentralized filesystem as the storage layer of the database and add a familiar structured data query layer on top. In KwilDB’s case, they have chosen SQL. KwilDB is written in Javascript, so it can be run in browser.
Conceptually, I find KwilDB’s approach novel. Treating a decentralized blockchain-based file storage system as an “always on” hard drive for your database could be game changing for some applications. I hope to see more products born in this space.
The Peer-to-Peer (P2P) Model#
I’m going to ignore Dat and BitTorrent. Dat seems to be waning in popularity. BitTorrent is immensely popular but has more of a consumer rather than database feel. I could be wrong so if you think you’re looking for something like IPFS, feel free to dig into BitTorrent yourself.

IPFS#
- Tagline
- Powers the distributed web
- Initial Release
- February 2015
- GitHub
- https://github.com/ipfs/ipfs
IPFS, short for Interplanetary File System, is a decentralized peer-to-peer network to store files. Like Filecoin, it is maintained by Protocol Labs.
IPFS is much like other peer-to-peer storage networks with one key technical difference. IPFS chunks up a file on ingestion and then cryptographically signs each chunk. These chunks are built up in a Merkle Tree and given a root address. This allows files to change without having to store a whole new copy of the file on the network for every change. This innovation effectively allows for more efficient storage on the network.
IPFS is an extremely popular protocol used by a number of projects. The protocol supports Filecoin, a very large blockchain. I would expect it to continue to grow and thrive.
Is IPFS a database? Again, this is more like a decentralized file system. You can build a database on top of it but it’s not a database.
OrbitDB#
- Tagline
- Peer-to-Peer Databases for the Decentralized Web
- Initial Release
- May 2019
- GitHub
- https://github.com/orbitdb/orbit-db
OrbitDB is a database built on top of IPFS! OrbitDb offers a number of different database types: log, feed, key value, document, and counter.
OrbitDB used Conflict-free Replicated Data Types (CRDTs) as a core structure on IPFS. These data types restrict what type of data can be stored in a database but prevent merge conflicts when multiple writers try and coordinate. OrbitDB is written in Javascript so it can run in the browser.
OrbitDB is very young and promising. It supports many different database use cases, the most complex being a document store. We look forward to seeing how the project progresses.
Gun DB#
- Tagline
- The database for freedom fighters
- Initial Release
- Unclear
- GitHub
- https://github.com/amark/gun
Gun DB has the most radical website of the products I surveyed. Gun DB is still hosted under an individual’s GitHub account, amark, and gives off extremely strong open source vibes (in a good way).
Gun DB is a graph database and claims support for “SQL-like tables, JSON-like documents, files and livestreaming video, plus relational and hypergraph data”. Gun DB also uses CRDTs to prevent conflicts. It is written entirely in Javascript.
Gun DB is incredibly popular. It has 16k stars on GitHub. The documentation is extremely extensive. If you’re looking for a decentralized database with very strong open source vibes, check out Gun DB.
The Git Model#

Git#
- Tagline
- Fast, scalable, distributed revision control system
- Initial Release
- April 3, 2005
- GitHub
- https://github.com/git/git (mirror)
Git invented the Git model of decentralization. Git is ubiquitous, spawning multiple multi-billion dollar companies. I’m pretty certain anyone who made it this far in this opus, knows Git and probably uses it every day.
But is Git a database? The versioning target of Git is files. Like Arweave, Filecoin, and IPFS I think Git is more akin to a decentralized file system than a database. People have even tried to build databases on top of Git with mixed results.
Terminus DB#
- Tagline
- Making Data Collaboration Easy
- Initial Release
- October 2019
- GitHub
- https://github.com/terminusdb/terminusdb
TerminusDB brings the decentralized Git-model to graph and document databases.
TerminusDB has full schema and data versioning capability. For graph databases the interface is a custom query language called Web Object Query Language (WOQL). WOQL is schema optional. TerminusDB also has the option to query JSON directly, similar to MongoDB, giving users a more document database style interface.
The decentralization syntax is exposed via TerminusDB Console or a command line interface. The metaphors are similar to Git. You branch, push, and pull.
TerminusDB is young and just getting started. If you want a Git-style decentralized graph or document database, check it out.
Dolt#
- Tagline
- It's Git for Data
- Initial Release
- August 2019
- GitHub
- https://github.com/dolthub/dolt
Dolt brings the Git-style decentralization model to a traditional SQL database. The versioning target is tables not files. You can branch, clone, push, and pull for sharing.
You can run Dolt offline using the command line or online by starting a server. The Dolt command line matches Git exactly. Dolt is MySQL compatible. You create tables, insert data, and read data using standard SQL. You cannot run Dolt embedded (ie. in the browser). Dolt works like a traditional database server.
We’re biased but we think Dolt is an interesting option in the decentralized database category. Hearing from the decentralized community, we understand the embedded use case is important. If you’d like to see embedded Dolt or have any other questions about decentralized databases, feel free to come discuss on our Discord.