
All software is terrible, as we all know. But some software is more terrible than others.
Why is that? What is the property that makes some software frustrating or confusing to use? And more importantly, what is its opposite, that elusive quality where applications do what we want, when they get out of our way and just work? Why is that such a rare quality, and can we figure out how to get more of it?
The principle of least surprise#
These aren’t new questions. Software has always sucked, and we’ve always been trying to figure out why we’re so bad at our jobs and how to do better. (We’re still trying.)
One early formulation of good design was that software should behave “as expected”. This notion became known as the Principle of Least Astonishment, or as I prefer, Least Surprise. It first appeared in print in 1967, and got this formulation in 1972 in the context of language design:
For those parts of the system which cannot be adjusted to the peculiarities of the user, the designers of a systems programming language should obey the “Law of Least Astonishment.” In short, this law states that every construct in the system should behave exactly as its syntax suggests. Widely accepted conventions should be followed whenever possible, and exceptions to previously established rules of the language should be minimal.
Eric S. Raymond agrees with this idea and pushes it one step farther, arguing that any novelty in interface design is likely to hinder your application and frustrate users:
Novelty is a barrier to entry; it puts a learning burden on the user, so minimize it. Instead, think carefully about the experience and knowledge of your user base. Try to find functional similarities between your program and programs they are likely to already know about. Then mimic the relevant parts of the existing interfaces.
Once you notice this principle you start seeing it everywhere. For example, there’s no law dictating that electronics gear must use red for the positive lead and black for the negative, but this convention is so universally understood and applied that violating it would be truly shocking (in some cases literally).

So the principle of least surprise can be thought of as a healthy respect for convention and existing knowledge. It invites us to empathize with the users of a program, to consider what previous experience they bring to the table and how that colors their expectations about what “should” happen when they invoke some particular feature.
Ok, but what if I’m trying to build something novel?#
Astute readers will have picked up that the above advice would seem to preclude trying truly new things in interface and product design. Where is there room in this philosophy for Xerox PARC, for git, for Apple and Nintendo?
An easy rejoinder is: you’re not building one of those things, you’re building a B2B enterprise SAAS offering or baiting zoomers into clicking on display ads 0.3% more often. But let’s engage the premise and say that you are in fact on the cutting edge of innovative design. How do you apply this advice? Look to the masters.

Hopefully it’s uncontroversial to state that Nintendo innovates more than other big game companies, especially when it comes to hardware. But when Nintendo released the Wii, the best-selling home console of its generation, it packaged its novel motion control features in a controller that could be turned sideways and used like an NES controller, or plugged into an included attachment and used more or less identically to other game controllers of the era. The system OS was a glorified mouse-driven interface. And the first, most popular motion control games were isomorphic with real-world motions like swinging a tennis racket or throwing a ball.
Apple likewise is recognized for contributing an outsized amount of innovation in software and hardware. But when Apple released OS X to great fanfare, the killer feature, the reason that every engineer in your office uses a MacBook instead of a Thinkpad, is that they built a great GUI on top of 40 year old Unix standards. You already knew how to use the terminal because you used RedHat at work. And that GUI, while it did have innovative features, was itself built on top of three decades of windowed desktop metaphors that were well understood at the time of release.

As for git, before it conclusively won as the only version control software anyone uses anymore unless they’re being paid to use a different one, early users were often stymied and perplexed by its model and interface. Message boards and blogs from that time were absolutely bursting with complaints from people who didn’t understand the model or how to use it to do simple things. In point of fact, you could argue a clear majority of git’s current user base has a very fragile and surface-level understanding of the product.
But: Git did win. The features it provided were so useful that people were willing to put up with a very steep learning curve to get them. But even then, there’s an alternate universe where GitHub never took off, and another DVCS like Mercurial came to dominate instead.
So in most cases, innovative designs lean very heavily on what came before them, providing new users with familiar toeholds they can stand on to take advantage of the truly novel features. Products that didn’t take this approach succeeded despite it, not because of it, and they’re the exceptions.
But what about the novel part of my product#
It’s true: even in the B2B SAAS offering you’re building, there’s still room for true innovation. You must be offering something new, some novel set of capabilities that don’t exist elsewhere. (You are, right?) You need to provide your customers a way to use those capabilities, and the design you choose should make sense without them having to pore over dozens of pages of documentation to learn how. You can and should lean on existing familiar patterns: e.g. your website should have buttons that look like buttons and links that are underlined, and your web service should communicate with REST or gRPC or JSON, not a new binary format you invent. Or sometimes you can hide your unique selling point entirely on the backend away from prying eyes, just a better, faster version of what’s come before. Either way, you’re mostly copying and adding flourishes, not creating from scratch.

But sometimes, when you’re developing something truly novel, this approach isn’t enough. You run out of easy wins at the interface layer by copying what people already know. If you’re lucky enough to be in a role with this responsibility, the principle of least surprise still applies, but it takes on a wilder, more interesting character.
What do you do when you’re in truly uncharted territory? How do you make your product familiar and unsurprising without the crutch of copying existing interfaces?
Coherent product design#
When you’re in the enviable position of building something truly new, you can still apply the principle of least surprise by thinking about your product’s features in terms of coherence. Coherent products have features that fit together, so that once you understand how one aspect works, you automatically understand how other aspects work, and you aren’t surprised by their operation. Rather than relying on familiarity with what came before, you’re relying on one or more design metaphors, a consistent mental model of what the product is for and how it works, that teaches your users how to use an increasing surface area as they experiment and learn.
My claim is that all less-terrible software has the property of coherence in its design. It’s the special unifying property possessed by all software that “just works”.
As an example, let’s return to git, which I just claimed confused many users. But despite git’s interface being pretty confusing at first, it’s a coherent product, organized around a rock-solid metaphor. Once you understand the underlying metaphor of the commit graph, once that clicks, all of the commands you had been typing suddenly make sense, and you can branch out into ever more esoteric parts of the interface safely and confidently. This is a hallmark of coherent products: learning one feature makes it easier to learn others.

Designing a product for coherence often feels more like discovery or exploration than true creation. You start with your set of metaphors and follow them to their logical conclusions: this is true, therefore this must be as well. You discover how new features must work, rather than inventing them from whole cloth.
Let’s look at some examples from our experience writing some truly novel software.
Case study: session management in Dolt#
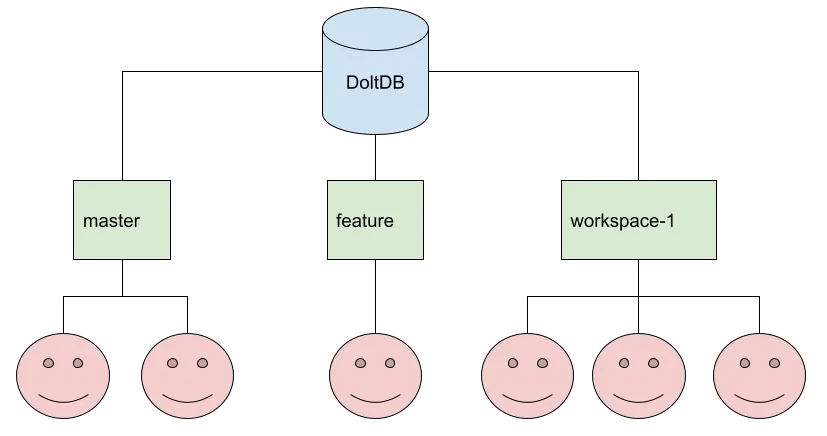
We’re writing Dolt, a SQL database that you can branch, merge, fork, clone, push and pull like a Git repository. If you’ll allow us a moment of hubris, we think this is truly novel software. We’re the first people in the world to build something like this.

But precisely because this software is so novel, that makes it that much more important for us to stick to the principle of least surprise, to lean heavily on conventions and interfaces customers are already familiar with. That’s why we chose to model dolt’s command line interface on git’s, so that every Git command you already know works exactly the same for Dolt. For the same reason, we chose SQL for the query language rather than inventing our own (specifically MySQL, just because it’s still the most popular free SQL database, although Postgres continues to gain ground). So the product is modeled after two familiar interfaces: it behaves like Git or MySQL does, in every case.
But Git isn’t a multi-user online database, and MySQL isn’t version controlled. What happens when we combine these two guiding metaphors? We get a compatibility matrix that looks roughly like this:

This is a vast and pretty interesting design space for us to explore. So pretty early on, we set in stone some basic metaphors about how version control should work in a SQL context:
- Version control read operations are accessed via special system tables, e.g.
SELECT * from dolt_log - Version control write operations are accessed via procedure calls, e.g.
CALL DOLT_COMMIT('-am', 'added rows') - You connect your session to a particular HEAD with a special
DOLT_CHECKOUT()procedure, analogous to usingGit checkoutto change branches with Git. - You read from a different HEAD than the one you’re connected to via the AS OF syntax,
SELECT * FROM myTable AS OF 'myBranch'
These guiding principles gave us ready answers for how we should implement version control primitives in the context of SQL. But there was one issue that proved much thornier than others: transaction and session management.
Dolt started as a command line tool that let you import and version control datasets, then grew into a SQL database over time as more customers asked for this functionality. So to begin with, there was really only a single user session possible and no transaction management to speak of — the last write would win. That’s obviously not tenable for a real database, and as we continued to focus more on the OLTP use case we had to develop new metaphors for how to expose dolt’s multiple branch heads in a SQL context. We released our first real implementation of transactions a little over two years ago, and it taught us a lot about how the product should function in a multi-user environment.
Unlike normal SQL databases, a Dolt database has multiple heads (one for each branch), and users can choose which one to connect to when they establish their session. Each branch can have any number of concurrent users working on it simultaneously.
One issue that came up immediately during design had to do with how the checkout command should
work in the SQL context. A Git repository only has a single client, and you change branches in it by
running the git checkout command. When you change branches in Git this way, you “take your
changes with you”: any uncommitted changes on the initial branch are applied to the new branch.
% git status
On branch zachmu/virtual-cols
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
modified: go.mod
no changes added to commit (use "git add" and/or "git commit -a")
% git checkout main
M go/go.mod
Switched to branch 'main'
Your branch is up to date with 'origin/main'.
% git status
On branch main
Your branch is up to date with 'origin/main'.
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
modified: go.modSo here, the uncommitted changes to go.mod are carried with me from the zachmu/virtual-cols
branch back to main. On the command line, Dolt implements a command called dolt checkout that
works the same way, because it copies Git. In the SQL server, there’s likewise a way to change the
branch you have checked out, CALL DOLT_CHECKOUT(..). But what should happen to uncommitted changes
when this procedure is invoked on a running server?
Let’s consider our metaphors and think about how Dolt must differ from Git because of its multi-user model.
| Git repository | Dolt SQL server |
|---|---|
| Single user. Repo’s file system state is effectively a single long-running, persistent session | Many users, and each has their own session state |
| Set of uncommitted edited files is by definition local to a user, since there’s only one | Set of uncommitted edited tables is shared by everyone editing a branch. |
Single working set, which is just the contents of the file system outside the .git directory | One working set per branch — there must be, so that different users can have uncommitted changes on different branches simultaneously |
Thinking through these models and their consequences makes it clear that checkout must behave
differently in the context of a running server.
- In git, when you run
git checkout, uncommitted changes aren’t “left behind” on the branch you’re leaving. This is because there’s only one working set, it’s not specific to the branch. They “come with you” to the new branch. - In dolt, when you call
dolt_checkout(), uncommitted changes (not yet committed to the branch head) must be “left behind”, because they are shared by any clients connected to that head. They can’t “come with you” to the new branch for the same reason: that new branch has a working set that’s being edited by other clients, we can’t just overwrite it.
So dolt_checkout() can’t make changes to the working set in either the source or destination
branch, because that would mean one client’s session-local commands affect other, unrelated
sessions. Because Git is single-user and doesn’t have a strong concept of a session, it never had to
confront this issue. This conclusion surprised us, and took a lot of careful thought and
experimentation to confirm, but it’s definitely the correct behavior.
At the time we discovered this necessary break from Git behavior, the assumption of a single working set with git-like semantics was deeply baked into every layer of the codebase. Unwinding these assumptions and building new ones in was a months-long slog. Confronting these inconsistencies and fixing them was a necessary precursor to shipping our first true concurrent transaction model, and these new metaphors served us well for another couple years.
But they didn’t last forever.
Case study: branch-qualified databases, USE, and checkout#
Sometimes, despite your best intentions, you end up introducing two conflicting metaphors and must resolve the conflict to restore coherence.
During integration work with a customer, we discovered that Dolt was having trouble playing nicely
with a Django connection library. In particular, we wanted to control which branch head the Django
ORM connected to in different contexts. At the time, the normal way to connect to the branch you
wanted was to connect to the database, then issue a call dolt_checkout('myBranch') command. But
the ORM framework didn’t provide an easy hook for us to insert this procedure call as part of
connection initialization, and we didn’t want customers to have to do this when writing their
applications. We realized that many client libraries were going to pose similar challenges. We
needed a better solution.
The answer we came up with was branch-qualified database names. Instead of connecting to myDb
and then running call dolt_checkout('myBranch'), you could simply connect to myDb/myBranch in
the first place. This solved the problem in a really elegant and simple manner, not only for the
Django ORM but all the other client libraries we were testing at the time as well. Everybody was
pretty happy with it.
But over time, we came to understand that we had opened a can of worms by introducing this
feature. The ramifications of this new feature were surprisingly far reaching, and ended up
overturning the transaction model that had served us well for a couple years. The reason had to do
with how the USE statement works in MySQL.
Since myDb/myBranch is a database name like any other, then the following SQL statements are
equivalent according to the language specification:
USE `myDb/myBranch`;
insert into myTable values (1,1);
...
insert into `myDb/myBranch`.myTable values (1,1);The first form of INSERT statement is just shorthand for the second: when you fail to qualify a
table with the name of its database, MySQL (and most other databases) just fills it in with the name
of the current database. So far so good. But when used in dolt, these kinds of INSERT or UPDATE
statements behaved unpredictably, editing a different branch than the user was expecting or dropping
edits completely. Customers were hitting this bug and getting confused. But why was this happening?
It turned out that the feature of branch-qualified database names had invalidated our previous metaphors and we hadn’t noticed, giving rise to the bug. The original design used the following metaphors:
- A Dolt SQL session is like a Git client session. It’s tied to a particular branch, and you can
only change that branch with calls to
dolt_checkout(). Unqualified database names resolve to this tracked branch. COMMITis like saving a file you changed somewhere in a Git workspace, but with ACID / transactional semantics baked in. At transaction commit time, Dolt updates the working set of the tracked branch with your session changes.- Because you can’t “take your changes with you” when you switch branches, if you try to call
dolt_checkout()with a dirty session, the database rejects the call, forcing you to either commit or roll back the current transaction before changing your tracked branch.
Branch-qualified database names broke this session management metaphor. We couldn’t get rid of them — not only were they a great solution we all liked, but customers were using them in production. Our only option was to fix the bug, to make the product’s behavior coherent again, but this was easier said than done.

Here are some solutions that wouldn’t work:
- We couldn’t add a SQL engine hook to
USEstatements to check out a different branch — this wouldn’t stop people from using the branch-qualified name directly in statements, which we must support because of SQL. - We couldn’t make branch-qualified databases read-only, since they were being connected to by client libraries like Django that expected writes to work.
- We couldn’t refuse to resolve branch-qualified names in certain contexts, or resolve them differently in different circumstances — this would be massively inconsistent with the SQL language, where a given name always means the same thing in a session.
All of these little inconsistencies all pointed to the same conclusion: our metaphor and model for tracking session state was just wrong. We were stuck in the metaphor we borrowed from git, which doesn’t have to worry about multiple heads being edited at once, let alone multiple clients doing the editing. So we updated our metaphors:
- A Dolt SQL session doesn’t track any particular branch, but records which branches you’ve
changed. Calling
dolt_checkout()just changes what branch an unqualified database name resolves to. - At transaction commit time, Dolt commits changes to any branch edited by the session.
- You can always call
dolt_checkout()even if your session is dirty, since it just changes how unqualified database names resolve.
These were massive, fundamental changes to the transaction model that were difficult to
accomplish. Dolt has tens of thousands of tests, many of which relied on the assumptions of the old
model, and many hundreds more were needed to evaluate the rigor of the new solution. Starting the
project I joked that every time I wade into the transaction code it’s a 3-week project, but by any
honest accounting it took at least twice that long. More than once I declared victory to be at hand
and my giant PR ready to review, only to discover an edge case that caused me to go back to the
drawing board on some aspect of the model. I’m not even mentioning some of the thornier aspects of
the SQL implementation, such as the GRANTS table or the information_schema database. The above
bullet points look so neat and tidy in retrospect, but the truth is I had to discover them by
bushwhacking, one swing of the mental machete at a time.
But I’d be lying if I said I didn’t enjoy it. Exploration and discovery are fun.
Conclusion#
We’re still not done: today it’s an error to change more than one branch in the same SQL transaction because the lowest layer of our storage code can’t support that yet. But that’s what the logic of the model demands, so that’s where we will eventually end up. We’re holding off on that work for now, because no customer is asking for it (yet).
Coherence is a framework I use frequently when we’re designing new features for our database, and it’s been very useful whenever we can’t lean on copying Git or MySQL directly. And thinking of our database as an inevitable fact of nature whose properties we discover rather than invent not only cuts through arguments, it produces a coherent product that “just works” the way our customers expect. And it’s pretty fun.
Like the article? Have questions about Dolt? Come say hi and chat with our engineering team on Discord. We look forward to hearing from you!