
Great art is never truly finished, only abandoned. And great, living software is the same way. It’s never done, but always in a state of constant flux between additions and rewrites. Software engineers are a curmudgeonly sort, and sometimes we like to pretend that there’s something exceptional and onerous about a particular project when, months or years in, we realize we’ve painted ourselves into a corner and have to change something fundamental. If only we’d done things the right way, we lament, this wouldn’t have happened. This seems especially true when we didn’t start the project ourselves, but inherited it from a bunch of artless amateurs who didn’t know what they were doing.

Total bollocks. The fact is, software development never proceeds in an orderly fashion from first principles, with all major details planned out correctly ahead of time. Even in the impossible case where all requirements are known and fixed from the beginning, it’s fiendishly challenging to anticipate and account for all of the purposeful and incidental complexity you introduce in the course of development. And in the real world, your requirements and environment shift underneath you as fast as you build. You have to adapt to things not in the original plan.
There is only one known exception to this principle.

Aside from certain wizened masters of the field, software isn’t really built from plans, like a house or a ship. It’s accreted, the way an oyster grows its shell, new parts tacked onto what’s already there as expedient. This is true even when a single individual writes something, but applies doubly to the back-and-forth churn that is the reality of team development, and especially open-source development. We don’t have to love it, but the wise among us accept it even as we fight against its inescapable pull.

Still: there comes a terrible moment, when you realize that you’ve pushed your codebase as far as it can reasonably go, when changing requirements and entropy have conspired to bring you do a dead end. You can’t make what you have work. No matter how you contort what’s on the page, no matter how you abuse and torture your existing interfaces, they aren’t fit for the task you’re now asking them to perform. And in that awful moment you realize: you’ve painted yourself into a corner. It’s going to be a lot of work to get out.

This is the story of finding myself in such a corner, and getting out again.
From command line tool to multi-user database#
Dolt is Git for data, a SQL database that you can
fork, clone, branch, and merge. When we wrote Dolt, we were trying to
bootstrap a two-sided data marketplace, and thought that bringing the
semantics of git-style version control to databases would enable that
use case. With that goal in mind, we built Dolt’s interface as a git
clone, where every command for git had a corresponding one in dolt
that behaved identically.
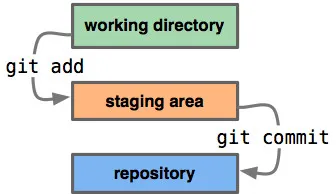
% git clone myOrg/myRepo % dolt clone myOrg/myDb
% git checkout -b feature-branch % dolt checkout -b feature-branch
% git add file % dolt add table
% git commit -m "message" % dolt commit -m "message"Inevitably, this abstraction made its mark on the libraries we built. Dolt was a command line tool, run by a single user in a directory on a file system, and the interfaces reflected this fact. This was still true even after we started adding robust SQL features to the product. At the time, we saw such functionality primarily as a bridge to tooling: connect anything that talks to MySQL to Dolt to get data in or out.
But a funny thing happened on the way to the data marketplace (which we’re still working on): customers showed up and wanted to use Dolt as an application-backing database, to replace their Mongo or MySQL backends. People wanted a SQL database that you could branch and merge natively, instead of building kludgy and slow workarounds on top of databases that couldn’t. And they kept coming. We realized we had accidentally built a SQL database with unique features people wanted.

Today we think of Dolt primarily as a
database,
not a data sharing tool. It’s still the best tool for sharing data on
the internet, but that’s not what our customers are paying us for at
the moment. So while you still can operate Dolt as a command line tool
that behaves exactly like git, that’s not how most of our paying
customers are using it. They’re spinning up a SQL server and
connecting to Dolt like any other SQL database. And instead of
operating Dolt on the command line, they’re using equivalent system
tables
and SQL
functions
from their SQL sessions.
This is great! We love change, and we love having customers pay us to build a cool product. But Dolt’s evolution from single-user command line tool to multi-user database meant that some of the most fundamental abstractions in the code base were no longer good enough. Like a lot of problems in software, it came down to shared state.
The repo_state.json file#
If you dig into a Dolt directory on disk, you’ll find a .dolt
directory that contains the storage for the database and some
metadata.
% find .dolt
.dolt
.dolt/config.json
.dolt/noms
.dolt/noms/1s7h8no1q2msks1k58f86nohvvaun1qn
...
.dolt/noms/vq6p3rvh9a00pme6vrkset62fmbiucfc
.dolt/repo_state.json
.dolt/temptf
.dolt/tmpMost of these are easy to explain. config.json stores
repository-level config settings like user name and email. Everything
in the /noms/ directory are the raw chunk files and indexes used to
store data. But what about the repo_state.json file? What’s in
there? It’s very germane to this story.
% cat .dolt/repo_state.json
{
"head": "refs/heads/master",
"staged": "50edr9oqsnt44cno7b0unbci0q7sp8ni",
"working": "415ukc5r7darj0sdq97k7tdau5gluqj6",
"merge": null,
"remotes": {},
"branches": {}
}Those values for staged and working should look familiar: they’re
hashes. In fact, they’re pointers to the root data structure that
represents a snapshot of the entire database. working is basically
analogous to the file system in a git repository: it contains the
snapshot of the database that you haven’t yet staged or
committed. Every INSERT, UPDATE, DELETE, or other modifying
statement will cause that value to change. There’s also some other
info in there, like the current merge state.
But wait! How are you supposed to support a multi-user database environment if this fundamental session state is stored in a single file for the entire database? How are multiple concurrent writers going to update this thing safely? How are you supposed to achieve the dream of supporting multiple writers on each of N branches concurrently?
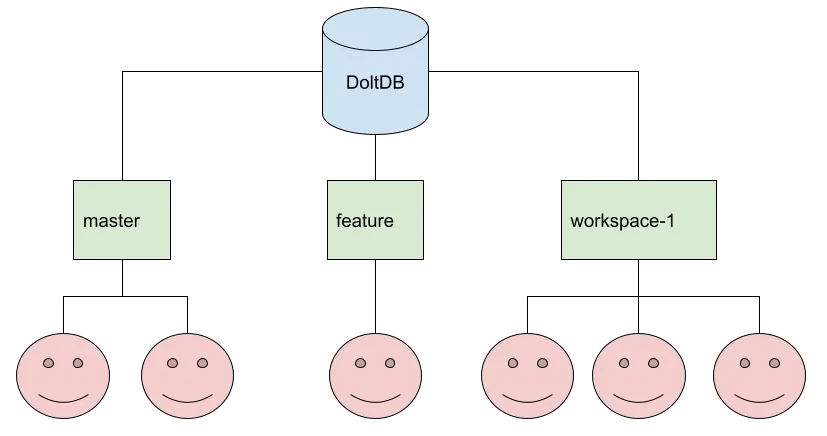
You aren’t, and that’s the problem.
It gets worse#
We realized the original state management wasn’t going to cut it when
we started working on making Dolt support normal SQL transactions. We
really needed to manage shared edit state in the database itself, not
externally in a random text file. When we launched the alpha for
transaction
support a
few months ago, it included some minimal functionality to achieve
this. In addition to updating the repo_state.json file, a successful
commit for the alpha release would write to a new part of the dataset
directly. We can explore what it writes by using a command line tool
that I wrote called
splunk. I
wrote it in perl because I unironically love perl and will fight
anyone who disagrees with me.
% splunk
Welcome to the splunk shell for exploring dolt repository storage.
map { // 5 items
1) "refs/heads/feature-branch": #1t9o2d1pd941010n04pprodue5di0oio,
2) "refs/heads/master": #ma5h94tml8d5plugfqbcefrt5sbd00i2,
3) "refs/internal/create": #1t9o2d1pd941010n04pprodue5di0oio,
4) "workingSets/heads/feature-branch": #56i59u8mdib4ccrmpvijcjlpugb5330u,
5) "workingSets/heads/master": #s9o4hi8l739kktj14kdk0bnv6skj9g2i,
}
Currently examining root.
Use numeric labels to navigate the tree
.. to back up a level, / to return to root.
Type quit or exit to exit.Here you can see there are two heads (branches) in the database,
master and feature-branch. For each one, there’s a corresponding
workingSet entity. If we look inside there, we find:
> 5
struct WorkingSet {
meta: struct WorkingSetMeta {
description: "updated from dolt environment",
email: "zach@dolthub.com",
name: "Zach Musgrave",
timestamp: 1627434106,
version: "1.0",
},
1) stagedRootRef: #hoso6cvo0pvdv5c0h6acvbm87ttisnrt,
2) workingRootRef: #hoso6cvo0pvdv5c0h6acvbm87ttisnrt,
}So essentially, the same information as the repo_state.json
file. For the alpha release of transactions, this state information
was split into two pieces: in the database proper for the SQL context,
and in the repo_state.json file for the command line context. To
take transactions out of alpha and into a full release, I needed to
fix this schizophrenic situation and make a single source of truth for
client state, so that running dolt sql -q on the command line would
always give the same results as running the same query in a SQL
context on the same HEAD.
Should be easy, right? Just change the interface that writes to that file and make it write to the new place instead.

Remember, Dolt evolved from a command line tool that assumed a single
user. And for convenience’s sake, the repo_state.json file was read
and written very liberally. It was very common to find the following
pattern, spread out across different methods:
func someCommand() {
step1() // writes to repo_state.json
business_logic() // reads from repo_state.json
step2() // reads from and writes to repo_state.json
}
Effectively, the repo_state.json file was functioning as a slow and
buggy global variable store, making it incredibly difficult to reason
about cause and effect in the various command implementations. Worse,
it was splitting what should be an atomic unit of work up into
multiple writes, so that if you hit a weird edge case that managed to
crash the program in the wrong place it was possible your database
state would be corrupted.
The long, dark re-write of the soul#
The solution to this problem was to slowly untangle the global state management, transforming methods that read and write global state into purely functional methods that accept a state and return a new one.
For example, consider the action of dolt add, which takes one or
more tables and adds them to the staging area to prepare for
committing. This functionality is used not only in the implementation
of dolt add itself, but also in its SQL equivalent, SELECT DOLT_ADD(). In the latter case, it’s absolutely vital that the all
changes remain in memory until the transaction is committed.
Here’s what a method involved in dolt add looked like in the world
of global state management:
func StageAllTables(tableNames []string, rsr RepoStateReader, rsr RepoStateWriter) error {
root := rsr.WorkingRoot()
moveTablesBetweenRoots(root, rsr.StagedRoot(), tableNames)
rsr.UpdateStagedRoot(root)
}The transformation I needed to make was to turn this function into its strictly functional equivalent, something like this:
func StageAllTables(tableNames []string, roots Roots) (Roots, error) {
roots = moveTablesBetweenRoots(roots.Working, roots.Staged, tableNames)
return roots, nil
}The thing is, this isn’t really hard, once you understand the general concept. But it’s everywhere. It was present in hundreds of different files and undergirded every aspect of the product. In each and every place there were tests to break and then fix, bugs to hammer out, related refactorings that became necessary.
I started the process in early June, toiled away diligently at my desk every day like an obedient little scrivener, and suddenly it was coming up on Independence Day it was still going. I was starting to get really uncomfortable with how long my branch had been divorced from master. Andy and other teammates kept needing isolated pieces of the rewrite that just wasn’t ready to check in yet, so were cherry picking bits of it onto their own feature branches to unblock themselves. And the PR was getting really, unreasonably massive. Just take a look for yourself:

If a junior engineer brought me a PR this big, I would slap it out of his hands and tell him to start over. No human could possibly be expected to even casually review this much code and understand it in one sitting. And yet I couldn’t do anything else: the changes I was making were so fundamental that everything would break, then I would fix it all, then everything would work. There were no halfway measures, no clean break points at which I could split it up and check in bits at a time.

This isn’t true, of course. There’s always a way to break a change up into smaller chunks, to make changes incrementally rather than in one giant blast. But as anyone who has attempted this knows, it’s often much, much harder to go incrementally. In my case, I didn’t see an incremental path emerge until I had put in several weeks of refactoring, work that I would have to discard and start over from scratch just to be a better teammate. Sunk cost is a hell of a motivator, even when you know it’s a fallacy.
And I was making progress. I finally finished the main body of code changes and got to work finding all the bugs I had introduced in making them. Luckily for me, Dolt has great integration tests, otherwise I would never have dared attempt a change this large in the first place. When I first started fixing them, about 100 were broken. By the weekend, I had gotten that number down to 70.
The final straw was when Tim DMed me to call me Herbie from The Goal, the weakest hiker who slows down the entire team.
He didn’t need to tell me. I already knew everybody was getting held up by my marathon rewrite. It had to end.
I’d already shipped my wife and kids off to the grandparents for summer vacation, and with covid restrictions in effect I didn’t have much better to do for the long weekend anyway. So I decided to buckle down and put myself out of my misery instead. The effort paid off with what I’d labored for 140 commits spread out over a month to see: a clean test run.
Nothing left to do but bask in the glory of my accomplishment. At DoltHub, we work hard, and then we play hard. I’m not too proud to admit I didn’t bring my A game to work the next week. I had it coming.

Conclusion#
Writing a new kind of database from the ground up isn’t easy. You take a lot of wrong turns. This definitely isn’t going to be the last time we rewrite large parts of it to satisfy some new requirement or business direction. In fact, we already have our eye on the storage layer for performance reasons. After that will probably be the query execution engine. And after that, who knows?
Like I said: great art is never finished.
Like the article? Interested in Dolt? Come join us on Discord to say hi and let us know what you think!