
While cleaning our hospital price database, I learned that GPT-4’s function calling could quickly crack one of our hardest nuts.
The context#
Since 2021, hospitals have been required to publish tables of:
- billing codes, representing a service
- rates for those services
- who pays those rates, like the insurance company or plan
Since the law allows hospitals to choose the schema they publish in, the way the data is organized is usually pretty unpredictable. Nevertheless, parsing out the billing codes and rates (which we do by hand) is something we can do as long as the strings aren’t too mangled.
Where things get hairy is in that third bullet point: the insurance company or plan. Let’s say you want to use the hospital price database to find out if some plans pay way more (or less) than average. To compare apples to apples, at the very least you want to be able to group plans into “commercial”, “Medicare Part C” (known by its marketing name as “Medicare Advantage”), etc., since they have different paying arrangements. You won’t learn anything by finding out that a Medicare Advantage plan pays less than a commercial plan, since this is pretty much always true.
In a just world, every plan would get a universal ID, and then you could look up that plan’s details in another table. But here’s the reality: hospitals publish mangled strings like
“i10112232_Health_Alliance_America_HMO_and_PPO [2201]”
and
“HAA”
to mean the same thing. Strings like this make it hard to figure out the properties of each plan. You can go crazy searching the internet and writing the regex rules to classify them. For example, it’s easy enough to see “UHC_Medicare_Advantage” is a Medicare Advantage plan rates, but what about “Devoted Health”? (The answer: also yes.)
We have 7,000 unique strings in our database and the number is only getting bigger as we add more hospitals. We could hire a team to help us classify them, but even better would be if we could have an expert eyeball each plan (“Oh, Devoted Health? That’s a Medicare Advantage plan”) to cut down on the searching. But there aren’t many experts like that out there.
Then I wondered: could GPT-4 be that expert?
GPT-4#
I remembered: OpenAI recently released function calling. Function calling means “translate some input into parameters you need to call a function — and then decide which function to call.” So you can take some string and translate it into function parameters a, b, c:
( some string ) --> {a, b, c}You can see this as labeling, or classification.
This makes it tempting to ask whether I could abuse function calling to get a label, as in:
( HEALTH_CHOICE_1112_HMO ) --> {is_medicare_part_c: True}I defined a non-existent function get_payer_details with and then instructed GPT-4 in the following way:
def parameters(state):
"""Function parameters used for GPT-4 function call
'state' is the two letter state code, e.g. 'AL' (for Alabama)"""
return {
'type': 'object',
'properties': {
'health_plan_name': {
'type': 'string',
'description': f"""
The name that refers to a package of health insurance benefits.
Format: health insurance company name, followed by plan name, followed by network type (HMO, PPO, etc.)
You may infer the plan name from the fact that the payer and plan are located in {state}"""
},
'payer_name': {
'type': 'string',
'description': f"""
If applicable, the health insurance company offering the health plan.
The payer (or payor) is the entity that pays for the healthcare services.
We know that this insurance company operates in the state of {state}."""
},
'parent_company': {
'type': 'string',
'description': "If applicable, the parent_company of payer_name inferred from the provided string and state information"
},
'is_medicare_part_c': {
'description': """
indicates whether the payer/plan is either
a) a Medicare Advantage plan,
b) a Managed Medicare plan or, equivalently
c) operates under Medicare Part C""",
'type': 'boolean',
},
'is_managed_medicaid': {
'description': "True if the payer/plan is a Managed Medicaid payer/plan",
'type': 'boolean',
},
'is_marketplace_plan': {
'description': "True if the payer/plan is on a state healthcare exchange marketplace",
'type': 'boolean',
},
'is_febp': {
'description': "True if the payer/plan is a Federal Employee Benefits Program/Plan",
'type': 'boolean',
},
},
'required': ['health_plan_name', 'payer_name', 'parent_company', 'is_medicare_part_c'],
}
def functions(state):
return [{'name': 'payer_details', 'description': "Look up details given the health plan name, payer name, and parent company", 'parameters': parameters(state)}]Then I gave GPT-4 a mini “constitution” of the things that it “will” do, priming it to format the strings in a consistent and recognizable way.
def label_payer_strings(payer_name, plan_name, state):
payer_name = clean_payer_name(payer_name)
prompt = f"""
I will use what I know about health insurance plans.
I know that the string may contain either
a) a payer
b) a payer and a health plan
c) the name of a business operating in {state}
d) a benefits plan
e) or a state correctional institution operating in {state}.
If a string contains an acronym for a known health insurance company operating in {state}, I'll expand it.
I will use casing in my responses consistent with how the payer or health plan is marketed.
I will ignore whether a plan is "out of state", "out of network", "all plans", or "all other plans".
If I am sure of what an acronym or an abbreviation means, I will spell it out.
I will write networks as acronyms, as in: HMO, PPO, POS, HMO|PPO etc.
I will put the network acronyms at the end of the plan_name with pipes between them.
I will identify payers and plans that operate under Medicare Part C.
I will identify payers and plans that are managed medicaid, marketplace plans, or are federal employee benefits programs.
If a string contains unnecessary words or spaces, I'll normalize my responses by removing them.
"""
messages = []
messages.append({'role': 'system', 'content': prompt})
messages.append({'role': 'user', 'content': f"Return details about `{payer_name}`"})
completion = openai.ChatCompletion.create(
model = 'gpt-4-0613',
messages = messages,
functions = functions(state),
function_call = {'name': 'payer_details'},
temperature = 0,)
cost = round(completion['usage']['prompt_tokens']/1000*.03 + completion['usage']['completion_tokens']/1000*.06,3)
print(f'{cost=}')
response = json.loads(completion.choices[0].message.function_call.arguments)
return responseThe results#
Here’s the punchline, presented as a sample (but results are representative of most hospitals.) I looked at the payers from Ascension St. Vincent’s East, and ran them through this small GPT-4 pipeline. Everything you see italicized, i.e. the red/blue column and rightward, is purely machine-generated:
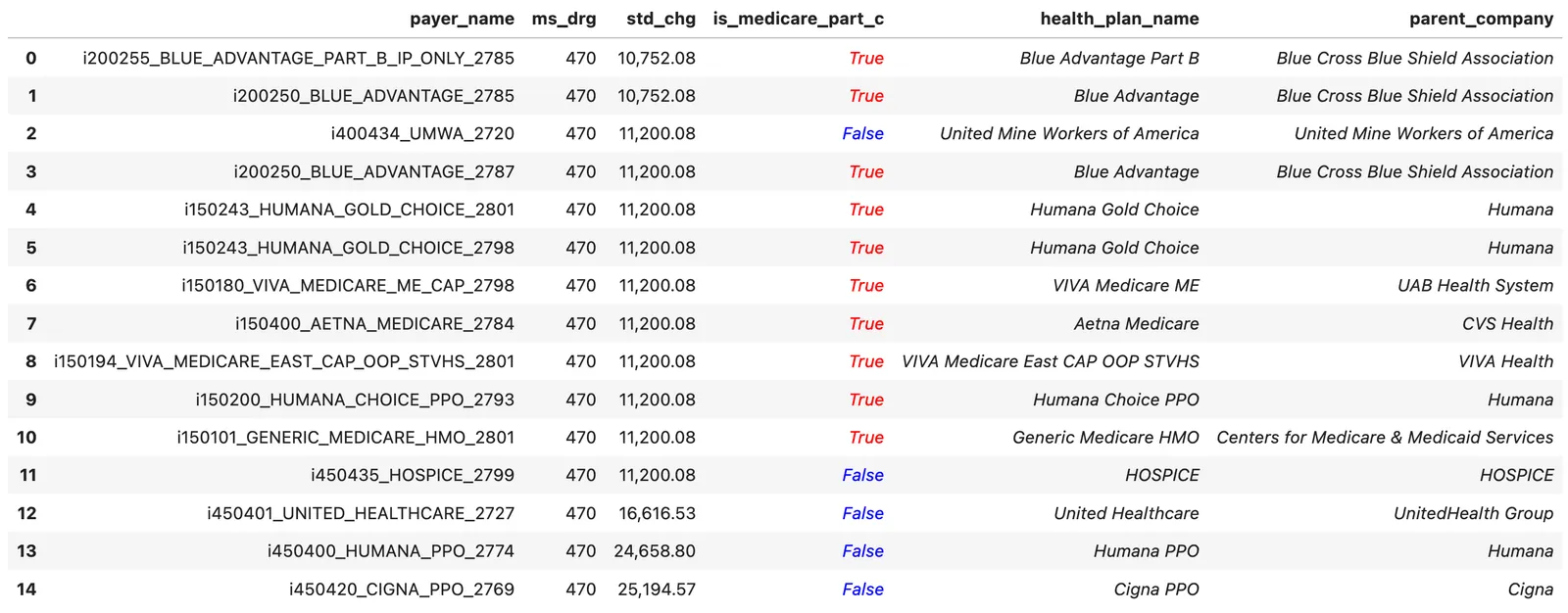
The column is_medicare_part_c tells me if I should expect that payer to reimburse at approximately Medicare rates (you typically only want to compare commercial plans to each other, and not to Medicare Advantage plans.) GPT-4 missed the UMWA reimburses at Medicare rates (of course, how could it, or anyone, have possibly known that), but that’s not a problem — we can correct that label retroactively. When a payer often, say 75%+ of the time, pays the same rates as other Medicare Part C plans, we can safely label it as Medicare Part C.
With no manual labeling, and a little finessing of the prompt, this all comes out magically.
Some limitations#
This, of course, is not the most cost-efficient or fastest workflow. But it’s easy to get started, and it’s effective. The main issues I ran into were in the unpredictable results I got out:
- You have to give GPT-4 the right system prompt. If you don’t give it much instruction, it’ll just give you back what you put in, without much normalization. If you tell it to normalize too much, it’ll start making things up. With this approach, you can tune the prompt to give you the right results most of the time.
- The initial system prompt seems to drive the biggest change in behavior. Describing the function parameters better did not result in better output.
- Changing the system prompt has unpredictable effects on the output. Sometimes, reordering the instructions will make the output better or worse. Clarity in wording seems key.
I’ll definitely be exploring this more.
As a non-expert in ML, I wondered: how would other people have done this? Is there an even easier, better, faster way? Plus, I’d love to see data labeling be officially supported by an API call.
About our work#
DoltHub is a database company, not a healthcare company, and we were only able to build this open-source database on the back of Dolt: a version-controlled, branchable, cloneable database. Dolt does not sell or license the hospital data. It is available for free, under Creative Commons.
Our work on hospital price transparency has made us part of the ongoing conversation about transparency in healthcare. If you have ideas on how to make healthcare better, vis-a-vis the lens of hospital price transparency, let me know, I’d love to hear from you. Email me at alec@dolthub.com, or join our active Discord.