
Intro#
Testing a database management system is a challenging endeavor for many reasons. DBMSs are large, complex applications with a lot of focus on code optimization and performance. SQL syntax is sprawling, with lots of dark corners, no lack of customization between different vendors, and a huge amount of surface area, especially when you consider how SQL features can be used together in various combinations. On top of those technical challenges, there is an extremely high bar for data correctness. Customers put a LOT of trust in their database and fill it with data that often cannot be replaced. Maintaining this level of trust requires a high bar for testing and continually evolving and improving testing strategies.
We spend a lot of time writing new tests, designing new layers of testing, and thinking about how to efficiently and effectively test Dolt DB. In this post, we’re going to be focusing on SQL syntax coverage testing, as opposed to performance testing, load testing, etc. We’re introducing a new tool in our testing toolbox that helps us generate fuzzed SQL statements by crawling a grammar definition – Grammar Crawler. We’ll show how Grammar Crawler helps us fill in gaps in our existing SQL coverage tests, talk about how it works, and how we measure the results.
SQL Sprawl#
Let’s start off explaining the problem we’re trying to solve…

One of the classic challenges in testing database management systems is the sprawl of SQL – SQL has been around for half a century, the ISO SQL specs have gone through many revisions and extensions over the years, and all vendors go “off script” to customize the SQL syntax for their database systems. SQL is an extremely expressive language and there are an infinite number of syntactically valid statements you can build from the SQL grammar. Testing over this surface area is a daunting task! Fortunately, there are some good tools out there already that can help.
We use SQLLogicTest extensively for testing SQL coverage and correctness on Dolt DB. SQLLogicTest was originally built almost 15 years ago to test the SQLite database, but since then, its suite of ~6 million generated SQL queries and its test runner have proven extremely useful for testing many database engines. SQLLogicTest also enables differential testing, which is an excellent fit for testing Dolt DB, since we’re aiming for full MySQL compliance and we can test our implementation against results from the same query executed on MySQL.
However, the SQLLogicTest test suite covers some areas of SQL very well, and other areas not so well. Now that Dolt can execute about 99.75% of the existing test suite correctly, we wanted to better understand what gaps the test suite has and how to fill them. After some analysis of the test suite, we found that there are more than 5 million SELECT statements in the SQLLogicTest test suite and coverage over expressions is also very good. The biggest gap we identified was DDL statements. For example, although there are about 7k create table statements in the test suite, they hardly have any variance, they don’t test many options, and they don’t cover all MySQL data types. Another notable gap in DDL statement coverage is that there are zero `ALTER’ statements in the test suite.
Mind the (SQL Coverage) Gap#

We wanted to extend the test suite to fill in those gaps, starting with DDL statements, but writing thousands of test statements by hand just wasn’t going to work, so we started thinking about how to generate more statements. When we found an official MySQL ANTLR grammar maintained by Oracle, as part of the MySQL Workbench repo, we knew a complete grammar covering the SQL syntax we were targeting would be a useful tool to help us fill in those gaps in our test coverage.
We started playing around with ideas to generate statements from the grammar and Grammar Crawler was born. Just like how a web crawler picks a web page to start from, finds all the links in that page, and queues those up to process, Grammar Crawler works in a similar way. You give it a starting point in an ANTLR grammar and Grammar Crawler finds all the possible paths through the grammar starting from that point. However, there are some significant differences between how a web crawler works and how Grammar Crawler works. For example, unlike a web crawler, Grammar Crawler cares about the path through each rule in a grammar. It’s not enough to simply visit every rule – Grammar Crawler has to traverse each distinct path through the grammar’s rules to find all the possible statements that could be generated.
Release the Crawler! 🕷#
Enough talk already! Let’s jump into a concrete example to see Grammar Crawler in action…
The CreateTableStatementsGenerator in the Grammar Crawler repo on GitHub is what we use to generate create table statements for testing. At the start of this file’s main method, we load the MySQL Grammar and transform it into a different representation that’s easier for Grammar Crawler to work with, then we configure the crawl strategy, statement writers, and statement limit on the crawler instance.
Map<String, Rules.Rule> ruleMap = MySQLGrammarUtils.loadMySQLGrammarRules();
Crawler crawler = new Crawler(ruleMap);
crawler.setStatementLimit(1_000_000);
crawler.setCrawlStrategy(new CrawlStrategies.CoverageAwareCrawl(crawler));
crawler.setStatementPrefix("CREATE ");
crawler.setStatementWriters(
new StdOutStatementWriter(),
new SQLLogicProtoStatementWriter("sqllogic-test-create-table.proto"));After constructing the crawler instance, we configure which rules to skip in the grammar. Most of these rules are skipped because we know we don’t support those features yet and generating semantically valid statements requires enhancements to the reification logic that turns a statement template into a ready-to-execute statement. Here’s an example of a rule we skipped because it’s not part of the core functionality we’re prioritizing:
// COLUMN_FORMAT is a feature of MySQL NDB Cluster that allows you to specify a data storage format
// for individual columns. MySQL silently ignores COLUMN_FORMAT for all other engine types.
crawler.addRulesToSkip("columnFormat");Although Grammar Crawler will only generate syntactically valid statements, that doesn’t mean those statements are semantically valid statements. We want to filter out any statements that aren’t semantically valid, so we configure a StatementValidator that will test our statement against a local MySQL server if one is running. Any statements that don’t pass validation won’t be handed to the configured StatementWriters and will instead be sent to a separate invalid-statements.txt file.
MySQLStatementValidator mySQLStatementValidator = MySQLStatementValidator.NewMySQLStatementValidatorForSQLLogicTest();
if (mySQLStatementValidator.canConnect()) {
crawler.setStatementValidators(mySQLStatementValidator);
crawler.setInvalidStatementWriter(new StatementWriters.FileStatementWriter("invalid-statements.txt"));
}Last, but not least, after the crawler is fully configured and ready to crawl, we call the startCrawl method to kick off the crawl; when it completes, we call printCoverageStats() to display some simple stats about the coverage over the grammar, which we’ll explain more in the next section.
crawler.startCrawl(ruleMap.get("createTable"));
crawler.printCoverageStats();When you run this generator, you’ll see output on stdout from the StdOutStatementWriter like below, as well as file named sqllogic-test-create-table.proto on your local disk that was generated by the SQLLogicTestProtoStatementWriter we configured earlier.
CREATE TABLE `t1710a` (`c1` MULTIPOLYGON COMMENT 'text155459', `c2` MULTIPOLYGON COMMENT 'text155461');
CREATE TABLE `t1710b` (`c1` MULTIPOLYGON COMMENT 'text155575', `c2` MULTIPOLYGON COMMENT 'text155577') KEY_BLOCK_SIZE 4.2 KEY_BLOCK_SIZE 4.2;
CREATE TABLE `t1710c` (`c1` MULTIPOLYGON COMMENT 'text155595', `c2` MULTIPOLYGON COMMENT 'text155597') KEY_BLOCK_SIZE 4.2 KEY_BLOCK_SIZE 4;
...
CREATE TABLE `t4c4b3e` (c1 TIMESTAMP (12) UNIQUE, c2 CHAR VARYING (4) KEY) PASSWORD 'text7968898' ENGINE 'text7968899';
CREATE TABLE `t4c4b3f` (c1 TIMESTAMP (11) UNIQUE, c2 CHAR VARYING (4) KEY) PASSWORD 'text7968900' ENGINE `c3`;
CREATE TABLE `t4c4b40` (c1 TIMESTAMP (14) UNIQUE, c2 CHAR VARYING (4) KEY) PASSWORD 'text7968901' ENGINE c3;
Total Statements: 1,000,000
Literal Element Coverage:
- Total: 123
- Used: 112
- Unused: 11
- Coverage: 91.06%The summary stats show that we generated a million statements (the limit we configured earlier) and those statements covered 91% of the literal tokens reachable from our starting point in the grammar (taking into account any pruned rules).
From here, we take the file generated by the SQLLogicTestProtoStatementWriter that we configured, and add those tests to the suite in our forked SQLLogicTest repository so they can run as part of our automated SQL Correctness reports. The diagram below shows a high-level view of how data flows through the system.
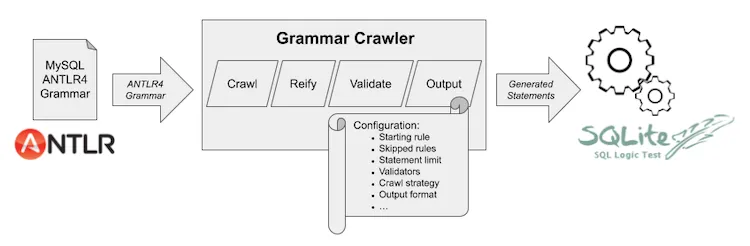
Measuring Grammar Coverage#
It’s great that we’re now able to spit out millions of SQL statements generated from a defined grammar, but how do we know if those statements are the right statements? We needed a way to measure how well we’re solving the problem we set out to solve. We want a set of statements that cover our grammar well, not just a bunch of statements that cover one small corner of the grammar.
For a first pass, we chose to measure usage of the literal tokens in the grammar. This gives us a simple way to measure our coverage over the grammar by measuring how many of the reachable literal tokens were used in the generated statements. It also enables a CoverageAwareCrawlStrategy to make better decisions to try and optimize coverage by always crawling paths when they contain literal tokens that haven’t been used in generated statements yet. Even with this simple approach, there are some tricky edge cases. For example, to calculate the reachable literal tokens in the grammar, we have to be aware of what rules the crawler will skip and not include any transitive literal tokens from those rules. This was fairly obvious, but it also means that if a literal token is a sibling of a skipped element, or a sibling of another rule that requires a skipped element, then those literal tokens are not actually reachable either and should not be included in the set of reachable literal tokens.
Show me the Results!#
We’ve just added the first batch of generated statements from Grammar Crawler to our SQLLogicTest fork to run as part of our SQL Correctness testing. This adds 4,575 create table statements to our existing suite of test statements in SQLLogicTest. 1,901 (42%) of those statements don’t execute correctly on Dolt (yet!), and the other 2,674 statements already work correctly.
These tests give us a wider variety of create table statements in our test suite, they cover all MySQL data types, and they also cover additional create table options such as UNIQUE constraints and PRIMARY KEY that weren’t being exercised before. We’re happy that the majority of generated statements already execute correctly and also that there are still a good chunk of failing statements that will help us improve our compliance with MySQL. Let’s take a look at a couple of these new, generated statements that execute successfully on MySQL, but fail on Dolt:
CREATE TABLE `t21006` (`c1` NCHAR VARYING (15) COMMENT 'text1098849', c2 NCHAR VARYING (42) KEY);
CREATE TABLE `t1710a` (`c1` MULTIPOLYGON COMMENT 'text155459', `c2` MULTIPOLYGON COMMENT 'text155461');
CREATE TABLE `t19992` (`c1` GEOMETRY NULL, `c2` GEOMETRY COMMENT 'text289357') AVG_ROW_LENGTH 4 STATS_SAMPLE_PAGES = 0x5;The first statement fails because Dolt doesn’t currently support the VARYING keyword when defining char fields. The second statement fails because Dolt doesn’t support the MULTIPOLYGON geospatial datatype. The last statement fails because Dolt doesn’t support hex-encoded numbers for table options.
There’s still more room for improvement in the statements Grammar Crawler generates in order to further exercise the MySQL grammar and we hope to continue improving the generation logic over time. Even in this initial version, though, we’re identifying gaps in our SQL coverage and improving our SQL Correctness test suite.
Wrap Up#
Thoroughly testing a database management system is a challenging job, but one of the most important things we do in order to keep our customers’ trust. We’ll always be evolving and improving our testing strategies and Grammar Crawler is another tool in our testing toolbox that helps us amplify our effort by easily generating millions of valid SQL statements to run against Dolt DB.
There’s a lot more we can do with Grammar Crawler. The CREATE TABLE generator still prunes out several grammar rules that produce more complex statements; we’d like to remove these restrictions and cover those grammar rules, too. As we move on to additional statement types, like ALTER TABLE, improving the reifier becomes increasingly important. This is the step where a template statement has its placeholder values (e.g. table name, column name, data type) filled in with real values. Today, this logic is rather naive, but supporting additional statement types will require more intelligent value substitution. We also want to improve grammar coverage measurements to provide better accuracy into how thoroughly we’re covering a grammar.
Check out Grammar Crawler on GitHub and let us know if it could be useful for any of the projects you’re working on. If you’re into graph traversals, it’s a really fun piece of code to play with. If you’re interested in discussing techniques and strategies for testing database management systems, drop on by our Discord and say hello! We’d love to hear from you!