
If you haven’t heard by now, Dolt is a version-controlled database. It’s the only SQL database you can diff, branch, and merge. Dolt was engineered from the ground-up to support efficient versioning, which is made possible by its novel indexing data structure: Prolly Trees. Prolly Trees combine properties of B-Trees and Merkle DAGs to create an efficient disk-optimized index that supports fast comparison of index revisions. The result is a next-generation database with greater capabilities that legacy RDBMS. Dolt’s diff algorithm is the foundation of its version control features. Today we’re going to compare Dolt’s diff with another popular open source database: Sqlite
Sqlite Diff#
Sqlite is a lightweight embedded database that persists data in a single, self-contained file. Its simplicity disguises what is a truly full-featured, performant database. Because of its portable file format, it’s common for there to be multiple copies of a Sqlite database and for the copies to drift over time as disparate users edit them. To support this use-case, Sqldiff allows users to compare two related Sqlite database files. Its product page gives us a primer on how it works:
The sqldiff.exe utility works by finding rows in the source and destination that are logical “pairs”. The default behavior is to treat two rows as pairs if they are in tables with the same name and they have the same rowid, or in the case of a WITHOUT ROWID table if they have the same PRIMARY KEY. Any differences in the content of paired rows are output as UPDATEs. Rows in the source database that could not be paired are output as DELETEs. Rows in the destination database that could not be paired are output as INSERTs.
For Sqlite, the diff operation is effectively a full-table join for each pair of tables that match between the two database files. Sqlite uses B-tree indexes which are quite efficient at performing these scans, but asymptotically the operation is still quite expensive.
Dolt Diff#
Like Sqlite, Dolt includes a utility for diffing its indexes, which are also B-tree-like. However, Prolly Trees are unique for their content-addressable structure. Each subtree within a Prolly Tree index is assigned a hash id that is computed based on its contents. Additionally, indexes are carefully maintained such that the tree structure is a deterministic function of its contents. Prolly Trees are “path-independent”, meaning that, unlike classic B-trees, insertion order does not affect the layout of the tree. The end result is that comparing common subtrees is O(1) if the subtrees are equal, regardless of the size of the subtree. When diffing two indexes, we only need to traverse portions of the tree that have changed.
Head-to-Head Performance#
Enough with the theory, let’s see what this means in practice. First we’ll create a
simple schema with a single PRIMARY KEY index:
CREATE TABLE difftbl (
pk int primary key,
c0 int,
c1 int,
c2 int,
);Next we’ll populate the table with ascending integer data for various table sizes. The smallest table contains 25,000 rows and the largest contains 1 million rows. Lastly, we’ll create a diff by deleting a single row from the table. For Sqlite this means making a copy of the database and editing the table. In Dolt, we can use the Git-style versioning model to make a commit before and after the change. Now let’s look at the results:
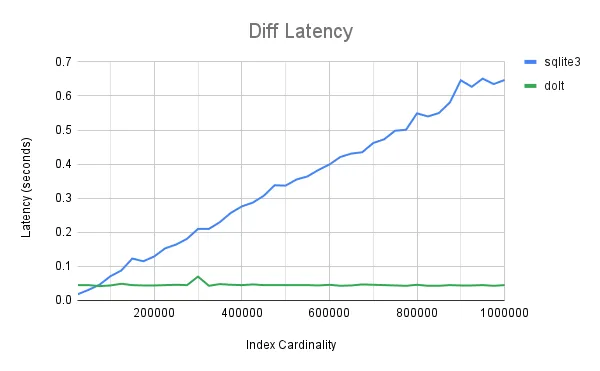
Prolly-Tree indexes allow it to compute diffs in effectively constant time! In Dolt, the cost of computing a diff scales with size of the diff, rather than the size of the index. Sqlite on the other hand must scan all of both indexes. This is reflected in the data as a linear cost scaling.
At the far left of the chart, you can see that Sqlite outperforms Dolt for small table sizes. The benchmarking code used to generate this data used Dolt’s CLI interface for the sake of a fair comparison with Sqldiff’s CLI utility. Generally speaking, Dolt is less optimized for the CLI use case as it performs a lot of bootstrapping work during process startup. In contrast, Dolt performs much better in sql-server mode where it can amortize this work and take advantage of in-memory caching.
To see how Dolt performs in this context, let’s perform another benchmark where we diff the largest table (1 million
rows) via the sql-server. We’ll use golang’s micro-benchmarking tools to perform this query many times and average the
results. As a point of comparison we’ll also include a SELECT query that does a lookup on a single row. You can find
the code for the second benchmark
here
goos: darwin
goarch: amd64
pkg: github.com/dolthub/dolt/go/performance/serverbench
cpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz
BenchmarkServerDiff
BenchmarkServerDiff/point_diff
BenchmarkServerDiff/point_diff-12 1717 698645 ns/op
BenchmarkServerDiff/point_lookup
BenchmarkServerDiff/point_lookup-12 2486 477256 ns/op
PASSFrom the sql-server, Dolt can answer diff queries in under a millisecond! And in fact diffing single edits only takes 50% longer than doing point lookups.
Conclusion#
We’re building Dolt to be a next-generation database, and we believe database version-control is the future. Dolt enables users to store unlimited revisions of their data and efficiently compare them. Dolt’s diff algorithm is at the heart of this technology and powers features that simply don’t exist anywhere else. If you’d like to learn more about Dolt or want to explore how it works for your use case, come join us on our Discord!