Is DoltLab right for you?

Chances are you've heard us say that Dolt is "Git for data". For those who don't know, Dolt is a versioned SQL database with Git-style cloning, branching, merging, and diffing. Since Dolt's inception in 2018, we've pushed this analogy even further. In 2019, we launched DoltHub, the "GitHub for data".
DoltHub provides a GitHub-like web UI for data collaboration with a pull-request, diff based workflow. DoltHub also allows users to edit databases directly and run arbitrary SQL against their databases without having to connect to a running server.
In January of 2022, we released DoltLab, the "GitLab for data". DoltLab provides the same the features as DoltHub but unlike DoltHub, DoltLab is available for download so users can self-host and self-manage it.
So how do you know if DoltLab is right for you? Here's a quick breakdown the products we currently offer:
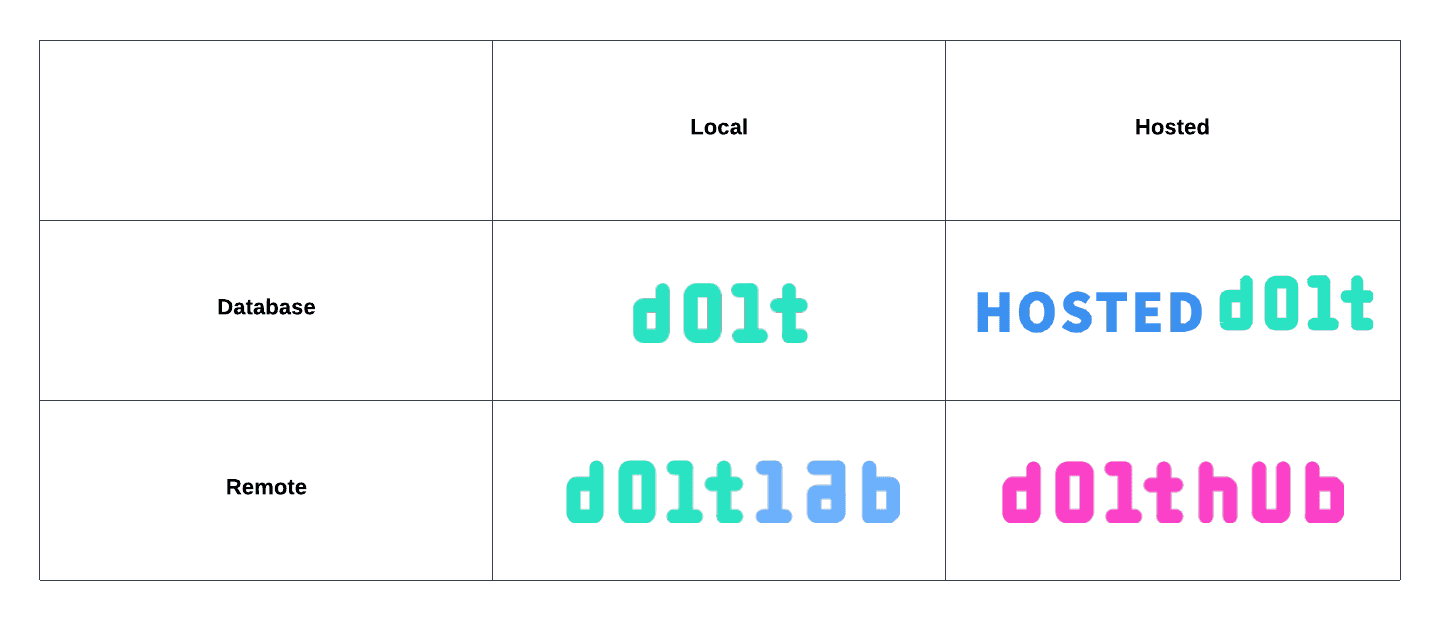
For users looking for a local database, Dolt is the right choice. It can be run easily as a command line utility or can run as a SQL server.
For users who want a fully hosted database solution that we manage and maintain on their behalf, Hosted Dolt is the right choice. This is our newest product offering and makes using Dolt in production easy. To get started, checkout the announcement blog or come chat in our #hosted-dolt Discord server.
DoltHub is the right solution for Dolt users who want a fully managed remote they can to push to. DoltHub not only provides this remote service, but also provides a clean, sophisticated UI that shows off the powerful capabilities that only Dolt databases allow.
One great example of how DoltHub displays the full power of Dolt is through DoltHub's monthly Data Bounties. Data bounties let users compete for their portion of $10,000 each month by contributing data to a database. Each bounty participant submits pull-requests with their proposed changes, gets those changes reviewed by our team. If the user's changes are accepted and their pull-request gets merged, that participant gets paid in proportion to how much they contributed to the final database. Come checkout out our #data-bounties server if this interests you.
DoltLab, on the other hand, is designed for users who want a local remote service they can host and operate themselves, so we think of it as the "Local DoltHub". DoltLab is free to download and use and provides the same amazing features and functionality that DoltHub does, and only requires a single host machine to do so. This machine can be your local desktop, or even a cloud instance.
If you're curious about whether DoltLab might be the right choice for your use case, the rest of this blog will provide some insights into why the types of users we've encountered since launching DoltLab have found it to be a valuable solution to their problems.
So far, DoltLab users have tended to identify with one or both of the following groups:
- They can't, or won't, push data onto the public internet.
- They're part of a small team who wants to version, share, and collaborate on data.
If you can't push data to the public internet, DoltLab is for you!
During the early days of GitHub, users were hesitant to push their source code onto the internet, but that hesitancy is long gone. Now, pushing code to self-hosted or centralized remotes is standard practice in software engineering.
Before launching DoltLab, we would hear this same argument from prospective customers, "I want to use Dolt as my versioned database, but I don't want to push my data to the public internet. Do you have something like DoltHub, that I can host myself?". And our answer since January has been, "Yes, we do! You're looking for DoltLab."
Although source code is widely viewed as "fine" to push to the internet, the idea that data is "fine" too, still has a ways to go. Some organizations restrict the replication and distribution of data to their own premises. This is often for compliance reasons, like GDPR, but might also just be to restrict the distribution of proprietary data.
Some governments enforce data residency laws that limit the replication, distribution, and processing of data outside of particular geographical regions. And, since DoltHub is run in the United States, using it as a distributed data-hub won't work there.
And still, some users and organizations simply don't trust us with their data.
All of these are valid reasons to not want your data on DoltHub. It goes without saying that data is too important and too valuable to not be well safeguarded. But understand, versioning data with Dolt is an additional safeguard, one every organization should adopt.
The great advantage of DoltLab is that it unblocks organizations from getting deeper into their usage and evaluation of Dolt for production. Since each organization can essentially run their own DoltHub (or DoltHubs), they're able to get the best of both worlds—fully versioned safeguarded data that's never pushed to the public internet.
As mentioned above, running DoltLab requires only a single linux host, since DoltLab's data, including data pushed to a DoltLab instance, is stored on that host's local disk. When a user pushes a Dolt database to an instance of DoltLab, that user simply copies and pastes data from their local machine to the machine running DoltLab. Thus, Dolt to DoltLab workflows are totally closed-circuit and fully offline.
If you're in a small team and want to collaborate on data, DoltLab is for you!
Additionally, one insight we've gained over the last few months after launching DoltLab, is that DoltLab is the right scale of sharing and collaboration for small teams. DoltHub, we've discovered, might be far too large.
In the early days of DoltHub, the company, the idea of what DoltHub, the website, should be, was a place for hosting distributed data that supported GitHub-like data distribution and collaboration.
Today, DoltHub does this extremely well on a large scale. However, what we're seeing is that this large scale is unappealing to smaller development and data teams.
When a user pushes a public Dolt database to DoltHub, they're sharing their database with a huge audience, and enabling collaboration to anyone who opens a pull-request. And all databases hosted on DoltHub appear across the site.
The small teams we've interacted with so far though, want all data on DoltHub's UI to be their own. For them, the UI DoltHub provides is more of a data management tool and they aren't really looking to be a part of a larger community. They also might not want to pay for the storage of private data on DoltHub, and prefer to maintain control of their own infrastructure. The cool thing about DoltLab, then, is that these are no longer issues.
DoltLab allows these teams to share and collaborate very easily amongst only themselves without any interference from others. Each team, even within a single organization, can run their own DoltLab instance and restrict access to it, keeping unauthorized users out while at the same time, continuing to easily share data with other teams across the organization.
DoltLab also provides the same great UI as DoltLab, so small teams benefit from DoltLab's ease of use, and will only see data across it that belongs to the team.
Finally, because DoltLab is free, though some features will be paid features in the future, small teams no longer have to pay storage fees, and are only limited by their own infrastructure.
Conclusion
I hope these insights into why certain users have chosen some of our product offerings over others has been helpful. If you've been curious about how you might start to integrate Dolt or any of our products into your workflows or projects, we are happy to help guide you. The best place to reach us is on Discord.
If you know DoltLab is right for you, you can jump right in today. Check out our DoltLab Guide that covers everything you need to know about installing and operating DoltLab, including how to perform some common operational tasks like backing-up data and monitoring service health. You can also checkout our demo DoltLab instance here. Thanks!