
Everyone has that favorite route that they use to drive to work. You’ve driven the route over and over and learn to trust and rely on it over time. You know exactly how long your drive is going to take and when you need to leave the house. So you leave on-time only to find that your car doesn’t start, you run into a random traffic jam or emergency construction. Variability is everywhere and sometimes you just can’t predict it.
In the software engineering world, many systems rely on other third-party systems to operate. They might use an external service to send emails, to store user data, or to query specialized information. The use of third-party systems is ubiquitous. But what happens when the service you rely on is unexpectedly slow? Moreover, what do you do if there is some kind of variability in the third-party service that you can’t directly control?
Here at DoltHub, we recently ran into this problem in the fork creation process. If you’re not familiar, Dolt is a version-controlled open-source database and DoltHub is a place to share Dolt databases on the internet.
Today’s blog post is about how a slow AWS S3 request caused the fork creation process to timeout. Although we didn’t have control over the internals of S3, we still needed to control and mitigate this slow request. Let’s dig into a little about how fork works and how we were able to get fork to work in under 5 minutes for a 1TB database.
Forks copy data#
A fork on DoltHub, creates an independent copy of the source database. Dolt table data is stored in one or more files called table files, so creating a fork needs to create an independent copy of these files. For the databases on DoltHub, these table files are stored in AWS S3. Databases on DoltHub can be large, so we expect creating forks to take time because we have to copy the underlying data. The biggest database currently on DoltHub is the 1TB FBI NIBRS database.
The first time we tried to fork NIBRS, the fork process completed successfully. But on the subsequent attempts, creating the fork timed out consistently. We just got lucky the first time around. It was curious to see that it was possible for the fork process to complete in time, but for most attempts it didn’t complete. But why?
The weakest link#
When we duplicate the table files of a Dolt database, we have to copy each table file in a number of segments. S3 has a maximum copy size of 5GB, so any table files that are larger than 5GB need to be split into multiple smaller segments. In this particular case, the NIBRS database stores all of its data in a single table file. It’s a manual optimization that we made in order to speed up requests against NIBRS. Instead of having to check many files for the location of some data, you only need to check one instead. Since this file is ~1000GB, ~1000 / 5 = ~200 segments are needed to copy it. Each segment is an independent request to S3.
While most requests complete in a reasonable amount of time, some requests might take much longer. The life of one request in S3 can potentially be very different from the next. S3 uses a distributed system architecture under the hood. When we send a request to its public endpoint that request is routed and fulfilled by one of many replicas. These replicas might be in separate physical locations, might be sharing resources among different processes, might be in the middle of some maintenance task, etc. This distributed architecture allows S3 to handle a large number of requests and maintain services during an outage. But it also introduces variability in the time it takes for a request to complete.
When a fork of NIBRS is created, we fan out the 200 segment copy requests in parallel. In order for the copy to complete successfully, we need all of these copy requests to complete. In this case, the request that takes the longest determines the total time of the copy.
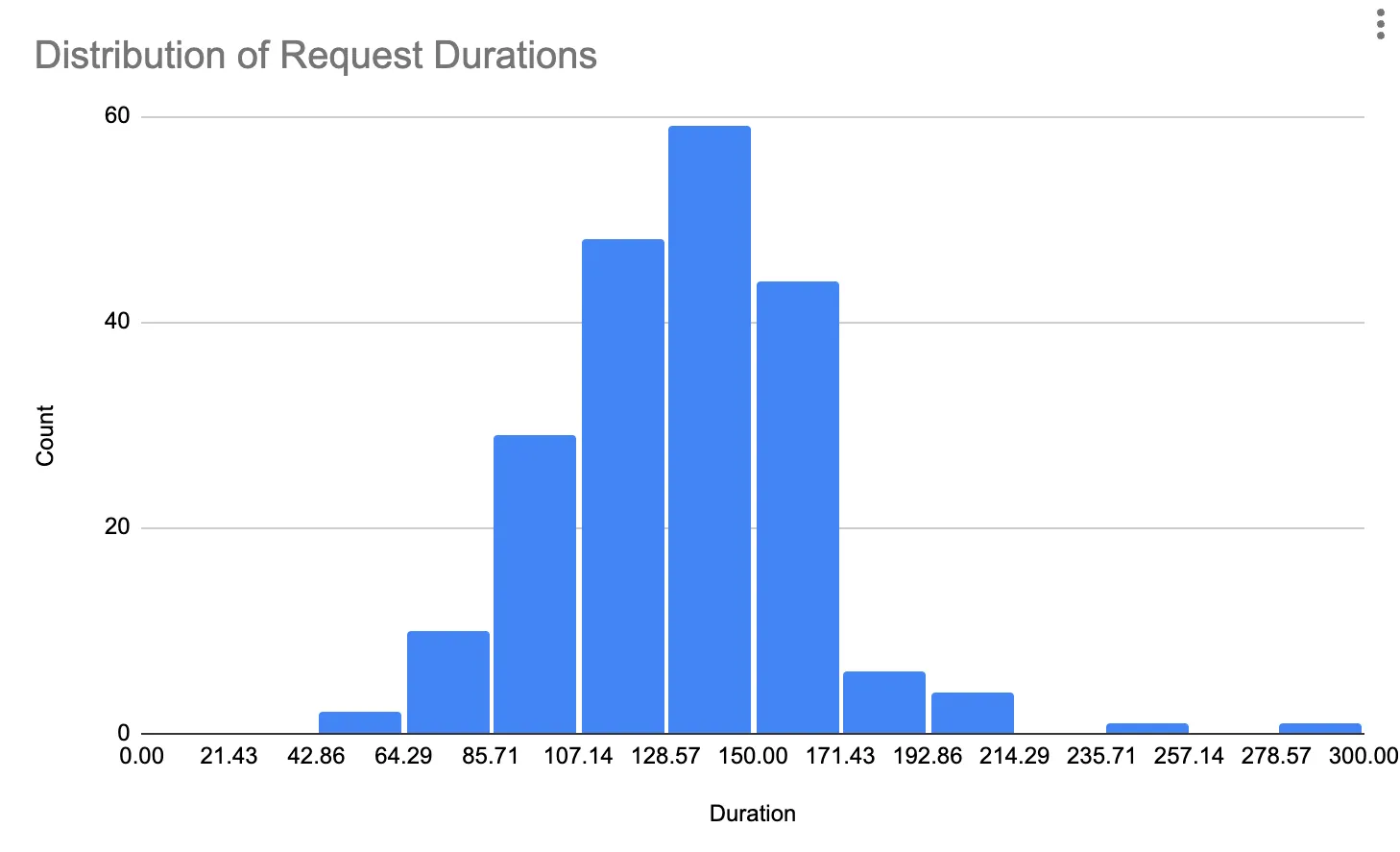
Here’s a histogram of the copy request durations for a fork that failed:
And here’s a Gantt chart of that same data:
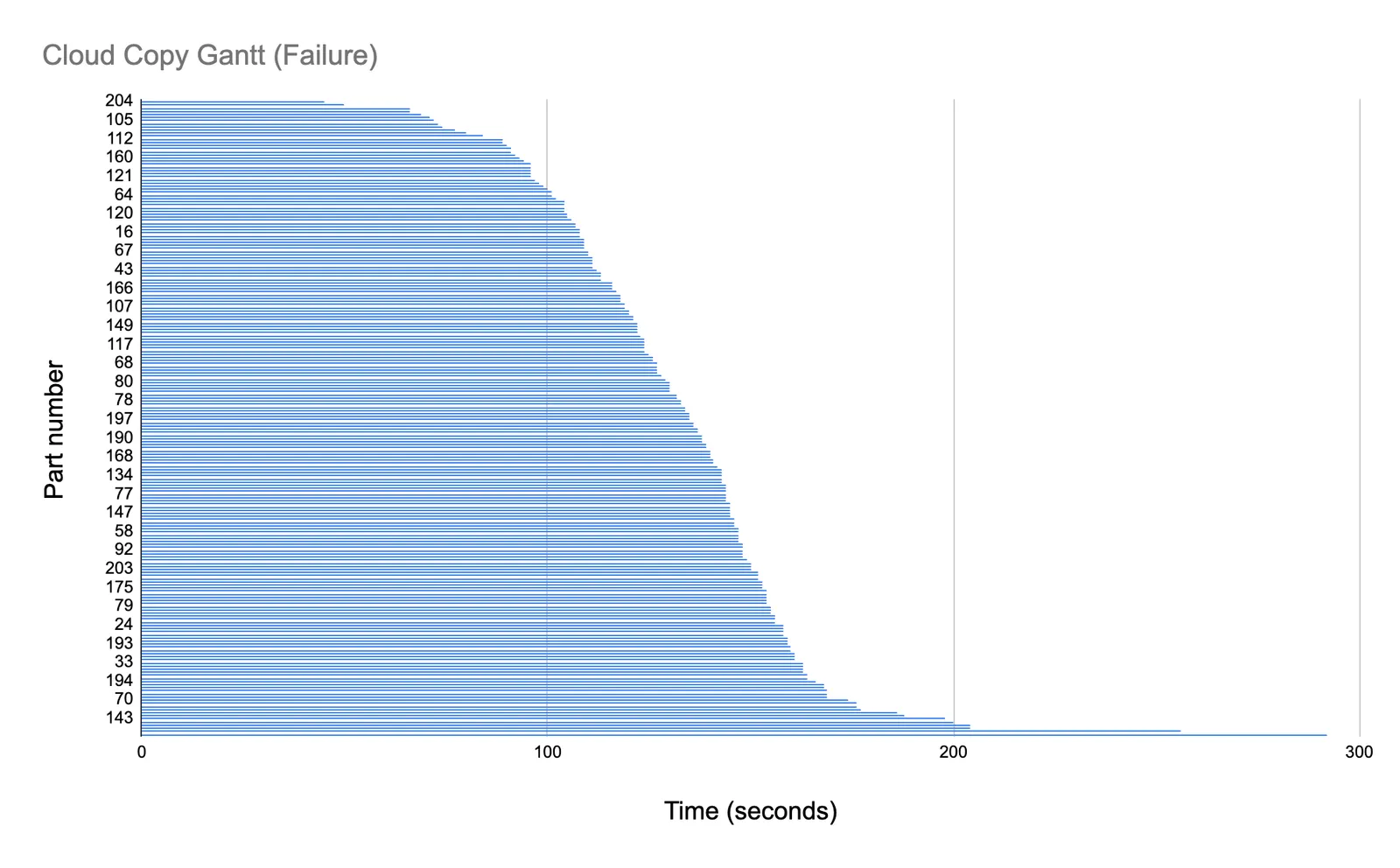
As you can see it’s mostly a normal distribution which is what we should expect to see for requests encompassing similarly sized work. Notice however that we have a request that didn’t complete around the 300 second mark. A single request can time out our entire 1TB fork operation. So how do we prevent this?
The Tail at Scale#
The Tail at Scale is a paper written by Google on this particular problem. It describes the factors that lead to variability in large scale distributed systems like S3, and the difficulties with managing this variability. Large scale systems might measure this variability by monitoring a high percentile of the request durations, like the 99.9th percentile. For example, if the 99.9th percentile is 100ms, that indicates that 99.9% of the request durations are under 100ms. A small number of outliers can greatly affect this number.
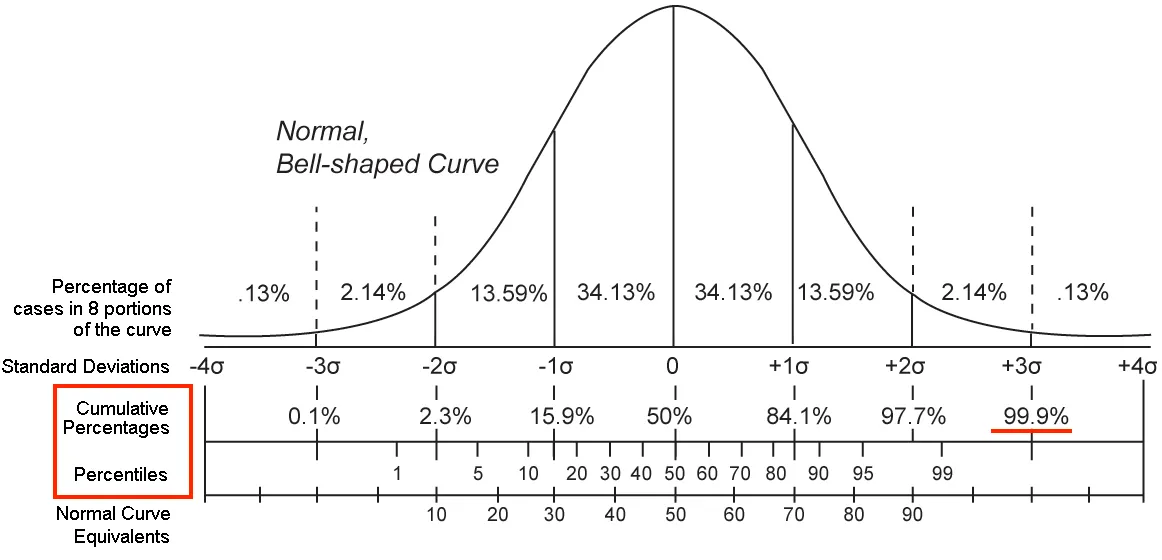
In the paper, Google describes request hedging as a simple solution to this problem. Instead of only issuing one request for each piece of work you need to complete, issue more than one and race the requests. In our fork for NIBRs, we could issue two requests for each segment and cancel the running request if the other completes. The basic idea is that it is less likely for two requests to be slow: if the chance a request is slow is 1%, then the chance that two requests are slow is 1% * 1% = 0.01%. The problem with this naive approach is that we create 2x the number of requests against S3. Instead of managing 200 inflight requests to S3, our service would need to handle 400 inflight requests. This also increases our chances of being rate-limited by S3 when we are processing many forks at the same time.
Instead of hedging all the requests that we issue, we can instead only hedge the requests that haven’t finished after some delay. In an ideal situation, we would be able to continuously monitor the distribution of request durations and dynamically determine a value for this delay. This is tricky to implement in practice, so we simplified and chose a static delay value.
Here is a Gantt chart of our cloud copy durations with request hedging enabled:
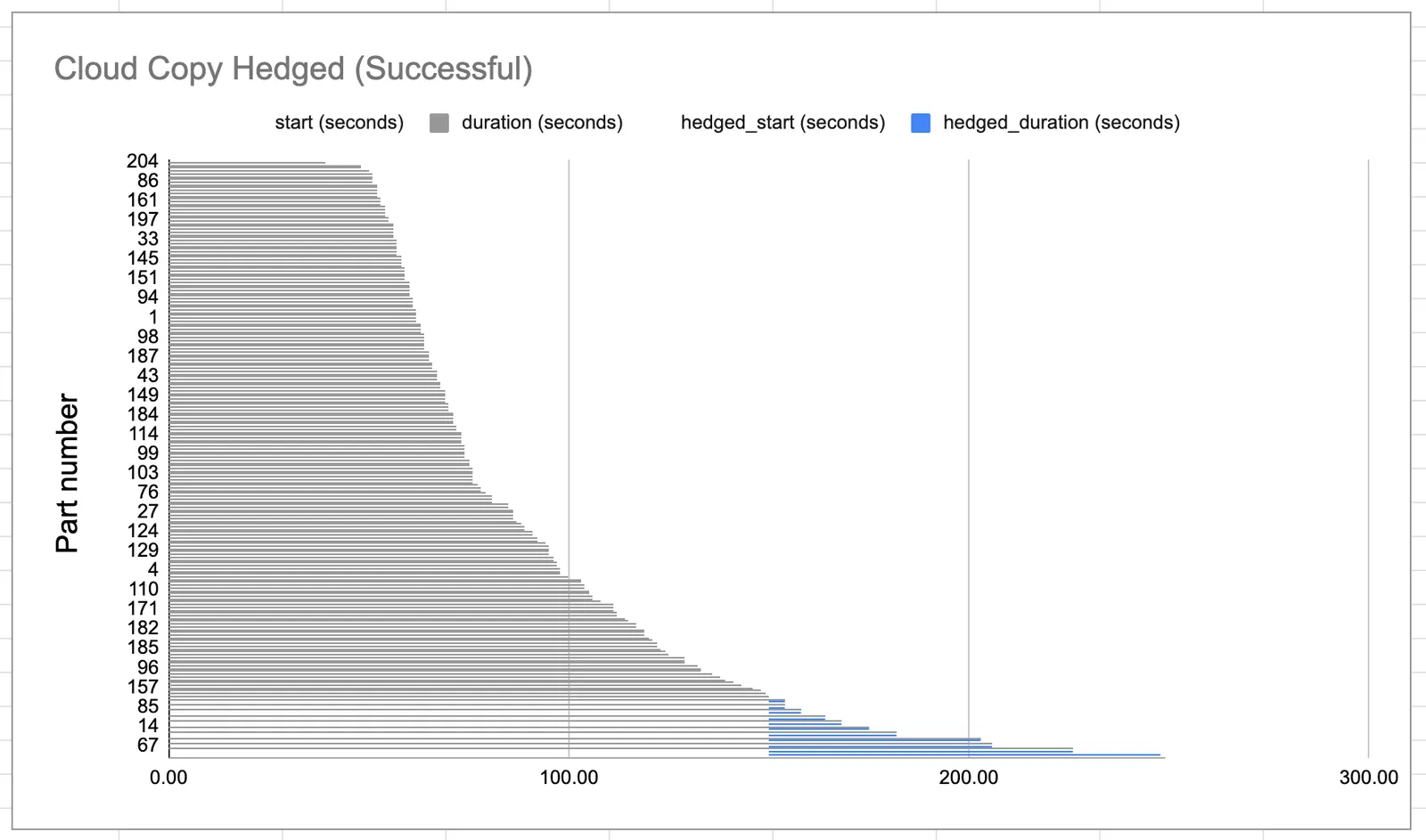
The lines marked in blue represent the durations of the requests that were hedged. While only 11 requests, or roughly 5%, of our requests were hedged, it was enough to get fork working. We could now clone a 1TB database in under 5 minutes!
Conclusion#
In the future, it might be necessary to implement a copy-on-write strategy for these table files. As the sizes of the databases on DoltHub increase, it may not be reasonable to ask the user to wait for 10 or 15 minutes before using their fork. A copy-on-write strategy wouldn’t duplicate the table files immediately, but instead defer the work for a later time. The forked database would instead refer to the table files of the old database. If a write occurs to the new or old database, then the table files would be copied at that point in time. We could potentially even copy these table files in the background to make this delay completely transparent to the user.
As we continue to scale DoltHub, we’re going to encounter more of these tail latency issues both in third party services like S3 and in our own systems. In these cases, we can use request hedging to mitigate the issue.
If you’re interested in hearing more about Dolt databases and DoltHub, come talk to us on Discord! We’re excited to meet you.