
Dolt is a SQL database that you can clone, fork, branch, and merge. In previous posts we’ve discussed the implementation of joins with primitives such as join planning and index accesses. We’ve taken another step in join compatibility by implementing the MySQL Update Join query. In this blog post we’ll cover how we designed/implemented this new piece of functionality and connect it back to versioning.
Desired Functionality#
Update queries change a set of a rows based on a specific set of conditions. In the case of an UPDATE JOIN we are extending the set of conditions to include a join condition that can affect multiple tables. The easiest way to explain is through an example.
Suppose we had some sales and a salesman. We want to update the salesman salary based on whether they achieved a large enough deal size.
uj> select * from salesman;
+----------+--------+
| name | salary |
+----------+--------+
| jane doe | 100000 |
| john doe | 100000 |
+----------+--------+
uj> select * from sales;
+---------+----------+-----------+
| sale_id | salesman | deal_size |
+---------+----------+-----------+
| 1 | john doe | 1000 |
| 2 | john doe | 2000 |
| 3 | jane doe | 1200 |
+---------+----------+-----------+
uj> update salesman inner join sales on salesman.name = sales.salesman set salary = salary * 1.1 where deal_size > 500;
Query OK, 1 row affected
Rows matched: 1 Changed: 1 Warnings: 0
uj> select * from salesman;
+----------+--------+
| name | salary |
+----------+--------+
| jane doe | 110000 |
| john doe | 110000 |
+----------+--------+
uj> select dolt_commit('-a', '-m', "salary update part 1")However, there are a few pieces of complexity that we need to consider.
- Each matching row is updated once, even if it matches the condition multiple times. Let’s consider a different query where we scale the salary by the deal size.
uj> select * from salesman;
+----------+--------+
| name | salary |
+----------+--------+
| jane doe | 100000 |
| john doe | 100000 |
+----------+--------+
uj> select * from sales;
+---------+----------+-----------+
| sale_id | salesman | deal_size |
+---------+----------+-----------+
| 1 | john doe | 1000 |
| 2 | john doe | 2000 |
| 3 | jane doe | 1200 |
+---------+----------+-----------+
uj> update salesman inner join sales on salesman.name = sales.salesman set salary = salary + deal_size;
Query OK, 2 rows affected
Rows matched: 2 Changed: 2 Warnings: 0
uj> select * from salesman;
+----------+--------+
| name | salary |
+----------+--------+
| jane doe | 101200 |
| john doe | 101000 |
+----------+--------+Note how even though there are multiple matches between salesman.name and sales.salesman, salesman.salary takes on the
first salesman.deal_size it is matched with.
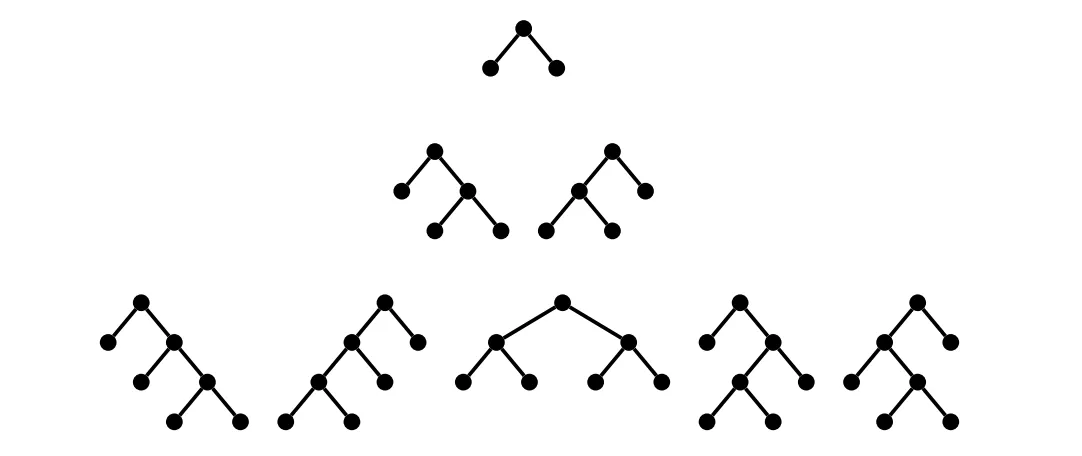
- Joins need to be performant (i.e use join planning) while maintaining the correct update order
In large scale joins (i.e n > 2) our planner searches and constructs a join tree that may be different than the original join plan given by the user. This can result in a join row that is a different structure than the update expressions are configured to work in. We need to ensure that once the join row is computed, it is transformed back into its original order. The below image depicts different joins orders given the tree size.
- Updates can span multiple tables in one transaction.
Any error in an update must subsequently call a rollback that resets the state of all tables affected in the update query.
Design and Implementation#
Let’s start by first thinking through how a normal UPDATE works in go-mysql-server. From this previous blog post, we know that go-mysql-server executes the following steps on a query.
- Parses it into an Abstract Syntax Tree (AST)
- Transforms each node of the AST into a GMS
Node.Nodesare a go-mysql-server data structure that knows how to return rows for the part of the query plan it represents. - Analyze each node of the tree to resolve tables, columns, and plan our join.
uj> explain update salesman set salesman.salary = salesman.salary * 1.1 where name='john doe';
+-----------------------------------------------------------------+
| plan |
+-----------------------------------------------------------------+
| Update |
| └─ UpdateSource(SET salesman.salary = (salesman.salary * 1.1)) |
| └─ Filter(salesman.name = "john doe") |
| └─ IndexedTableAccess(salesman on [salesman.name]) |
+-----------------------------------------------------------------+The primary action of this plan is to take a row from a table, evaluate the update condition, and push the (old row, new row) pair to a table editor to process.
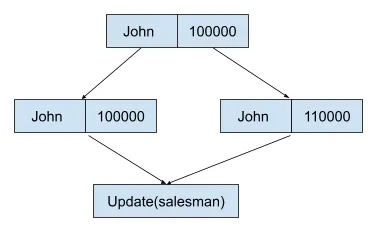
Now let’s design what we want an UPDATE JOIN query plan to look like. Broadly, we want the following steps to occur:
- Evaluate and create a join row
- Reorder the join row to match the original join order
- Run the update expressions on the join row. Return the old join row, new join row pair.
- For each table level row encoded in the join row, check whether the table level-row was already updated.
- Convert the old join row, new join row pair into a sequences of updates for multiple tables and execute the table-level update operation.
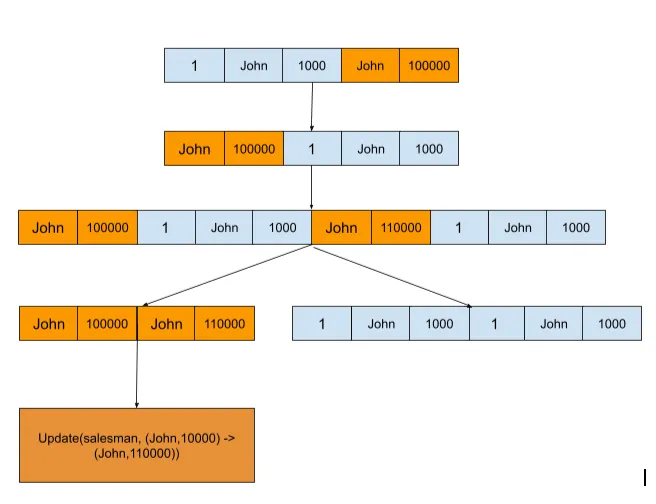
Here’s a diagram to explain this:
Sample Code#
Below is some sample code that highlights the core behavior of UPDATE JOIN. We first split the old join row, new join row pair into a map of tables (the tables involved in the join) to their rows. We then take each table level old row and check with a cache to see if the table was already updated before. In the case that a row was already updated we undo the update operation performed on it by re-encoding it with its original data.
oldJoinRow, newJoinRow := oldAndNewRow[:len(oldAndNewRow)/2], oldAndNewRow[len(oldAndNewRow)/2:]
tableToOldRowMap := splitRowIntoTableRowMap(oldJoinRow, joinSchema)
tableToNewRowMap := splitRowIntoTableRowMap(newJoinRow, joinSchema)
for tableName, _ := range tablesToUpdate {
oldTableRow := tableToOldRowMap[tableName]
// Determine whether this row in the table has already been update
cache := getOrCreateCache(ctx, tableName)
hash, err := sql.HashOf(oldTableRow)
if err != nil {
return nil, err
}
_, err = cache.Get(hash)
if errors.Is(err, sql.ErrKeyNotFound) {
cache.Put(hash, struct{}{})
continue
} else if err != nil {
return nil, err
}
// Encode the new row with the old information to ensure that an additional update isn't done.
tableToNewRowMap[tableName] = oldTableRow
}
newJoinRow = recreateRowFromMap(tableToNewRowMap, joinSchema)
equals, err := oldJoinRow.Equals(newJoinRow, joinSchema)
if err != nil {
return nil, err
}
if !equals {
return append(oldJoinRow, newJoinRow...), nil
}Once we’ve established that this oldJoinRow, newJoinRow pair is a valid pair that we want to update, we go through the process of actually updating each table.
tableToOldRowMap := splitRowIntoTableRowMap(old, u.joinSchema)
tableToNewRowMap := splitRowIntoTableRowMap(new, u.joinSchema)
for tableName, updater := range u.tablesToupdate {
oldRow := tableToOldRowMap[tableName]
newRow := tableToNewRowMap[tableName]
schema := u.schemaMap[tableName]
eq, err := oldRow.Equals(newRow, schema)
if err != nil {
return err
}
if !eq {
err = updater.Update(ctx, oldRow, newRow)
}
if err != nil {
return err
}
}
return nilVersioning#
Update Join queries are extremely useful for getting more out of Dolt’s versioning properties. The clearest example of
this is updating data to that of a previous commit using the as of syntax.
Let’s use the data above and consider the following scenario. There’s been several salary increases over the years for the salesman.
commit cb7vlbm5c53jieultde9ifva2v4ajlkn
Author: Vinai Rachakonda <vinai@dolthub.com>
Date: Wed Nov 10 11:47:07 -0800 2021
salary updates part 3
commit mkh9vi75f4q858mn0gqpso1qb37npav2
Author: Vinai Rachakonda <vinai@dolthub.com>
Date: Wed Nov 10 11:47:00 -0800 2021
salary updates part 2
commit j9tj0p3md89gti73i5er2bj2i1m70tm4
Author: Vinai Rachakonda <vinai@dolthub.com>
Date: Wed Nov 10 11:43:12 -0800 2021
salary updates part 1
commit 5sh8rgoroch6vk6r7atteea7d4cbf484
Author: Vinai Rachakonda <vinai@dolthub.com>
Date: Tue Nov 09 12:18:23 -0800 2021
Initialize data repositoryThe current salaries are now:
uj> select * from salesman;
+----------+--------+
| name | salary |
+----------+--------+
| jane doe | 122452 |
| john doe | 122210 |
+----------+--------+However, there’s recently been a significant drops in sales, and we need to cut down on salaries to part 1 levels for all existing salesman. We can write the following query:
uj> update salesman inner join (select * from salesman as of 'j9tj0p3md89gti73i5er2bj2i1m70tm4') as t2 on salesman.name = t2.name set salesman.salary = t2.salary;
Query OK, 2 rows affected
Rows matched: 2 Changed: 2 Warnings: 0
uj> select * from salesman;
+----------+--------+
| name | salary |
+----------+--------+
| jane doe | 101200 |
| john doe | 101000 |
+----------+--------+Finally, we can commit it by saying dolt commit -a -m "resetting salaries to part 1"
Additional Considerations#
The current limitation with this solution is a lack of support for keyless tables. This is because two rows with the same values in a keyless table would contain the same hash of their values. That means that we unintentionally skip a potential update that we should be making. The correct solution for this dilemma is to implement row level identifiers at the Dolt storage layer. That’s a hefty project that we will save for another time.
Conclusion#
In this blog we’ve discussed the design and implementation of one of the more complex MySQL queries. We see that complex join queries can translate into easier use of dolt versioning features. Soon we will support DELETE JOIN, REPLACE JOIN that will not only make it easier to build on top of versioning but also on top of Dolt’s system tables.