
When we began working on Dolt in 2018 we leveraged Noms, an open source project that gave us efficient diff and merge capabilities. The company that had built Noms, Attic Labs, pitched it to developers as a decentralized application database. Noms is a schemaless graph database, Dolt stores data as schema’d tables. In this blog I’ll talk about how the differences between our use cases allows us to strip out features that Noms relies on in order to improve performance.
Noms Type System#
Because of Noms’ schemaless design, Attic Labs built a type system that allows you to inspect the type of each element in the prolly tree. In Noms every element has both a “kind”, and a “type”. A “kind” is the basic type of an element, whereas a “type” includes more detailed information. For primitives such as strings, the “kind” and the “type” are equivalent. For composite types such as a list the “kind” is list, but the “type” will depend on what the elements of the list are. The type could be a list of strings, but it could also be a list of a mix of things including elements that have complex types themselves.
Representing Tables in Dolt#
Table data in Dolt is stored in a Noms map. The key for each entry in the map is the tuple of primary key columns, and the value is the tuple of the remaining columns. Tuples were not part of the original Noms implementation, but were mostly copied from the struct implementation without the need for field names. Tuples, like structs, have a complex Noms “type” which are dependent on their components. Because the table is a map with a composite type based on the composite types of the key and value tuples for all the rows, it is extremely complicated.
Types Showing up in Benchmarks#
Time and time again, while investigating performance issues, the Noms typing system would show up in our profiles. It had the greatest cost during write operations when it would compute the type of each table map, but it would also show up on the read path. While it was an important feature for Noms, it allocated a lot of memory, and it was too costly for something we didn’t need for our use case.
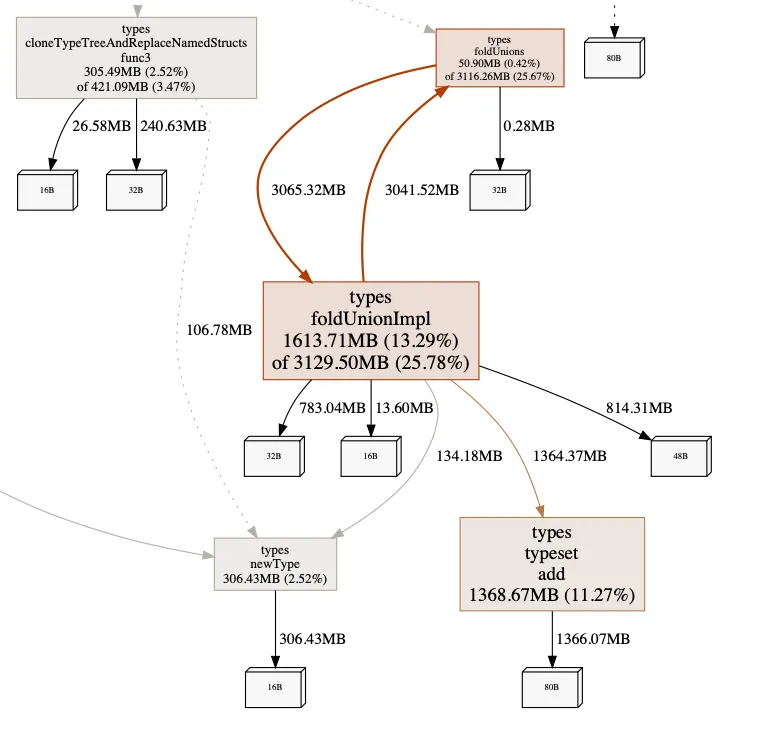
Impact of Making Tuples Primititve Types#
The first change made to Dolt was to make tuples act like primitive types. They no longer store complex type information based on the types of their elements. The change is backwards compatible, and has a significant impact on our sysbench write tests (the oltp_delete test in particular).
Sysbench Test Before After Improvement
oltp_delete 9.73 2.76 252.5%
oltp_insert 12.52 9.91 26.3%
oltp_read_write 73.13 64.47 13.4%
oltp_update_index 14.21 11.65 22.0%
oltp_write_only 40.37 33.72 19.7%Conclusion#
Dolt was built using Noms which was tremendously beneficial in getting our product to market. That said, Dolt and Noms have significantly different use cases, and benefit from different features. The Noms type system is a great example of this. Because we have schema’d data it isn’t necessary, and we are able to improve performance by removing it from tuples.
Improving performance is a priority for us at the moment, and we’ve made significant progress improving it over the last 6 months. We benchmark Dolt using sysbench and publish how our performance compares against MySQL here. When we started tracking these metrics, Dolt was 22x slower than MySQL on writes. Now we are just over 8x, and we will continue to drive toward performance parity. Dolt will always be slower than MySQL because our feature sets are different, and we made tradeoffs in order to support diffs, and merges. Our goal is to be between 2x to 4x slower, and 100% correct.