Dolt and Data Science - A Simple Example

Dolt is Git for data, a SQL database with version control.
We've been working hard recently on making Dolt a useful tool for Data Science (DS) practitioners and we're hoping to launch some slick integrations soon. But first, we wanted to start off the Dolt + DS series with a simple example to show you how you can kick off your DS project with Dolt.
The Data
The data that we're going to work with today is the IMDB reviews sentiments dataset. Each movie review review is mapped to a sentiment. A sentiment is either
positive (1) or negative (0). Our goal is to predict the sentiment of a given movie review.
Go ahead and clone the data from here. The first thing we'll do is split the data into test and train sets. For convenience that data we provide already has this split, but we'll walk you through how to do it anyway.

Doltpy + SKLearn
We're going to use Doltpy to load and read the data into a pandas dataframe.
from doltpy.core import Dolt
from doltpy.core.read import read_table
# Load in the repo and read the relevant tables.
repo = Dolt('.') # replace with path to repo.
df_train = read_table_sql(repo, 'SELECT review,sentiment FROM reviews WHERE is_test=0')
df_test = read_table_sql(repo, 'SELECT review,sentiment FROM reviews WHERE is_test=1')
# Split the train and test into matrices and labels.
train_reviews = df_train['review']
train_labels = df_train['sentiment']
test_reviews = df_test['review']
test_labels = df_test['sentiment']
Let's now build our model. We took inspiration from this article to help us craft our model.
import re
# Replace the new line markers in the reviews with spaces
train_reviews.map(lambda txt: re.sub('(<br\s*/?>)+', ' ', txt))
test_reviews.map(lambda txt: re.sub('(<br\s*/?>)+', ' ', txt))We use a bigram representation of the reviews. The linked article goes more in depth about the model choice.
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
from nltk.corpus import stopwords
def bigram(reviews):
bigram_vectorizer = CountVectorizer(ngram_range=(1, 2), stop_words=stopwords.words('english'))
bigram_vectorizer.fit(reviews)
return bigram_vectorizer
bv = bigram(train_reviews)
train_bigram, test_bigram = bv.transform(train_reviews), bv.transform(test_reviews)Now lets train our classifier and use RandomizedSearchCV to get our tuned hyperparameters.
from sklearn.linear_model import SGDClassifier
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import uniform
# Get tuned model on training data
def get_tuned_model(reviews, labels):
clf = SGDClassifier()
distributions = dict(
penalty=['l1', 'l2', 'elasticnet'],
alpha=uniform(loc=1e-6, scale=1e-4)
)
random_search_cv = RandomizedSearchCV(
estimator=clf,
param_distributions=distributions,
cv=2,
n_iter=1
)
random_search_cv.fit(reviews, labels)
return random_search_cv.best_estimator_
clf = get_tuned_model(train_bigram, train_labels)Finally we can compute our predictions and write them to a table for us to review.
import pandas as pd
from doltpy.core.write import import_df
# Get the model accuracy on training and test. Push the prediction to the sample repo.
# Compute training accuracy and push predictions to a table
def accuracy(clf, reviews, labels, title):
predictions = clf.predict(reviews)
score = clf.score(reviews, labels)
print(f'{title}\n score: {round(score, 2)}')
return predictions
def push_prediction_to_table(reviews, labels, predictions, table_name):
predictions = pd.Series(predictions).rename('predictions')
result = pd.concat([reviews, labels, predictions], axis=1)
import_df(repo=repo, table_name=table_name, data=result, primary_keys=['review'])
predictions_train = accuracy(clf, train_bigram, train_labels, "TRAIN")
push_prediction_to_table(train_reviews, train_labels, predictions_train, "results_train")
predictions_test = accuracy(clf, test_bigram, test_labels, "TEST")
push_prediction_to_table(test_reviews, test_labels, predictions_test, "results_test")We got a train accuracy 100% (overfitting) and a test accuracy of 89%.
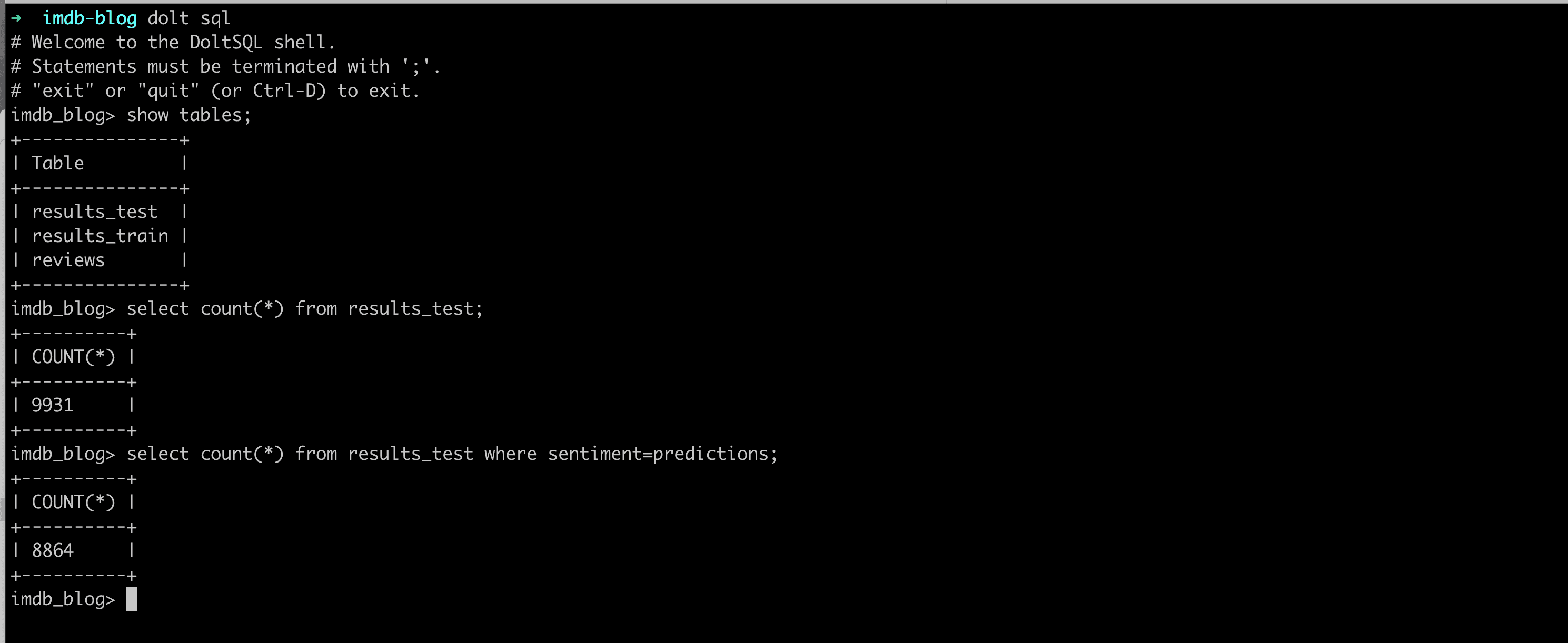
Awesome! We just used a dolt database to read data into our model and then write results back. Now what happens when your data changes?
Branching your database
When you get updated data you want to experiment with new models as fast as possible. With code, this type of experimentation is easy. You can simply create a new branch in your git repo. But with data, it becomes a huge pain to create an experimental dataset from an existing datastore. Dolt branching brings git like experimentation to your data so you can try out new models quickly. Let's see how it works:
Our model is working well, but we just received about 10,000 new data points. This time these movie reviews are from Rotten Tomatoes. We even have a new label, 2, that represents
a neutral sentiment. We can view this data in separate branch called rotten-tomatoes. You can check it out in the repo here.
Working with a new branch in dolt is super easy. In doltpy we can edit our first couple lines of code to this:
from doltpy.core import Dolt
from doltpy.core.read import read_table
# Load in the repo and read the relevant tables.
repo = Dolt('.')
repo.checkout('rotten-tomatoes', checkout_branch=False)Now we can rerun our model and see our results. We got a train accuracy 100% (overfitting) and a test accuracy of 83%. Our model architecture definitely needs more work on this new data. When we're ready with our model, we can merge our new branch back into master.
Data Versioning to the Rescue
Just like how DS code is collaborative, Dolt is collaborative too. So if someone pushes a bug in code, the same person can also push a bug in your data. Dolt's built in commit log and diff capabilities make it extremely easy to track down failure points in your dataops processes. Let's walk through an example.
You just reran your model on the rotten-tomatoes branch and you notice that your results are totally different than they were before. We can look through
a commit log and use a dolt diff --summary to get a sense of the data changes.
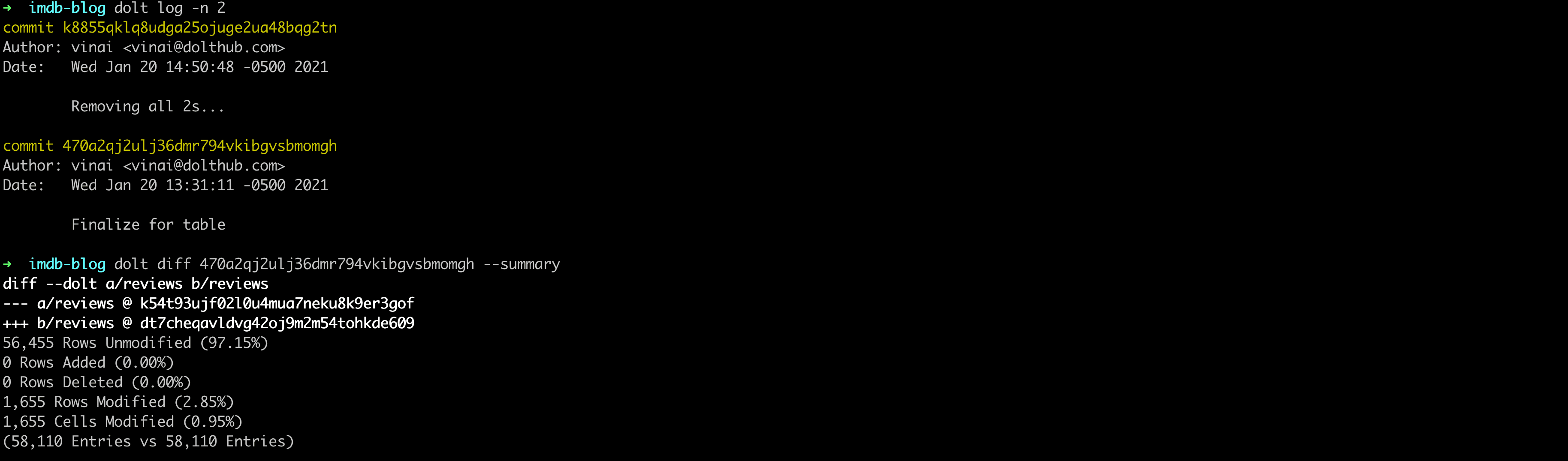
Looks like between commit 470a2qj2ulj36dmr794vkibgvsbmomgh and k8855qklq8udga25ojuge2ua48bqg2tn a pretty sizeable change occurred.
Let's get more granular with our diff.
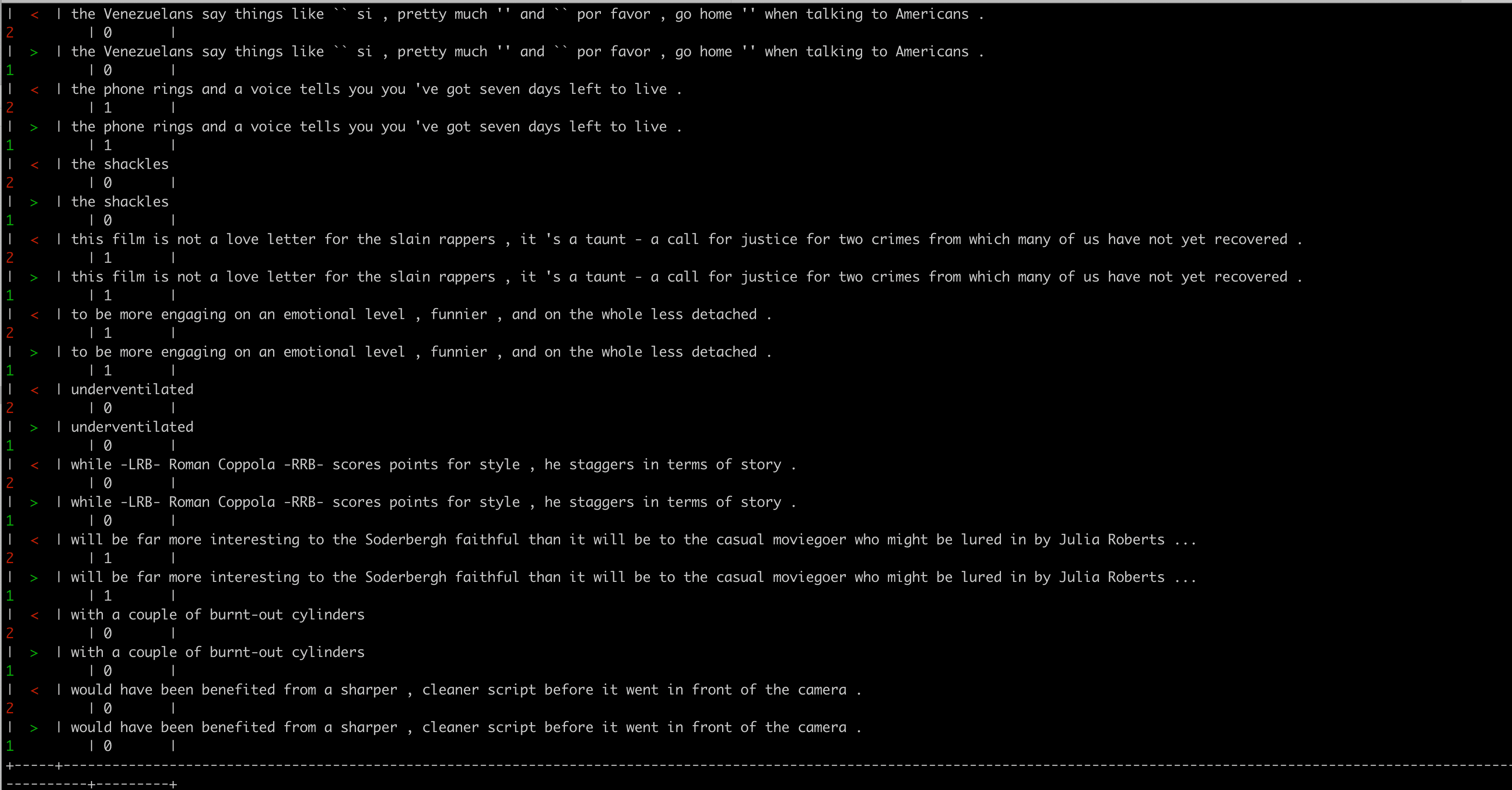
Look at that! Looks like your teammate just changed all the 2s in your datasets to 1s! They didn't get the memo that there's a new label 2 that represents a neutral sentiment. We can reset this behavior pretty easily.
$ dolt checkout -b restore 470a2qj2ulj36dmr794vkibgvsbmomgh # create a branch named restore at the commit
$ dolt branch -d -f rotten-tomatoes # delete the original branch
$ dolt branch -m restore rotten-tomatoes # change the restore branch name to rotten-tomatoesIf we look at our log with dolt log we'll notice our commit log is all clean.
Conclusion
Dolt is an enterprise level data store that adds easy data versioning and experimentation capabilities to your existing data science workflow. It is the only datastore tool that can move as fast as your code does. We showed a pretty simple example above, but here's a sneak peek to what we'll be releasing in the future.
- Integrations with other Machine Learning (ML) Pipeline Version Tools
- More tutorials on building your DS/ML projects with Dolt
- Awesome datasets you can train your model on
If you want to learn more about Dolt and how it can work in your workflow, join our Discord server here.